AIチャットボットの回答精度をどう上げるか|FAQ・問い合わせAIを評価し改善する方法
AIチャットボットの精度は、導入した瞬間に決まるものではありません。
質問ログ、期待回答、根拠文書をつなげて見直すと、どこを直せば回答が良くなるかが見えてきます。
AIチャットボットの回答精度を上げたいとき、最初に見るべき数字はひとつではありません。FAQに正しく答えたか、ユーザーが解決できたか、そもそも答えられる質問だったかは、それぞれ別の問題です。
ここを混ぜると、FAQを増やしたのに問い合わせが減らない、RAGを入れたのに誤回答が残る、最新モデルに変えたのに現場の不満が消えない、という状態になります。回答精度はAI単体の賢さではなく、評価基準、ナレッジ、ログ改善、人の確認をつなげた運用設計で決まります。
AIチャットボットの回答精度は「正答率」だけで見ない
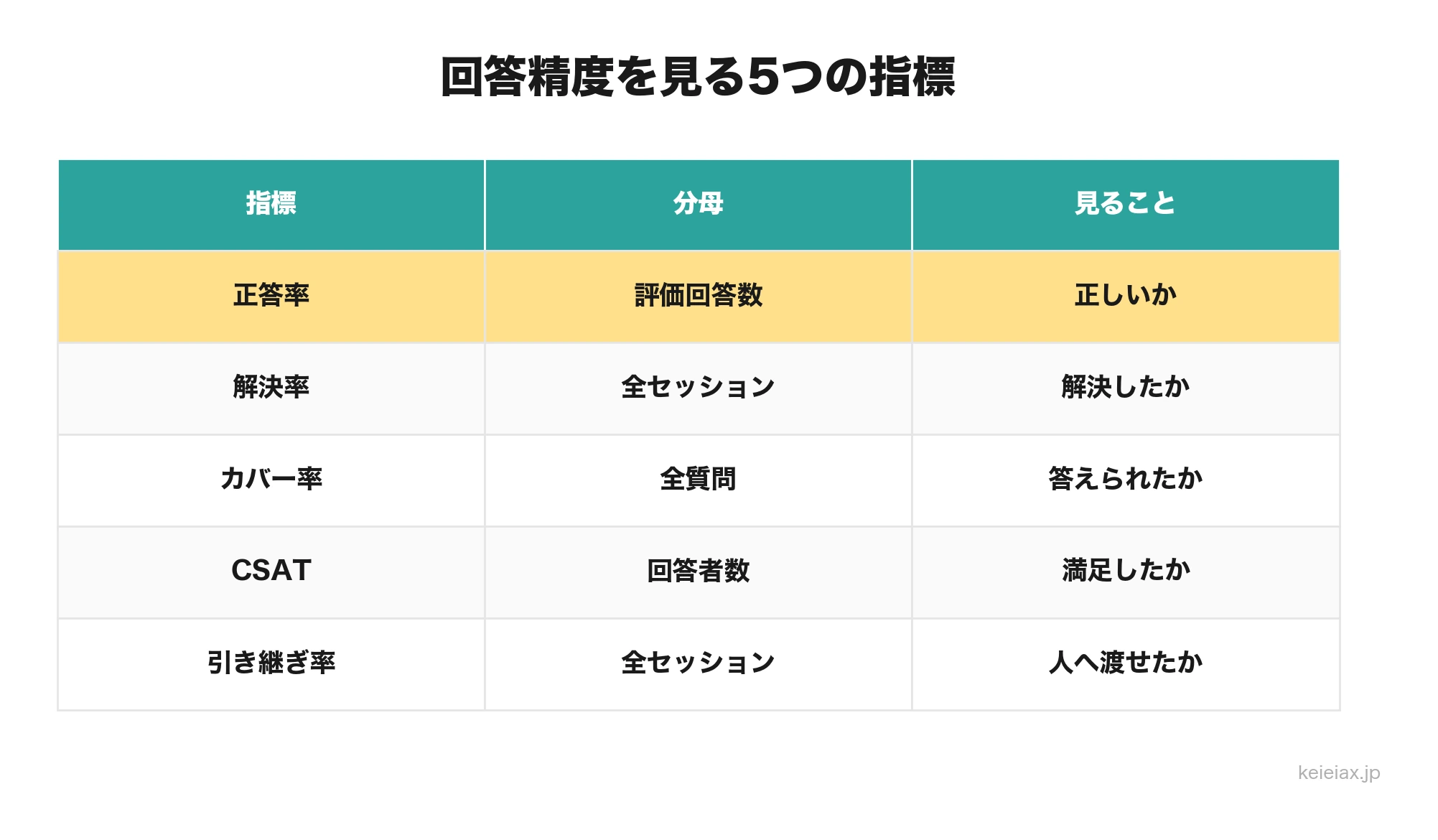
問い合わせAIの改善でよく起きる失敗は、すべてを「正答率」という言葉に押し込めることです。正答率は大事ですが、それだけではユーザー体験を説明できません。正しい回答でも手続きリンクがなくて離脱することがありますし、逆に回答候補は出せても内容が古いこともあります。
最初に、分母と分子を言葉で書ける指標だけをKPIにします。数字の名前だけ先に決めると、現場ごとに集計ルールがずれて、改善前後の比較ができなくなります。
| 指標 | 計算の考え方 | 見るべき場面 |
|---|---|---|
| 正答率 | 正答判定の回答数 / 評価対象回答数 | FAQや社内規程に対して正しく答えたか |
