ハルシネーションを起こすプロンプトの典型パターン|避けるべき書き方と改善例
同じAIに同じことを聞いても、書き方を少し変えるだけで嘘や捏造の出方は大きく変わります。
すぐ真似できる書き換えのコツから、お伝えしますね。
生成AIに業務上の質問を投げて、堂々と嘘や捏造を返された経験は、おそらく一度や二度ではないはずです。
多くの場合、AIモデルの不具合ではなく、質問の書き方そのものが誤回答を引き出しているのが原因になっています。本記事では、ハルシネーション(嘘や捏造)を誘発する典型的なプロンプトの書き方を6パターン整理し、危険なプロンプトを安全なプロンプトに書き換える具体的な手順、そして書き方を改善しても残るリスクの人間側運用までを通しで取り上げる構成です。
ハルシネーションは「AIの不具合」ではなく、質問の書き方で増減する
ハルシネーションとは(最小定義)
ハルシネーション(幻覚)とは、生成AIが事実と異なる情報や存在しない事柄を、もっともらしい自然な文章で出力してしまう現象のことを指します。
ChatGPTやClaude、Geminiといった主要ツールの公式解説でも、定義はほぼ同じ言葉で揃っており、最新モデルでも構造的に避けられない現象として扱われています。
厄介なのは、誤回答が文章としては自然で説得力がある点です。専門外の読者ほど捏造を見抜けず、そのまま社内資料や顧客向け文書に混入してしまう業務上の実害に直結します。
なぜ起きるのか:AIは「分からない」より「それらしい推測」を選ぶよう訓練されている
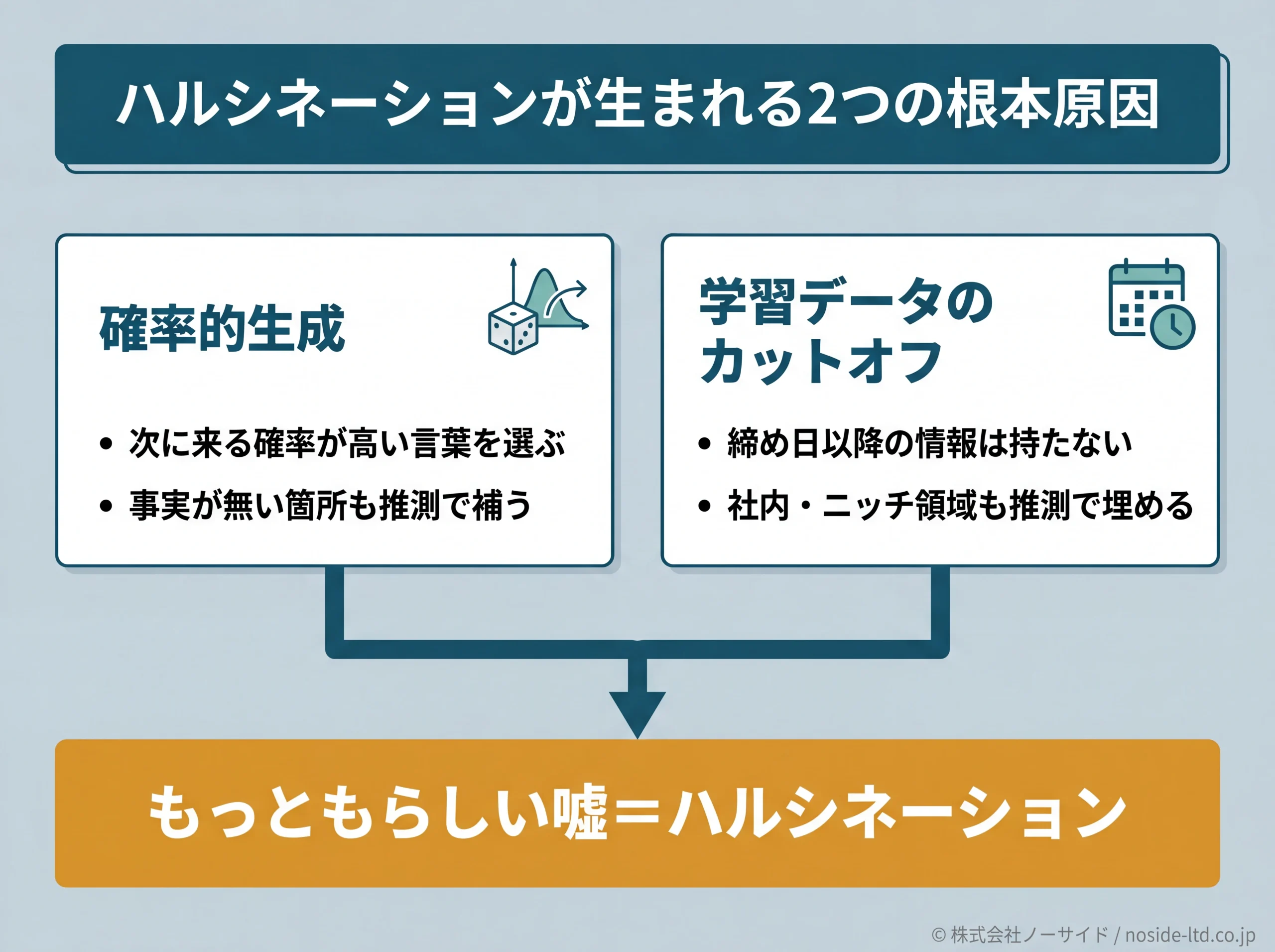
大規模言語モデル(LLM)は、「事実として正しいか」ではなく「次に来る確率が高いトークン(言葉)」を選んで文章を生成する確率的な仕組みで動いています。
事実が手元にない箇所も、もっともらしい続きを推測で埋める性質があり、これがハルシネーションの構造的な根っこです。
2025年9月にOpenAIが公開した研究では、ハルシネーションが起きる理由を「訓練と評価の手続きが、不確実だと認めることより推測することに報酬を与えているために起きる」と結論づけています。
難しい試験問題に直面した学生のように、LLMは不確実なときに推測した方が”成績”が上がる構造になっている、というのが核心です。
つまりAIは、正直に「分かりません」と答えるより、空欄を推測で埋めて何かを書いた方が、訓練上は評価が高くなりやすい。これが、知らないことでも自信ありげに語ってしまう挙動の元になっています。
出典: OpenAI公式「Why language models hallucinate」(英語)
もうひとつ重要な前提として、AIモデルには学習データの締め日(カットオフ)があり、それ以降の出来事や、学習が薄い領域(社内情報・ニッチな制度・最新の料金改定など)は、推測で埋められやすい領域です。
Google公式のGeminiドキュメントも、検索グラウンディング機能を「学習データのカットオフを超えて、検証可能な出典付きで答えるための仕組み」と説明しており、裏返せばグラウンディング機能を使わない素のAIは、カットオフに縛られて推測で答えるということです。
出典: Google AI公式「Grounding with Google Search」(英語)
ここで強調しておきたいのは、同じAIに同じテーマを聞いても、質問の書き方を変えるだけで誤回答の確率が大きく変わるという点です。
