生成AIを社内データに学習させない設定|CopilotとClaude時代の権限管理
社内データをAIに触らせる範囲を先に決めておくと、便利さと安全性は両立しやすくなります。
CopilotやClaudeを止めずに守る順番、気になりませんか?
生成AIを会社で使わせるとき、最初に不安になるのは「社内データが学習に使われないか」です。ところが実務では、この不安を「学習させない設定」だけで片付けると、別のところに穴が残ります。
たとえばMicrosoft 365 Copilotでは、プロンプトや回答、Microsoft Graph経由のデータは基盤モデルの学習に使われないと説明されています。ただし、Copilotは利用者が閲覧権限を持つ社内データを回答に使える設計です。つまり「学習しない」と「回答に出ない」は別の話として見てください。
出典: Microsoft Learn「Data, Privacy, and Security for Microsoft 365 Copilot」(英語)
この記事では、Copilot、Claude、ChatGPTなどを社内利用するときに、社内データを学習させないための見方と、権限管理・履歴保持・検索範囲・コネクタ管理まで含めた実務手順を整理します。
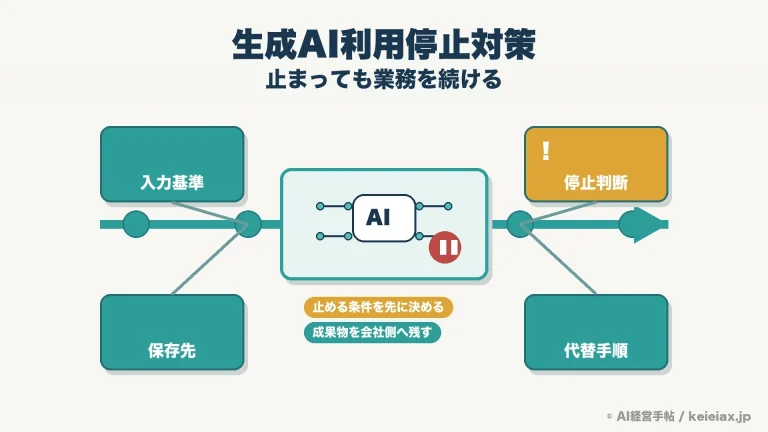
生成AIに社内データを学習させない設定は1つのスイッチではない
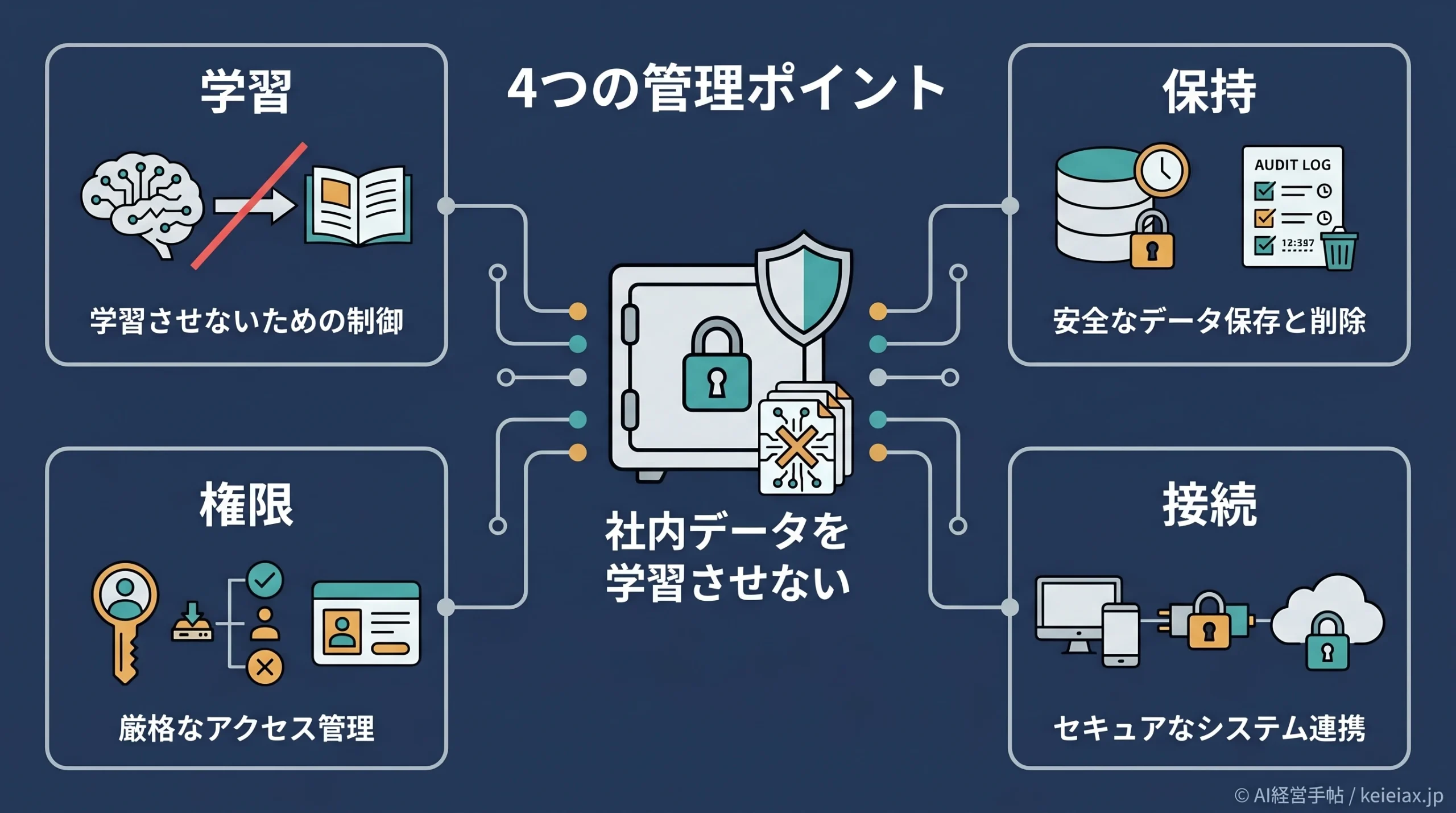
生成AIの安全設定を考えるときは、まず「何を防ぎたいのか」を分けるところが出発点です。社内データをAIに一切触れさせたくないのか、基盤モデルの学習に使わせたくないのか、権限のない社員に見せたくないのかで、見るべき設定が変わります。
要点最初に分ける4つの論点
社内データのAI利用は、学習利用、履歴保持、検索範囲、権限と接続先を分けて確認します。どれか1つを設定しても、他の論点が未整理なら「社内データが安全に管理されている」とは言い切れません。
特に見落とされやすいのは、ファイル共有の権限です。生成AIサービス側で学習利用を止めていても、社内の共有フォルダが広すぎると、AIは「その人が見られるデータ」として機密資料を拾う可能性があります。AIの設定だけでなく、社内データの権限棚卸しを先に済ませましょう。