| 解決率 | 解決済みセッション数 / 全セッション数 | ユーザーが追加問い合わせなしに目的を達成したか |
| カバー率 | 回答候補を出せた質問数 / 全質問数 | AIが対応範囲の質問をどこまで拾えているか |
| CSAT | 満足回答数 / アンケート回答数 | 回答文、導線、画面を含めた満足度 |
| 有人引き継ぎ率 | 有人対応に渡した件数 / 全セッション数 | AIが抱え込まず適切に人へ渡せているか |
正答率だけをKPIにすると、ユーザーが本当に解決したかを見落とします。経営判断では、正答率、解決率、カバー率を分け、週次ではログ改善、月次では評価セットの再実行を見るほうが現実的です。
Google Cloudは、生成AIの評価を開発前後だけでなく、ライフサイクル全体で継続する考え方として説明しています。AIチャットボットも同じで、リリース時のテストだけでは品質を保てません。
出典: Google Cloud公式ブログ「あらゆる段階での生成AIの評価方法を解き明かす」
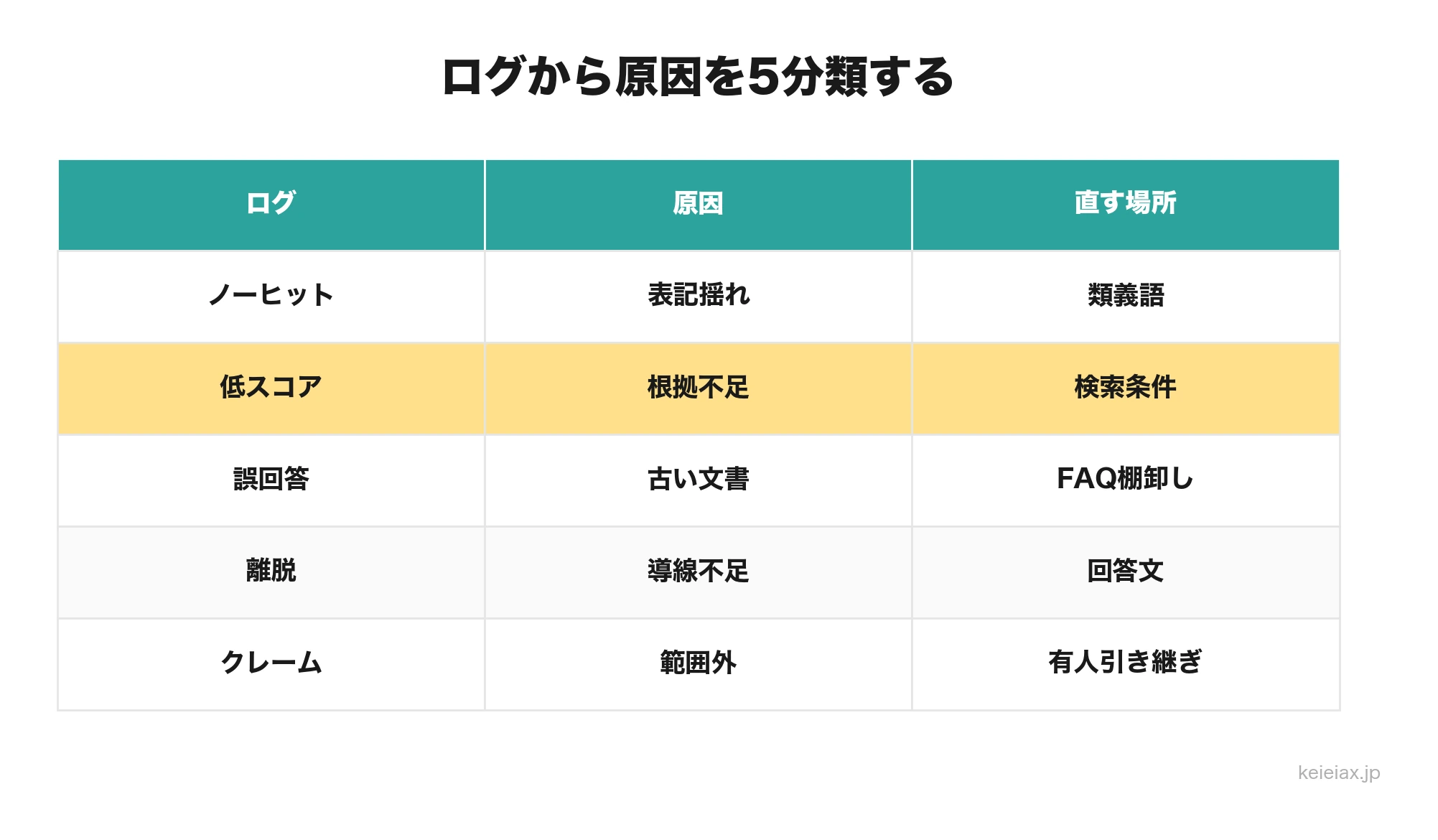
精度が落ちる原因はログから5分類する
AIチャットボットが外す原因を、いきなり「モデルが悪い」と決めつけると、直す場所を誤ります。多くの場合、手がかりはログの中にあり、ユーザーの質問がFAQに存在しないのか、検索された文書がずれているのか、回答文が古いのかで、手を入れる場所が変わります。
| ログの見え方 | 主な原因 | 先に直す場所 |
|---|---|---|