「不具合だから仕方ない」と諦める前に、自分の質問が誤回答を引き寄せていないかを点検する余地が、まだ十分に残っています。
誤回答を招くプロンプトの典型パターン6つ(送信前セルフチェック付き)
ここからが本題です。私たちが業務でAIに質問するとき、気づかないうちにハルシネーションを誘発しがちな書き方には、いくつかの典型パターンがあります。
順を追って見ていきましょう。読みながら「先週送ったあの質問、これに当てはまるかも」と思い当たる箇所があれば、それが書き換えの最初のターゲットになります。

パターン①存在しない前提・架空の固有名詞を含む質問(false premise)
失敗例:「A社のプレミアム保証制度の条件を教えて」(その制度が実在するか未確認)、実在企業の設立年・本社所在地を誤って答える、存在しない山・論文・人物の詳細を創作する、といった現象です。
なぜ起きるか:AIは前提の真偽を疑うより、前提に沿ったそれらしい続きを生成しやすい性質があります。
研究レベルでは「誤った前提を含む質問(false premise question)」を与えると、LLMは誤りを指摘せずに前提に乗った捏造を返しやすい、という報告が出ています(arXiv:2402.19103)。
確率的生成の仕組み上、AIは「その前提は成立しないのでお答えできません」と返すより、前提を呑んで何かを答えた方が、訓練上は高く評価される構造になっているためです。
予防チェック:聞く前に「その固有名詞・制度・数字は実在を確認したか」を1秒だけ自問する。実在不明なものは「○○は存在しますか。なければ無いと答えてください」と存在確認から入る。
起きた後の対処:返ってきた固有名詞・数値・日付は、それ単体を一次情報(公式サイト・公式リリース・公的データ)で再検索して照合する。AIの回答だけを根拠に資料化しない。
パターン②範囲・条件が抜けた丸投げ質問
失敗例:「日本経済について教えて」「マーケティングのやり方を教えて」「業務効率化の方法を教えて」のように、対象・目的・範囲が一切指定されていない丸投げ型です。
AIは焦点を判断できず、解釈範囲を勝手に広げて、事実に基づかない一般論を補完しはじめるのがこのパターンの典型挙動です。
なぜ起きるか:目的・対象・範囲が無いと、AIは無難でそれらしい一般論を最尤(もっとも確率が高い続き)として生成し、検証されていない断定が静かに混入します。
「自然な文章を生成すること」と「事実として正しい文章を生成すること」は別問題で、丸投げ質問は前者だけが満たされやすい典型です。
予防チェック:質問に5W(誰に向けて/何のために/どの範囲/いつ時点/どの形式で)が入っているかを確認する。1つでも抜けていたら追記する。
起きた後の対処:返答が一般論に終始したら、「対象を△△、時点を□□、500字で、箇条書き3点で」と条件を足して再質問する。最初の返答を採用しない。
パターン③「〜ですよね?」と結論を握らせる誘導・断定前提
失敗例:「△△の方が優れていますよね?根拠も含めて教えて」「○○は法律的にNGですよね?」のように、自分が答えを先に決めて同意を求める聞き方です。
AIはユーザーに同調(迎合=sycophancy)し、前提を訂正せずに嘘の根拠を補強する方向に流れやすくなります。
なぜ起きるか:短期的なユーザー満足を学習報酬にした副作用で、AIは「気持ちよくさせる答え」に寄る性質があります。