まず分けるべき4つの論点
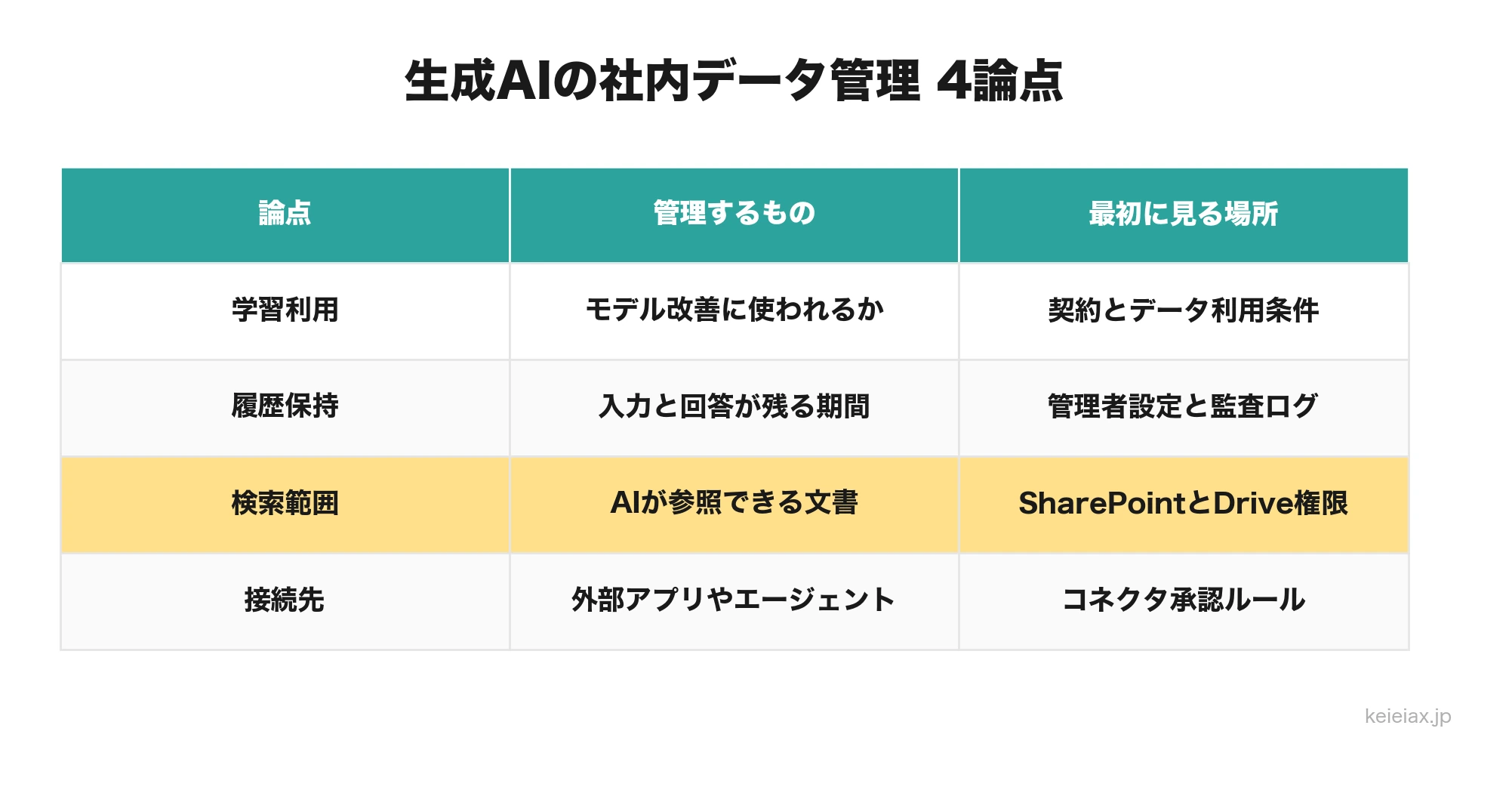
社内向けのAI管理では、次の4つを別々に確認しましょう。この切り分けをしておくと、ツールごとの仕様変更があっても、確認漏れを減らせます。
| 論点 | 確認する場所 | 判断の目安 |
|---|---|---|
| 学習利用 | 契約、管理画面、データ利用ポリシー | プロンプトやファイルがモデル改善に使われるか |
| 履歴保持 | 管理者設定、監査ログ、サービス仕様 | 入力内容や回答がどの期間残るか |
| 検索範囲 | Microsoft 365、Google Drive、社内検索の権限 | AIが参照できる社内文書の範囲は適切か |
| 接続先 | コネクタ、エージェント、外部アプリ連携 | メール、CRM、ストレージなどに勝手につながらないか |
「社内データを学習させない設定」という言葉だけを見ると、管理画面のオンオフを探したくなるはずです。しかし、実際には契約種別、保持期間、検索対象、既存の閲覧権限が組み合わさってリスクが決まります。
この考え方は、社内ルール作成にもそのまま使えます。許可ツールだけを並べるのではなく、どのデータを入れてよいか、どの接続を承認制にするかまで決めると、現場が迷いにくいルールになります。ルール全体の作り方は、生成AIの社内利用ガイドラインの作り方も参考にしてください。
Copilotで最初に見る権限管理
Microsoft 365 Copilotを使う会社では、最初にSharePoint、OneDrive、Teamsの権限を確認しましょう。CopilotはMicrosoft Graphを通じて、利用者がアクセスできるコンテンツを使って回答する仕組みです。基盤モデルの学習に使われないことと、回答生成時に参照されることは分けて考えます。
対策の出発点は、AI管理画面ではなく「社員が今見られるファイル」です。全社共有フォルダ、退職者が作った古い共有リンク、部門をまたいだTeamsチャネル、経営資料が混ざったSharePointサイトを優先的に棚卸しします。
注意Copilotは権限の粗さをそのまま映す