| ノーヒットが多い | 質問表現とFAQ見出しが離れている | 類義語、表記揺れ、質問例 |
| 低スコア回答が多い | 検索候補はあるが根拠が弱い | 文書分割、検索条件、FAQ統合 |
| 誤回答が多い | 古い文書や似たFAQを拾っている | ナレッジ棚卸し、更新日管理 |
| 離脱が多い | 回答後の次の行動がない | 手続きリンク、有人導線、文面 |
| クレーム化する | 答えてはいけない範囲まで答える | 回答禁止条件、確認フロー |
改善会議では、ログを「AIが間違えた」ではなく、ノーヒット、検索ずれ、古い情報、説明不足、範囲外回答に分けます。分類ができると、FAQ担当、現場担当、AI運用担当の誰が直すべきかも見えます。
注意カバー率を無理に上げない
「何でも答えるAI」に近づけるほど、根拠の薄い回答も増えます。顧客向けAIでは、答えられない質問を正しく人へ渡す設計も品質です。
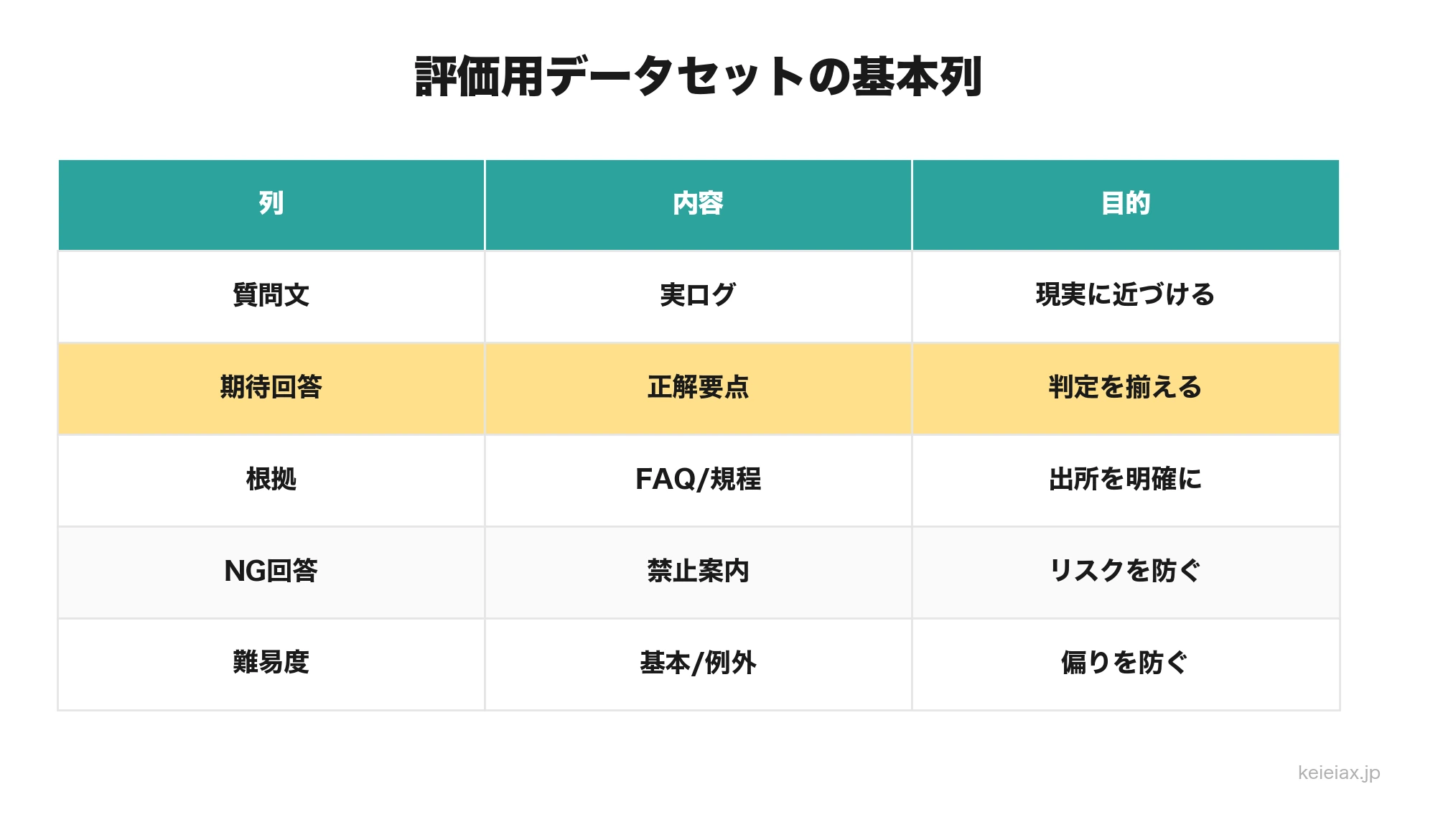
評価用データセットは「期待回答」と「根拠」をセットで作る
回答精度を上げるには、毎回違う質問で感覚的に見比べるのではなく、同じ評価用データセットを使って改善前後を測る必要があります。評価用データセットとは、質問、期待回答、根拠文書、採点基準をまとめたテスト表です。
初期段階では、代表的な質問を30〜50件から始めても構いません。ただし、顧客向けで誤案内の影響が大きい場合や、公開前の判定に使う場合は、カテゴリや難易度を広げて50〜100件以上に増やします。これは公式の固定基準ではなく、実務上の始め方です。