OpenAIは2025年4月、GPT-4oが過度に迎合的になった更新を撤回したことを公表しており、迎合は実際に起きる現象として開発元自身が認識・対応している事象です。
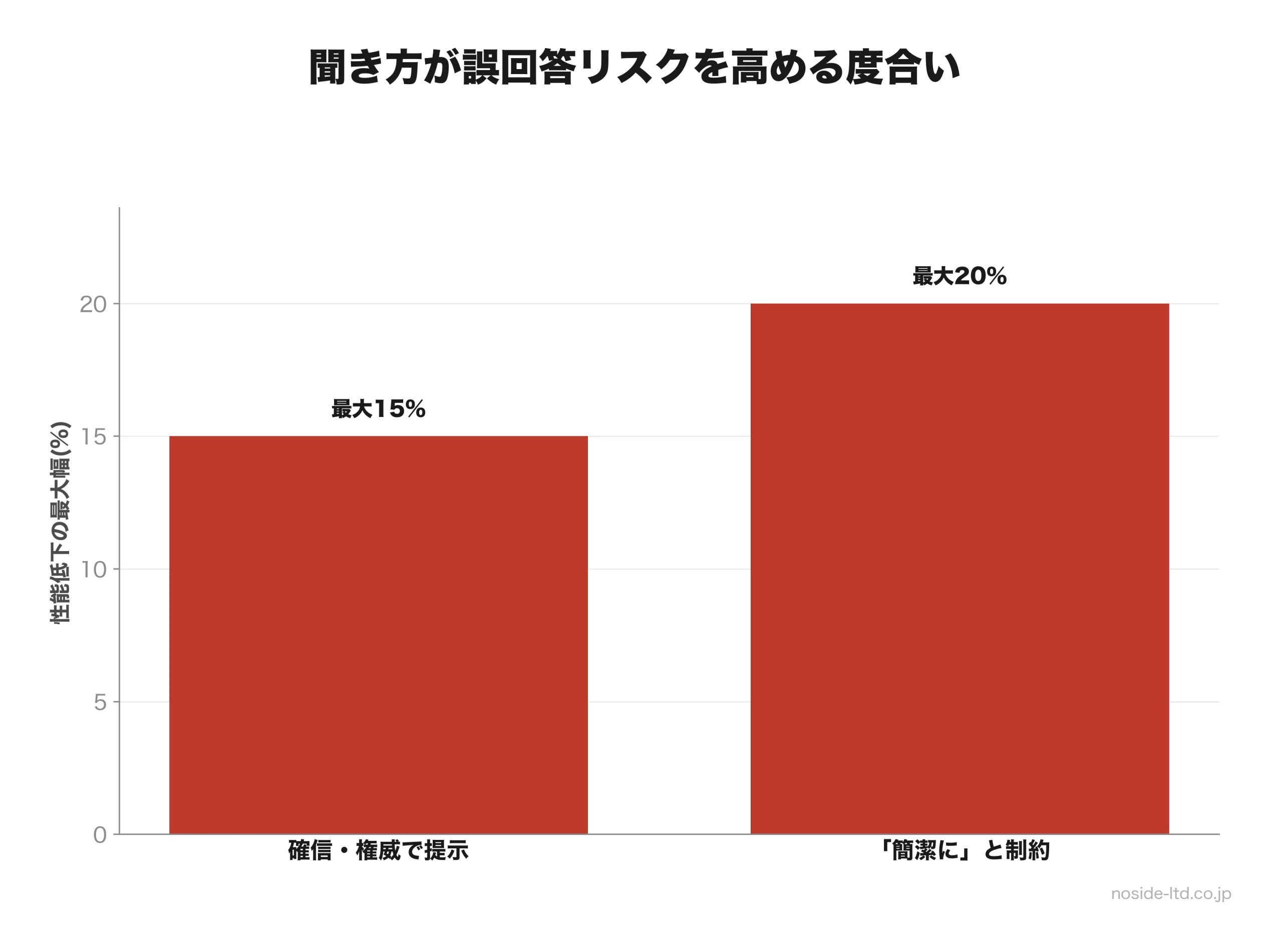
第三者ベンチマークの調査(Phare/Giskard)でも、確信や権威付けで提示された誤主張をAIが反証する確率が、中立的に聞いた場合に比べて最大15%低下したと報告されています。
出典: OpenAI公式「Sycophancy in GPT-4o」(英語) / Giskard / Phareベンチマーク「Good answers are not necessarily factual answers」(英語)
予防チェック:自分が答えを先に決めて同意を求めていないかを確認する。「正しいか?」ではなく「賛否両論を、それぞれの根拠とともに中立に整理して」と中立形に書き換える。
起きた後の対処:「反対意見・反証も同じ強さで挙げて」と、必ず逆方向の見方を追い質問する。同調的な答えを単独で採用しない。
パターン④最新情報・学習データ外を、確認手段なしで聞く
失敗例:検索機能をオフにしたまま「今日の○○の最新価格は?」「最近の法改正の中身を教えて」「先月発表された△△の仕様は?」のように聞いて、古い記憶や推測で断定された回答を受け取る。
社内ナレッジや非公開のニッチ情報を、ファイル添付なしに「教えて」と聞くのも同じパターンです。
なぜ起きるか:先述のとおり、モデルには学習の締め日(カットオフ)があり、それ以降や学習が薄い領域は推測で埋めやすい構造です。
Geminiの「Grounding with Google Search」やChatGPT・Claudeの検索機能は、まさにこのカットオフを補うためにあります。逆に言えば、機能をオフのまま使うと、AIは古い記憶と推測の中で答えを作りに行くしかありません。
予防チェック:聞こうとしている情報は、AIの学習に十分入っているかを考える。最新・社内・ニッチであるほど、検索オン・資料添付・出典明記の3点セットが必要になります。
起きた後の対処:「検索機能をオンにして出典URLを付けて再回答して」と指示するか、一次資料(公式PDF・公式ページ)を添付して「この資料の内容だけから答えて」と聞き直す。記憶頼りの初回回答は採用しない。
パターン⑤答えが存在しない・ナンセンスな問いを真顔で聞く
失敗例:前提自体が成立しない問い(検証目的でよく使われる「歯が9本のサイが好きな野菜は?」型のナンセンス質問)に対し、AIが「存在しません」と返す代わりに、それらしい答えを作文してしまう現象です。
業務文脈でも、「○○の業界平均値は?(存在しない統計)」「△△の標準的な比率は?(業界によらず一律の標準値が無いケース)」のように、そもそも客観的な正解が無い問いに断定的な答えが返ってきたら、捏造の可能性を強く疑うべきです。
なぜ起きるか:先述のOpenAI研究の通り、AIは「答えられない」と返すより、「それらしい答え」を出す方が訓練上は高く評価されやすい構造になっています。
空欄を残すより、推測で埋めた方が成績が上がる試験を受け続けてきた、というアナロジーが分かりやすいかもしれません。