Copilotが新しい機密情報を作り出すというより、既存の閲覧権限が広すぎる状態を目立たせる側面があります。導入前後で「誰が何を見られるか」を見直さないと、AI導入後に問題が発覚しやすくなる点に注意してください。
SharePointにはRestricted SharePoint Searchという機能も用意されています。これはCopilotと検索で参照されるSharePointサイトを限定するための仕組みですが、Microsoftは短期的な制御として位置づけています。サイト数の上限もあるため、長期運用では権限そのものの整理を優先してください。
出典: Microsoft Learn「Restricted SharePoint Search」(英語)
さらに、Microsoft PurviewではAI利用時のリスク管理、秘密度ラベル、DLP、監査などを組み合わせて使う選択肢があります。AI専用の新しい仕組みをゼロから作るより、既存の情報保護ルールにAI利用を乗せる方が、続きやすい運用です。
出典: Microsoft Learn「AI protections in Microsoft Purview」(英語)
社内文書をAIで横断検索する場合の考え方は、社内文書をAIで横断検索する仕組みの作り方も参考にしてください。検索精度より先に、検索してよい範囲を決めることが大切です。
ClaudeやChatGPTで確認する契約・保持・接続先
ClaudeやChatGPTを社内で使う場合も、製品名だけで安全性を判断しないでください。同じブランド名でも、個人向け、チーム向け、エンタープライズ、API利用では、データの扱い、保持期間、管理者機能が異なるためです。
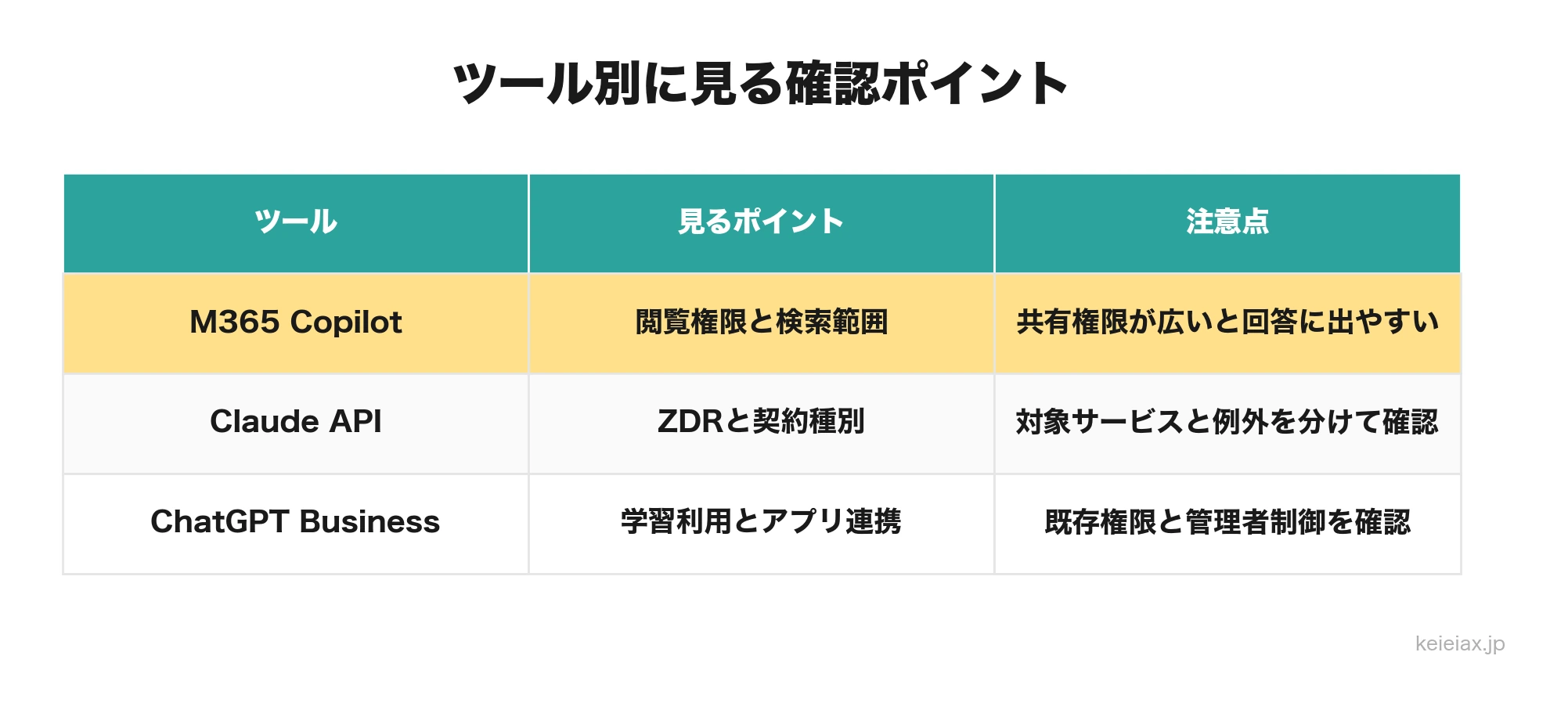
AnthropicのAPIドキュメントでは、Zero Data Retentionの対象や例外、保持されるデータは明示的な許可なしに学習に使わないことが説明されています。ただし、対象サービスやモデルには条件があるため、「Claudeなら全部残らない」とは言えません。
出典: Anthropic Docs「API and data retention」(英語)
