訓練データとは
訓練データとは、AIに学習させるための「お手本」となるデータのことです。大量の例を読み込ませ、そこに潜むパターンをAIにつかませることで、賢く振る舞えるようにします。人間が一つずつルールを教える代わりに、たくさんの実例から法則を自分で学び取らせる。その学びの材料が訓練データであり、いまのAIの賢さは、この材料の良し悪しに大きく支えられています。別名は学習データです。
訓練データの役割
AIは訓練データを読み込みながら、内部の数値(パラメータ)を少しずつ調整して、予測のズレを小さくしていきます。たとえば「これは猫の写真」「これは犬の写真」という見本を大量に見せると、AIは猫と犬を見分ける手がかりを自分でつかんでいく。この見本の集まりが訓練データです。
ここで一つ補助線を引いておきます。訓練データを使った「学習」は、人間が意味を理解して覚えるのとは別物です。AIは内容を分かっているのではなく、膨大な例から「こういうときはこうなりやすい」という傾向を統計的に計算しているだけ。だからこそ、何を学ばせるか、つまりどんなデータを与えるかが決定的に効いてきます。
近年のChatGPTのような大規模言語モデルも、インターネット上の膨大なテキストを訓練データとして読み込み、言葉のつながり方を学んでいるのです。何をどれだけ学んだかが、その後のAIの得意・不得意を形づくる。だからこそ訓練データは、AIづくりの出発点ともいえる存在です。
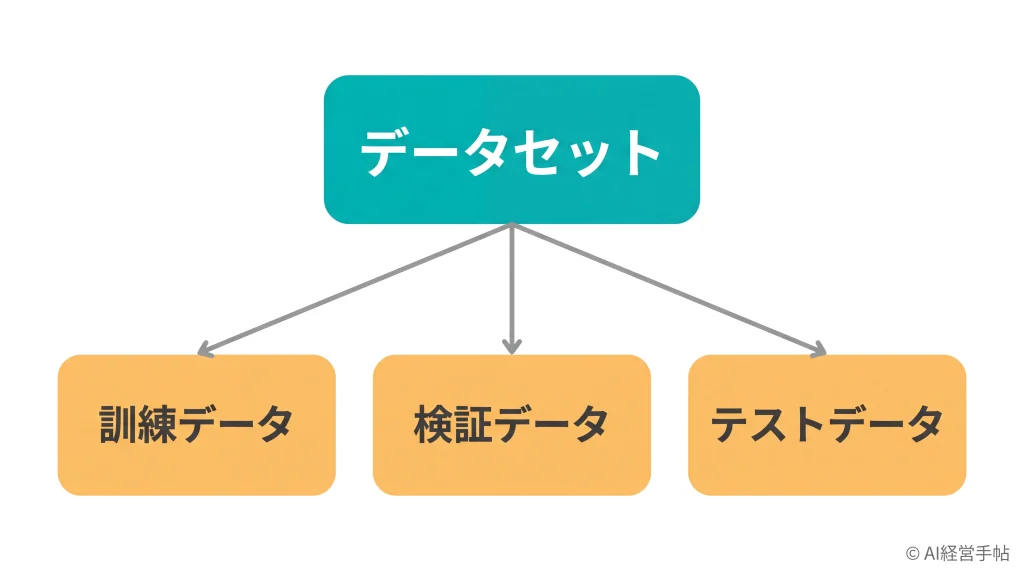
訓練データ・検証データ・テストデータの違い
AIを作るとき、手元のデータは大きく3つに分けて使うのが基本です。1つ目が訓練データで、AIに学ばせるための練習問題。2つ目が検証データ、学習の途中で調整やチェックに使う中間テスト。そして3つ目がテストデータで、仕上がったAIの実力を最後に測る本番の試験にあたります。
大事なのは、テストデータは学習には使わないという点。練習問題と本番の試験を同じにしてしまうと、答えを丸暗記しただけでも高得点が出てしまい、本当の実力(未知のデータに対応できる力)が分からなくなるからです。いわばカンニングを防ぐために、本番用の問題は別にとっておきます。
データの質と偏りが結果を左右する
訓練データを考えるうえで欠かせないのが、データの質と量、そして偏りという視点でしょう。AIの賢さは学んだデータの写し鏡。古い情報や、特定の傾向にかたよった例ばかりを学ばせれば、できあがるAIもその偏りを引き継ぎます。「質の悪いものを入れれば、質の悪いものしか出てこない」とよくいわれるとおりでしょう。
ビジネスでAIを取り入れるときも、ここは見過ごせないポイント。自社のデータでAIを育てる場合、そのデータがどんな偏りを持つかを人が見極める必要があります。どんなデータを学ばせ、その答えをどこまで信じるかを判断するのは、結局のところ人の仕事です。便利な道具だからと丸ごと任せきりにしない。そんな構えで使うのが現実的だと考えています。
TopicAIの賢さは、世界中の人の手作業が支えていた
AIの大きな進歩を支えた有名なお手本に、ImageNet(イメージネット)という画像のデータがあります。その数、なんと1400万枚超。驚くのは、その一枚一枚に「これは何の画像か」というラベルを、人が手作業で付けていったという点です。167カ国の約49,000人が分類に参加し、膨大な候補画像を仕分けたと記録されています。そして2012年、この巨大なお手本で学んだ画像認識AIが桁違いの成績を出し、いまの深層学習ブームの号砲となりました。ChatGPTが広まる10年も前の出来事です。AIは勝手に賢くなったのではなく、その土台には世界中の人の地道なラベル付けがある。そう知ると、AIの見え方が少し変わるかもしれません。
訓練データに関するよくある質問
- AIの賢さは、どうやって作られているのですか?
- 大量の「お手本(訓練データ)」を読み込ませ、そこに潜むパターンを統計的につかませることで作られます。有名なお手本ImageNetは1400万枚超の画像からなり、その一枚一枚に「これは何か」のラベルを167カ国の約49,000人が手作業で付けました。AIは勝手に賢くなったのではなく、土台には世界中の人の地道なラベル付けがあるのです。
- 訓練データ・検証データ・テストデータの違いは?
- 訓練データはAIに学ばせる練習問題、検証データは学習途中の調整に使う中間テスト、テストデータは仕上がった実力を最後に測る本番の試験です。テストデータは学習には使いません(同じにすると丸暗記でも高得点が出てしまうため)。
- なぜ訓練データの質が大切なのですか?
- AIの賢さは学んだデータの写し鏡だからです。偏ったデータを学ばせれば、できあがるAIもその偏りを引き継ぎます。何を学ばせ、答えをどこまで信じるかは人が見極める必要があります。