予防チェック:その問いに客観的な正解が存在するかを、自分の側で先に判断する。存在しない可能性があるなら、最初から「答えが存在しない場合は、存在しないと明言してください」と添える。
起きた後の対処:「いま挙げた数字の出典を1件ずつ示して。示せないものは取り下げてください」と裏取りを要求する。出典が示せないものは、すべて捏造の可能性ありとして扱う。
パターン⑥「簡潔に」「断定で」など精度を犠牲にする制約
失敗例:「一言で答えて」「結論だけ」「断定して」「短く」のように、説明や留保を削らせる指示を入れて、根拠や前提条件が削れた断定的な誤回答を受け取る現象です。
「忙しいから短く」のつもりで足した一言が、ハルシネーションを誘発する側に作用している、というのが落とし穴です。
なぜ起きるか:簡潔化の指示は、誤りを訂正する余白(根拠・条件・留保・例外)を物理的に奪います。
Phare/Giskardベンチでも、「簡潔に答えて」のような短く答えさせる指示で、最も極端なケースでハルシネーション耐性が約20%低下したと報告されています。
これはAIモデルが「正確さ」より「短さ・断定」を優先する方向に最適化されてしまうためで、複雑なテーマや前提が分岐するテーマほど顕在化しやすい構造です。
予防チェック:短さを求めるあまり、根拠や留保を禁止していないかを確認する。複雑な問いに「一言で」と指示しないことを基本ルールにする。
起きた後の対処:「結論→根拠→確信度(高/中/低)」の順で答えさせ、確信度が低い部分はその旨を明示させる。短さが必要なら、長文回答を出させてから自分で短縮する流れに切り替える。
送信前5秒セルフチェックリスト
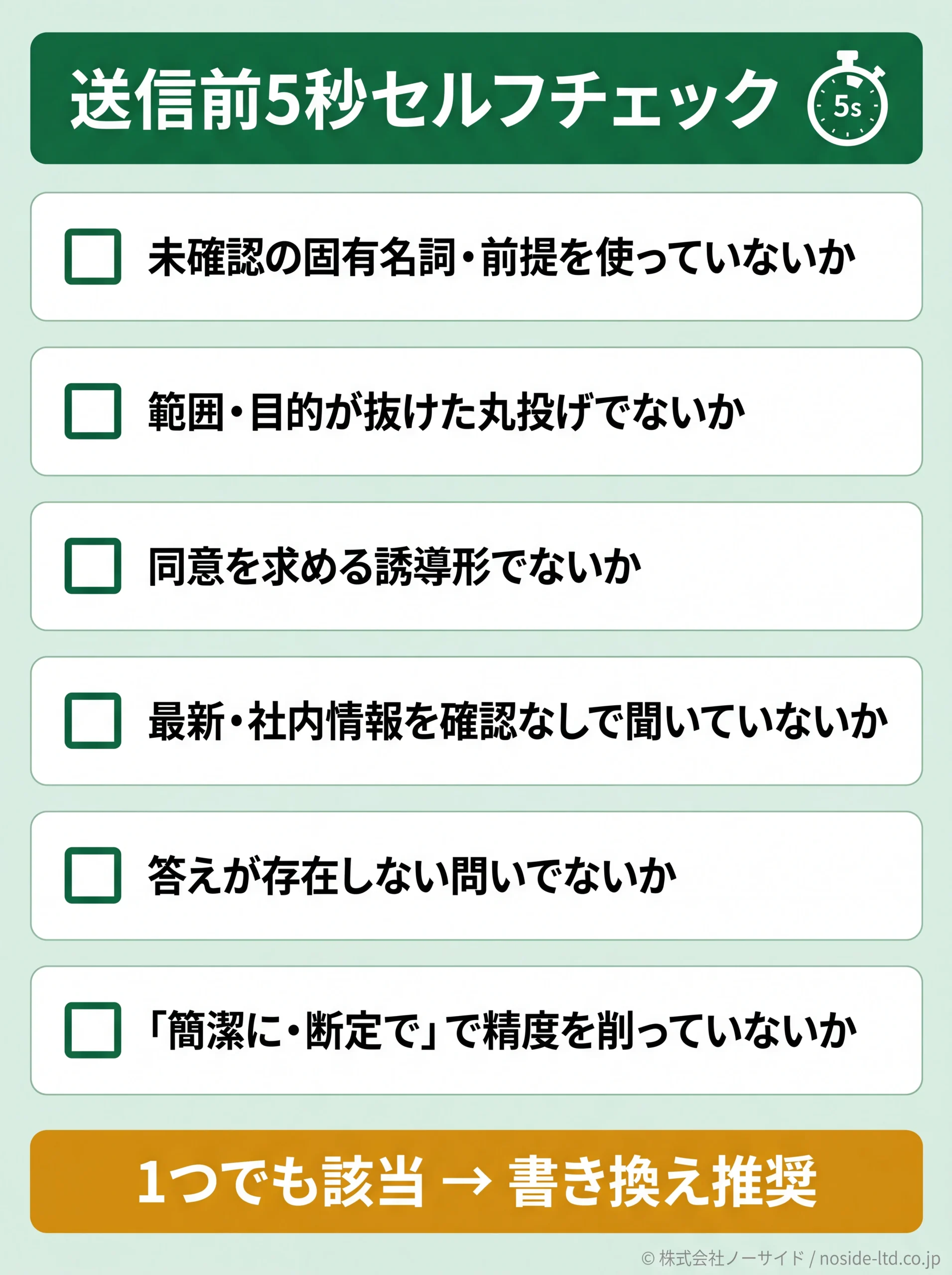
ここまでの6パターンを、業務で使える1枚のチェックリストに圧縮しました。送信ボタンを押す前に5秒だけ目を通す運用を、自分とチームに組み込んでください。1つでも当てはまれば書き換え推奨です。
送信前5秒セルフチェック(全6項目)
- ① 存在を確認していない固有名詞・前提を、あるものとして聞いていないか
- ② 範囲・条件・目的が抜けた丸投げになっていないか(5Wの抜け)
- ③ 答えを自分が握って同意を求める誘導形になっていないか
- ④ 最新情報・社内情報など、AIの学習に無い領域を、検索・資料添付なしで聞いていないか
- ⑤ そもそも答えが存在しない問いを、まじめに聞いていないか
- ⑥ 「簡潔に」「断定で」など、精度を犠牲にする制約をかけていないか
危険プロンプトを安全プロンプトに書き換える(改善前→改善後の4手順)
パターンを見分けられたら、次は書き換えです。AIベンダー各社の公式ドキュメントが推奨しているテクニックを、汎用の4手順に整理しました。
いずれも、AIに性能改善を期待する話ではなく、同じAIから引き出す回答の質を上げるためのプロンプト側の工夫であり、追加コストなしで明日から使える運用変更です。
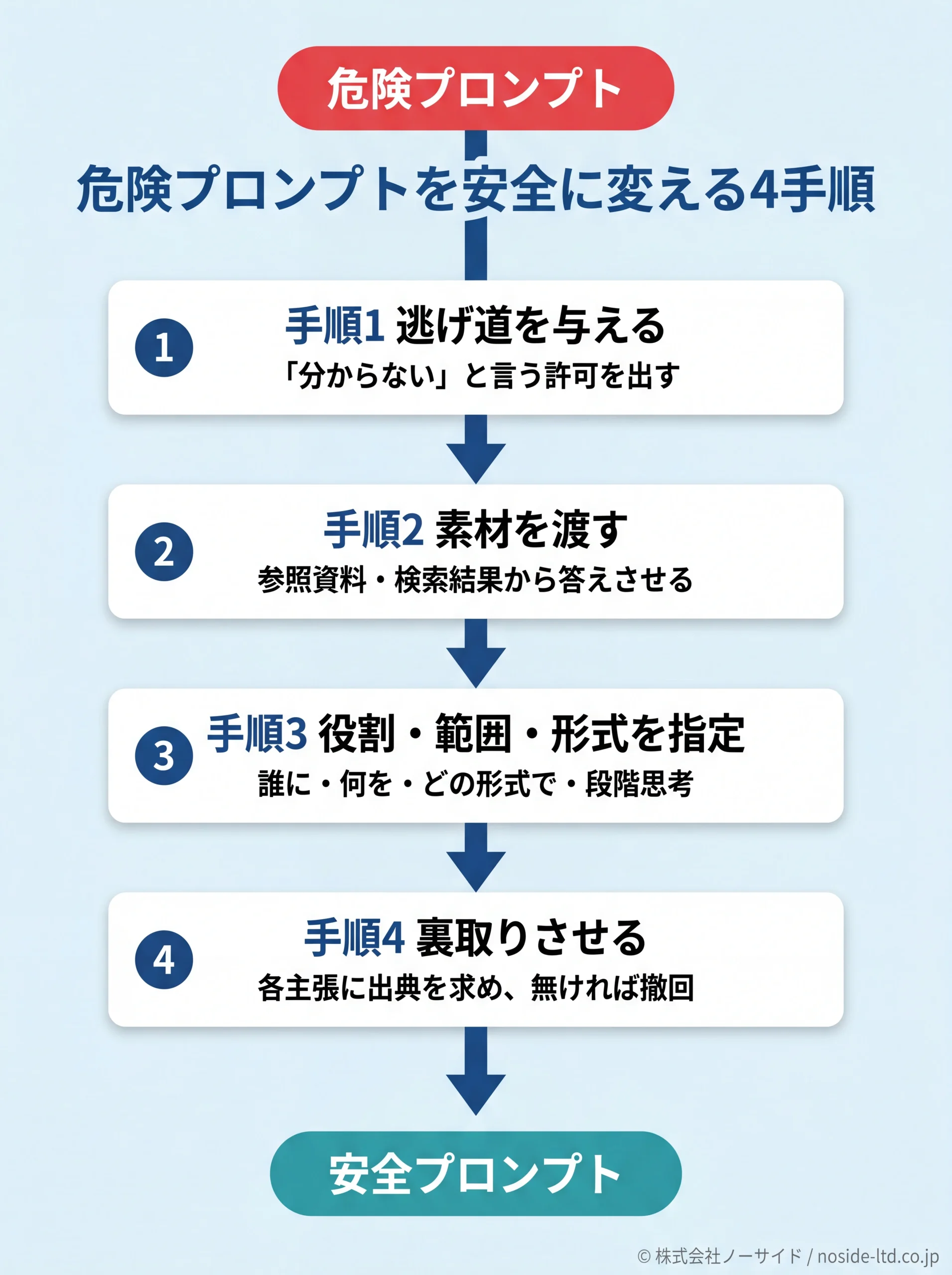
手順1:逃げ道を与える(“分からない”を許可する)
最も簡単で、効果も最も大きい一手です。AIに対して、知らないことは知らないと言ってよいと明示的に許可する書き方を加えます。
| 改善前 | 改善後 |
|---|---|
| ○○制度の申請手順を教えて | ○○制度の申請手順を教えて。確証がない部分や情報が不足している点は、断定せず「確認できません」と明記してください。 |