Microsoft 365 Copilotの中でAnthropicモデルを使う場合も、確認が必要です。MicrosoftはAnthropicをサブプロセッサとして説明し、地域やモデル、プレビュー条件によって利用可否や保持の扱いが変わることを案内しています。
出典: Microsoft Learn「Connect to AI subprocessor for Microsoft 365 Copilot」(英語)
OpenAIも、ChatGPT Business、ChatGPT Enterprise、API Platformなどのビジネス向けサービスでは、ビジネスデータを既定で学習に使わないという説明です。さらに、連携アプリは管理者の制御と既存権限に従う設計です。ここでも「学習しない」と「連携先のデータを読める」は分けて確認してください。
出典: OpenAI「Enterprise privacy at OpenAI」(英語)
複数AIを使い分ける会社では、用途別に許可ツールを分けると運用しやすくなります。文書要約はCopilot、汎用相談はChatGPT Business、API連携はClaude APIのように、業務とデータ種別を対応させる形です。ツール選定の基本は、生成AIは会社でどれを選ぶべきかを参照してください。
社内ルールに落とすチェックリスト
設定を確認したら、次は社内ルールに落としましょう。AIツールの管理者だけが理解していても、現場が入力してよい情報を判断できなければ事故は防げません。
- 許可するAIツールと、禁止する個人アカウント利用を明記する
- 入力禁止データを、顧客情報、未公開財務情報、人事情報、契約書など具体名で書く
- Copilotなど社内検索型AIの導入前に、共有フォルダとサイト権限を棚卸しする
- 外部アプリ、コネクタ、エージェントの追加は管理者承認制にする
- 履歴保持、監査ログ、削除依頼の担当者を決める
- 例外利用の申請先と判断基準を決める
社内ルールは長い規程にするより、最初は「許可ツール」「入れてよい情報」「入れてはいけない情報」「相談先」の4点に絞る方が浸透します。既存ルールの点検には、生成AI利用ルール診断の観点を使ってください。
メモルールはツール名だけで終わらせない