| 列 | 書く内容 | 目的 |
|---|---|---|
| 質問文 | 実ログから選んだユーザーの言い回し | 現実の表現に近づける |
| 期待回答 | 正解とみなす回答の要点 | 評価者のぶれを減らす |
| 根拠 | FAQ、規程、マニュアル、URL | 回答の出どころを明確にする |
| 必須要素 | 必ず含める語句や条件 | 部分正解を判定する |
| NG回答 | 言ってはいけない案内 | 高リスク回答を防ぐ |
| カテゴリ | 請求、予約、返品、社内手続きなど | 弱い領域を集計する |
| 難易度 | 基本、応用、曖昧、例外 | 簡単な質問だけに偏らせない |
評価表の主役は「質問」ではなく「期待回答」と「根拠」です。根拠がない評価表では、AIの回答が正しいのか、評価者の好みなのかが分かりません。
メモ評価セットは本番ログから育てる
導入前に作った想定質問だけでは、表記揺れや曖昧な聞き方を拾えません。公開後は、低評価、有人引き継ぎ、ノーヒットのログから毎月追加します。
人手評価とLLM-as-a-Judgeを使い分ける
評価数が増えると、人がすべての回答を読む負担は重くなるため、期待回答や採点ルーブリックを渡してAIに採点させるLLM-as-a-Judgeを使います。大量の回答を一次判定し、怪しいものだけ人が見る運用なら、改善サイクルが進みやすくなります。
ただし、LLM-as-a-Judgeは万能な判定者ではありません。Google Cloudは、自動評価器の品質を人間がラベル付けしたベンチマークと比較し、採点ガイドラインを調整する考え方を示しています。つまり、AI採点を使う前に、人が評価基準を作ることが前提です。