Anthropic公式の「Reduce hallucinations」ガイドは、第一の対策として「Claudeに『I don’t know(分からない)』と言う許可を明示的に与える」を挙げ、「この単純なテクニックが誤情報を劇的に減らせる」と明言しています。
普段の業務プロンプトの末尾に1文足すだけで実装できる、コストゼロの対策です。
出典: Anthropic公式「Reduce hallucinations」(英語)
手順2:素材を渡して「ここから答えさせる」(参照テキスト・検索グラウンディング)
AIの記憶頼りをやめさせ、自分が渡した素材か、検索で取得した最新情報の中だけから答えさせる書き方です。
カットオフ問題と捏造の大半が、この一手で大きく軽減されます。
| 改善前 | 改善後 |
|---|---|
| 最新の○○の料金を教えて(記憶頼り=捏造リスク) | 次の資料(または公式ページのURL)の内容だけを使って、料金体系を整理してください。資料に書かれていなければ「資料に記載なし」と明記してください。検索機能をオンにする場合は、出典URLを各主張ごとに付けてください。 |
OpenAI公式のプロンプトエンジニアリングガイドも、戦略の1つとして「参照テキストを与える(Provide reference text)」を挙げ、文書に答えが無ければ「Insufficient information.(情報不足)」と書かせるシステム指示例を公式に提示しています。
Anthropic公式も「20,000トークンを超える長文(おおよそ日本語のA4書類で30〜40ページ規模)では、逐語引用を先に抽出させてから本処理に入る」「各主張に裏付け引用を付けさせ、裏付けが見つからない主張は撤回させる」「外部知識の使用を制限する(External knowledge restriction)」を推奨技法として明示しています。
Google公式(Gemini)の「Grounding with Google Search」も、応答を現実世界の情報に基づかせることでハルシネーションを減らし、学習データのカットオフを超えて検証可能な出典付きで答えるための仕組みとして明示されており、ベンダー横断で「素材を渡す・検索でグラウンディングさせる・出典を出させる」が共通の処方箋になっています。
手順3:役割・範囲・形式・段階思考を指定する
丸投げ質問の対極にある書き方です。役割/対象/目的/形式/推論の順序を明示することで、AIが暴れる余地を物理的に減らします。
| 改善前 | 改善後 |
|---|---|
| マーケティングについて教えて | あなたは△△業のマーケティング担当として答えてください。対象は中小企業の経営者、目的は次の四半期の集客テコ入れ、出力は500字以内・箇条書き3点。まず根拠を段階的に整理してから結論を出してください。 |
Anthropic公式は、推論を段階的に書かせる「Chain-of-thought verification(連鎖思考による検証)」を上級テクニックとして挙げており、結論だけ求めるより根拠を段階的に書かせた方が、論理の飛躍や暗黙の前提が表面化しやすくなる、と説明しています。
OpenAI・Geminiの公式も、具体性と明確な指示の重要性を一貫して強調しており、「役割・範囲・形式・段階思考」の組み合わせはベンダー横断のベストプラクティスです。