「ChatGPTは禁止」「Copilotは許可」のような書き方だけでは不十分です。個人版と法人版、Web画面とAPI、社内データ接続の有無まで分けないと、現場で誤解が起きます。
30日で進める実装順
中小企業でいきなり全社の権限設計を完璧にするのは現実的ではありません。まずは30日で、危ない入口から順番に閉じていく方が進めやすいです。

- 1週目: 利用中のAIツール、個人アカウント利用、API連携を一覧化する
- 2週目: SharePoint、OneDrive、Google Drive、Teamsなどの共有範囲を確認する
- 3週目: 許可ツール、禁止データ、承認が必要な接続先を社内ルールにする
- 4週目: 管理者設定、監査ログ、例外申請の運用を確認し、現場向けに短い説明資料を出す
この順番で進めると、まずシャドーAIと広すぎる共有権限を見つけやすくなります。AIツールの細かい設定はその後でも間に合うことが多いです。社内データを完全に外に出せない用途では、ローカルLLMは中小企業に必要かのように、クラウドAIとの切り分けも検討してください。
よくある失敗
社内データを学習させない運用でよくある失敗は、設定そのものよりも、前提の置き方にあります。
警告「学習オフ」だけで安心しない
学習利用を止めても、履歴保持、検索範囲、共有権限、外部コネクタが残ります。特にCopilotのような社内データ接続型AIでは、AI設定よりも先に既存権限の整理が必要です。
次のような状態がある場合は、導入前に止めて見直してください。
- 個人版AIの利用を放置したまま、法人AIだけを契約している
- 全社共有フォルダに、経営資料や人事資料が混在している
- 外部アプリ連携やエージェント作成の承認ルールがない
- 「AIに入れてはいけない情報」が抽象的で、現場が判断できない
- ツールの仕様変更を確認する担当者が決まっていない
逆に、最初から全ツールを禁止すると、社員が個人アカウントに流れることがあります。禁止だけでなく、安全に使える入口を用意することが、結果的に社内データを守る近道です。
まとめ: 生成AIの社内データ設定は権限管理から始める
生成AIの社内データ設定とは、学習利用、保持、検索範囲、権限、接続先を分けて管理する運用設計です。学習に使われない設定だけを見ても、社内データが回答に出る可能性や、履歴に残る可能性までは判断できません。