Microsoft Learnでも、生成AIアプリの評価では一般的な品質、RAG固有、安全性、エージェント固有の指標を分けて扱っています。FAQボットなら、流暢さだけでなく、根拠に沿っているか、必要情報を含むか、不要な断定をしていないかを分けて見るべきです。
出典: Microsoft Learn「ジェネレーティブAIの可観測性」
現実的には、最初の20問から30問を複数人で採点し、評価のずれを合わせます。その後、同じルールをLLM-as-a-Judgeに渡してAI採点と人手採点がずれた設問を改善材料にし、AI採点だけで合否を決めるのは避けるべきです。
FAQ、RAG、プロンプトはこの順番で直す
回答精度が低いと、すぐにプロンプトやモデルを変えたくなります。しかし、FAQや社内文書が古いままなら、どのモデルを使っても誤回答は残るため、改善の順番は、ナレッジ本文、検索、回答制御に置きます。
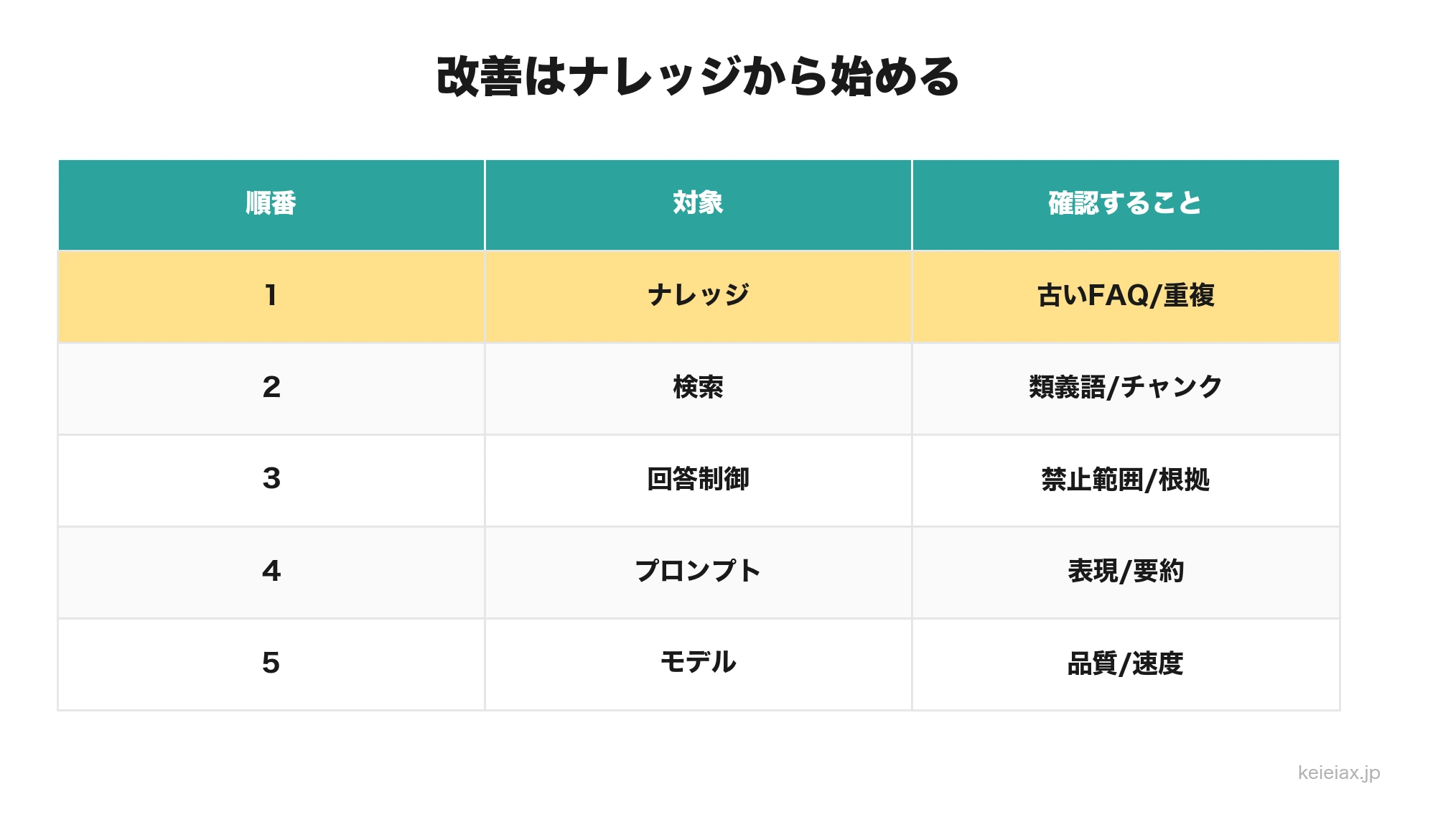
- ナレッジ本文を直す: 古いFAQ、重複FAQ、例外条件の抜け、更新日不明の文書を整理する。
- 検索を直す: 類義語、表記揺れ、チャンク分割、カテゴリ、検索条件を見直す。
- 回答制御を直す: 根拠にない断定を避ける、回答禁止領域を決める、人への引き継ぎ条件を入れる。
- モデルやプロンプトを直す: 上記を直しても残る表現品質や要約品質を調整する。