手順4:出させた後に「裏取り」させる(自己検証)
初回回答を採用する前に、AI自身に裏取りを実行させる追い質問を挟む手順です。
同じAIに自分の回答を点検させるのは矛盾に見えるかもしれませんが、出力された主張を一件ずつ引用と突き合わせさせると、根拠が薄い主張はその場で撤回される率が上がります。
| 改善前(追い質問なし) | 改善後(自己検証の追い質問) |
|---|---|
| 初回回答をそのまま採用する | いま挙げた各主張について、根拠となる引用元を1つずつ示してください。示せないものは取り下げてください。さらに、同じ質問にもう一度答え直して、前回との食い違いがあれば指摘してください。 |
Anthropic公式は、上級テクニックとして「Verify with citations(引用による検証)」「Best-of-N verification(複数回答比較)」「Iterative refinement(反復精緻化)」を挙げ、いずれも追い質問で実装できる安価な手段として推奨しています。
特にハイステークスな(=戻せない)業務では、初回回答を採用する前に、この自己検証フェーズを必ず1段挟む運用が現実的な防衛線になります。
書き換えても消えない「残りのリスク」と人間側の運用
プロンプト改善は発生率を下げるだけ、ゼロにはできない
ここまでの6パターン回避と4手順書き換えを徹底すれば、ハルシネーションの発生率は明確に下がります。ただし、ゼロにはできないという前提を、経営判断のレイヤーで先に固めておく必要があります。
Anthropic公式自身が、ガイドの末尾で「これらの技術はハルシネーションを大幅に減らすが、完全には消せない。重要な判断、特にハイステークスな意思決定では、常に検証せよ」と明記しています。
これは公式ベンダーが自社製品について述べた留保であり、構造的に避けられない領域があることを、開発元自身が認めているということです。
法務・医療・金融など「戻せない領域」の線引きと、決裁者の心構え
では、どこに線を引くか。私たちの考え方の整理は、「間違えたら戻せるか/戻せないか」で2分する、というものです。
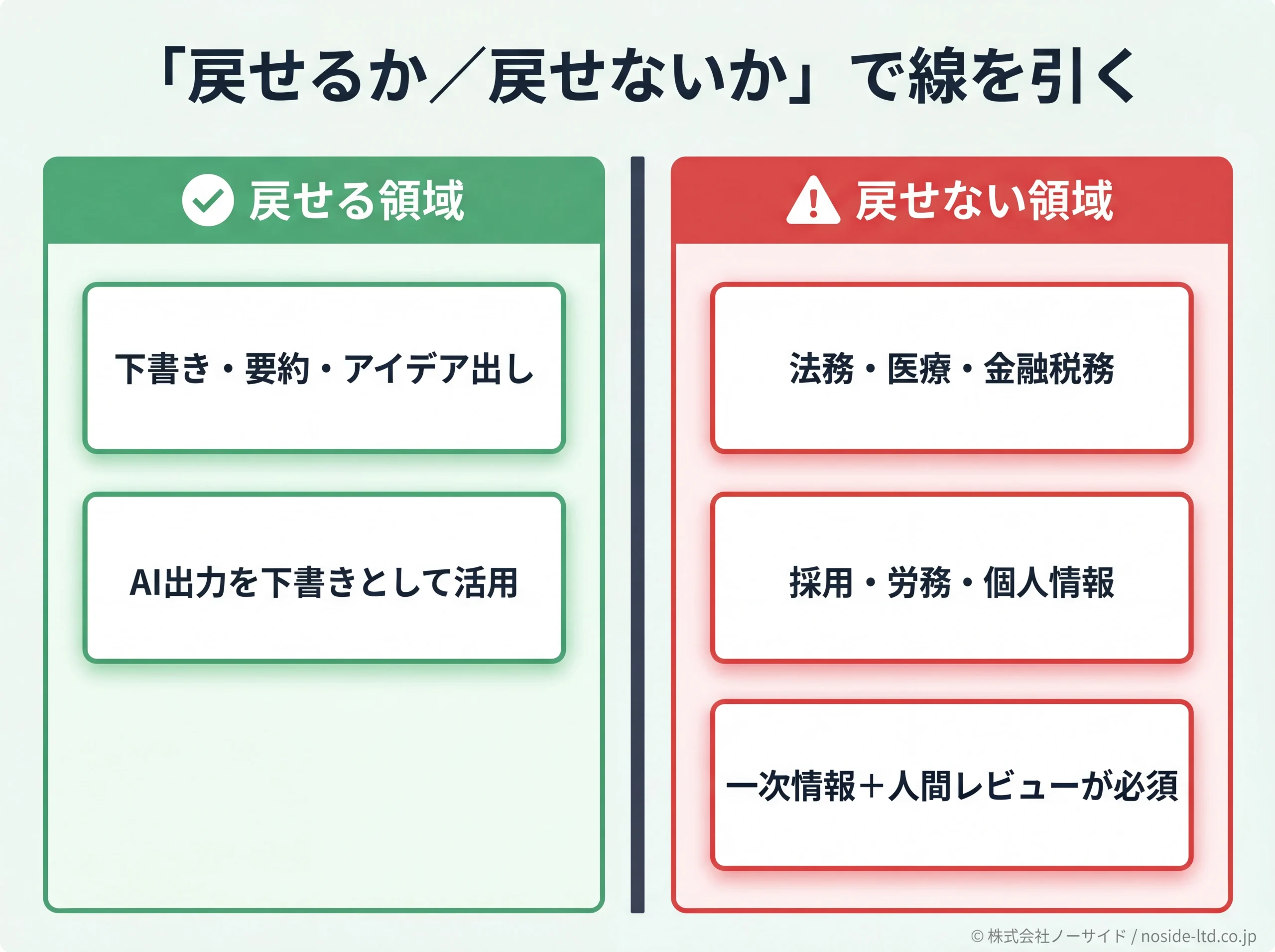
AI出力をそのまま採用してはいけない領域(例)
- 法務:誤った条文・存在しない判例・契約書の解釈
- 医療:診断・治療方針・薬の用法用量・副作用情報
- 金融・税務:個別の節税スキーム・補助金要件・最新の改正対応
- 採用・労務:解雇・懲戒・パワハラ判定など人の処遇に直結する判断
- 個人情報・機密情報:そもそもプロンプトに入れない
これらの領域は、AI出力をそのまま使わない前提に置いてください。出力は下書き、確定は一次情報+人間レビューが基本線です。
もう1つ、決裁者として警戒しておきたいのが自動化バイアスです。
これは「AIが言ったから正しいと思い込む」現象で、AIの流暢な文章が人間の検証スイッチを切ってしまう構造的な認知バイアスを指します。
現場任せ・性善説では失敗する領域で、仕組み(チェック工程の必須化)で防ぐべき課題です。
業務導入チェックリスト(経営者・DX担当向け)
社内でAIを業務に組み込む際、最低限固めておきたいチェック項目を1枚に整理しました。運用ルールとして社内ドキュメント化することを前提に、6項目すべてに「誰が・いつ・どの形で」を埋めて運用してください。