最初にやるべきことは、利用ツールの棚卸しと、社内ファイルの権限整理です。そのうえで、法人向けサービスのデータ利用条件、履歴保持、管理者機能、コネクタ承認を確認しましょう。AIを止めるのではなく、AIが触れてよい社内データの範囲を決めることが、実務的な安全策です。
FAQ
Q生成AIを社内データに学習させない設定は何から始めるべきですか?
Aまず、利用中のAIツールと契約種別を一覧化し、法人向けのデータ利用条件、履歴保持、管理者設定を確認します。その後、社内ファイルの閲覧権限と外部コネクタの承認ルールを整えます。
QMicrosoft 365 Copilotは社内データを学習に使いますか?
AMicrosoftは、Copilotのプロンプト、回答、Microsoft Graph経由のデータは基盤モデルの学習に使われないと説明しています。ただし、Copilotは利用者が閲覧権限を持つ社内データを回答生成に使えるため、権限管理は別途必要です。
QCopilotで見せたくないファイルはどう管理しますか?
ASharePoint、OneDrive、Teamsの閲覧権限を見直し、不要な全社共有や古い共有リンクを削除します。短期的には検索範囲の制御も使えますが、長期的にはファイル権限そのものを整理する必要があります。
QClaude APIのZDRなら全サービスで履歴が残りませんか?
Aいいえ。AnthropicのZero Data Retentionには対象範囲と例外があります。Claudeの個人向け利用、チーム向け利用、API利用、特定モデルの扱いは分けて確認してください。
QChatGPT EnterpriseやBusinessなら社内データは学習に使われませんか?
AOpenAIは、ビジネス向けサービスのビジネスデータを既定で学習に使わないと説明しています。ただし、アプリ連携や社内データ接続は管理者設定と既存権限に従うため、連携先の確認が必要です。
Q中小企業で最初に作る社内ルールは何ですか?
A最初は、許可するAIツール、入力禁止データ、外部連携の承認方法、相談先の4点を決めます。長い規程よりも、現場が迷ったときに判断できる短いルールを先に作る方が定着しやすいです。