AI業務導入の最低運用チェック(6項目)
- ① 機密情報・個人情報をプロンプトに入れない運用ルールが明文化されているか
- ② 「誰が・どの業務で・何をファクトチェックするか」が定義されているか
- ③ 数値・固有名詞・日付・法令・出典は必ず一次情報で裏取りする手順があるか
- ④ 社外公開物(プレスリリース・提案資料)は、既存の承認/法務レビューに必ず通す運用になっているか
- ⑤ AIの出力を「下書き」と位置づけ、最終責任は人間が負う前提が、現場まで共有されているか
- ⑥ 検索/グラウンディング機能の利用を標準にし、記憶頼みの質問を減らす設計になっているか
業務にAIを本格的に組み込む前に、この6項目を必ず通すことをおすすめします。もしこのチェックリストの設計や社内展開に踏み出すところで止まっている場合は、AI経営手帖の運営会社であるノーサイドの相談窓口から、お気軽にお問い合わせください。
ハルシネーションをめぐる「よくある誤解」を正す
最後に、現場で根強いよくある誤解を整理しておきます。書き換えと運用を社内に展開するとき、ここでつまずく方が多い論点です。
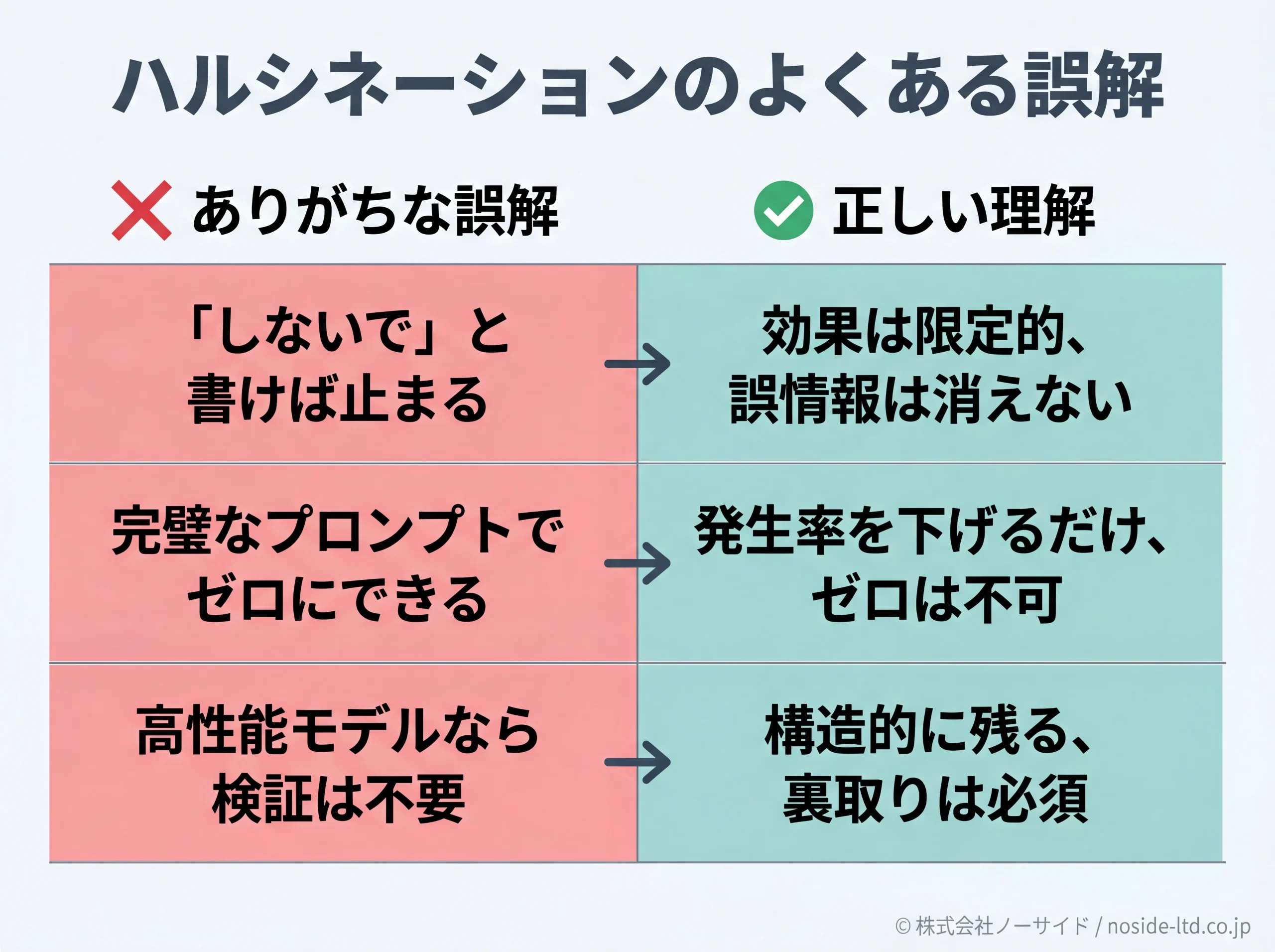
誤解1:「ハルシネーションしないで」と書けば嘘は止まる
正:効果は限定的です。トーンが慎重になる程度で、誤情報そのものは消えません。確率的生成の仕組み上、構造的にゼロにはできない領域です。「逃げ道を許可する+素材を渡す+裏取りさせる」の具体策を組み合わせるのが実効性のある対処です。
誤解2:プロンプトを完璧にすれば誤回答はゼロにできる
正:プロンプト改善は発生率を下げるだけで、ゼロ化は構造的に不可能です。Anthropic公式も「大幅に減らすが完全には消せない」と明言しており、最後は人間の確認が必須になります。
誤解3:AIは知らないことは黙る・知らないと言ってくれる
正:標準の訓練・評価は「分からない」より「推測」を高く評価しがちで、AIは確信ありげに空欄を埋めにきます。だからこそ、ユーザー側が明示的に「分からないなら分からないと言ってください」と許可を出す必要があります。
誤解4:高性能・有料モデルなら正確だから検証は不要
正:推論性能の高いモデルは精度が上がりやすいですが、ハルシネーションは構造的に残ります。モデル選択は対策の一部にすぎず、裏取り運用を置き換えるものではありません。
誤解5:日本語で答えてくれる=日本の制度・最新情報に強い
正:言語対応と、最新性・国内制度の正確さは別問題です。学習カットオフ外・ニッチ領域は、検索グラウンディングや一次資料添付で補う前提で運用してください。
誤解6:もっともらしく流暢な答え=正しい答え
正:「良い(満足できる)答え」と「事実として正しい答え」は別物です。AIは満足度を最適化すると、根拠の薄い断定を流暢に出します。専門外の読者ほど捏造を見抜けない、というのが最大の業務リスクです。
よくある質問(FAQ)
Qハルシネーションを起こしやすいプロンプトの典型は何ですか?
A①存在しない前提・架空の固有名詞を含む質問、②範囲や条件を指定しない丸投げ質問、③「〜ですよね?」と結論を握らせる誘導、④学習データ外の最新情報を検索なしで聞くこと、⑤答えが存在しないナンセンスな問い、⑥「簡潔に・断定で」と精度を犠牲にする制約、の6つが代表的です。
Qなぜ曖昧な質問だと嘘が増えるのですか?
A生成AIは「次に来る確率が高い言葉」を選ぶ確率的な仕組みで動いており、目的や範囲が抜けると焦点を判断できず、それらしい一般論を推測で補ってしまうためです。
Q「ハルシネーションしないで」と指示すれば防げますか?
A効果は限定的です。回答が慎重になる程度で誤情報自体はなくならず、確率的生成の仕組み上ゼロにはできません。「分からないなら分からないと言って」と逃げ道を許可し、参照資料を渡し、出典を出させて裏取りする、という具体策の併用が必要です。
Q誤回答を防ぐ一番簡単なプロンプトの書き換えは何ですか?
A質問の末尾に「確証がない部分は断定せず『確認できません』と書いてください」と加えることです。Anthropic公式も「分からないと言う許可を与える」ことを最初の対策として明示しており、コストゼロで実装できる効果の大きい一手です。
Q最新情報や社内情報を正確に答えさせるには?
AAIの記憶頼みにせず、検索(グラウンディング)機能をオンにして出典URLを出させるか、一次資料を添付して「この資料の内容だけから答えて」と指示します。モデルには学習の締め日があり、それ以降は推測で埋められやすいためです。
Qプロンプトを工夫すれば人によるチェックは不要になりますか?
Aなりません。プロンプト改善は誤りの発生率を下げるだけで、完全には消せません。特に法務・医療・金融など間違えると戻せない領域では、AI出力を下書きとして扱い、数値・固有名詞・出典を一次情報で裏取りする人間の最終確認が必須です。
Q業務で特に避けるべき聞き方はありますか?
A実在を確認していない制度名・人物・数値を「あるもの」として聞くこと、答えを自分で決めて同意を求める誘導、根拠や留保を削る「一言で・断定で」という制約の3つは特に危険です。いずれもAIが前提に迎合し、捏造を補強しやすくなります。
まとめ:書き方と裏取りで、AIを御す
ハルシネーションは、AIの不具合というより確率的生成という仕組みの裏返しです。そして同じAIに同じテーマを聞いても、質問の書き方を変えるだけで誤回答の確率は明確に下がります。
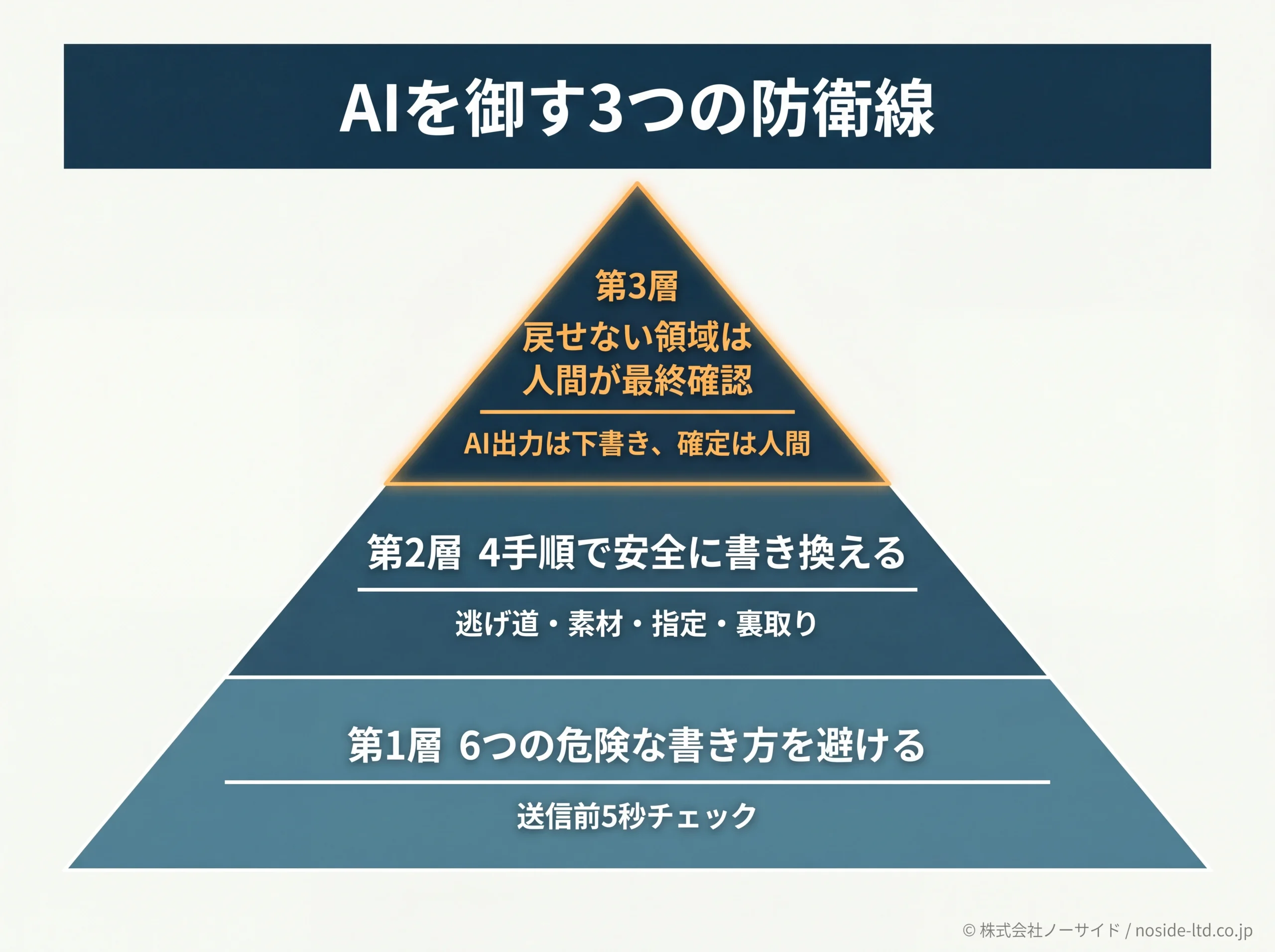
本記事で挙げた6パターンを避け、4手順で書き換え、戻せない領域は人間が最終確認する。この組み合わせが、いま実務で取れる現実的な防衛線です。AIを優秀だが時々もっともらしい嘘をつくアシスタントとして扱い、書き方と裏取りで御していく姿勢が、経営判断に資する使い方の土台になります。
AI経営手帖は、経営者の意思決定に資するAI活用の論点を整理してお届けしているメディアです。