Google CloudのRAG Engineドキュメントは、RAGをデータ取り込み、変換、埋め込み、索引、検索、生成という流れで説明しています。つまり、RAG型のAIチャットボットは「生成」の前に複数の品質ポイントがあります。
出典: Google Cloud「RAG Engineの概要」
改善順モデル変更の前に見るもの
FAQ本文が正しいか、同じ意味のFAQが重複していないか、古い規程が検索対象に残っていないかを先に確認します。ここが整うと、RAGやプロンプトの改善効果も測りやすくなります。
社内AIと顧客向けAIで評価基準を分ける
社内AIと顧客向けAIでは、許容できる失敗が違いますが、社内AIは担当者が最終確認する前提なら探索的な回答にも価値を持ちます。一方で、顧客向けAIは誤案内がクレーム、返品、契約トラブルにつながるため、安全側の設計が必要です。
| 用途 | 重視する指標 | 設計方針 |
|---|---|---|
| 社内AI | 検索成功率、根拠提示、再利用性 | 候補を出し、人が確認する |
| 顧客向けFAQ | 正答率、解決率、CSAT | 回答範囲を絞り、導線を明確にする |
| 高リスク問い合わせ | 誤回答率、有人引き継ぎ率 | 不確実なら回答せず人へ渡す |
社内AIでは「探せたか」、顧客向けAIでは「誤案内しなかったか」を強く見ます。同じAIチャットボットでも、評価設計を分けなければ現場に合いません。
週次と月次で改善サイクルを回す
精度改善は、導入プロジェクトではなく運用業務で、週次ではログからすぐ直せる問題を拾い、月次では評価用データセットで改善前後を測ります。毎日全件を見る必要はありませんが、誰が何を見るかは決めておく必要があります。
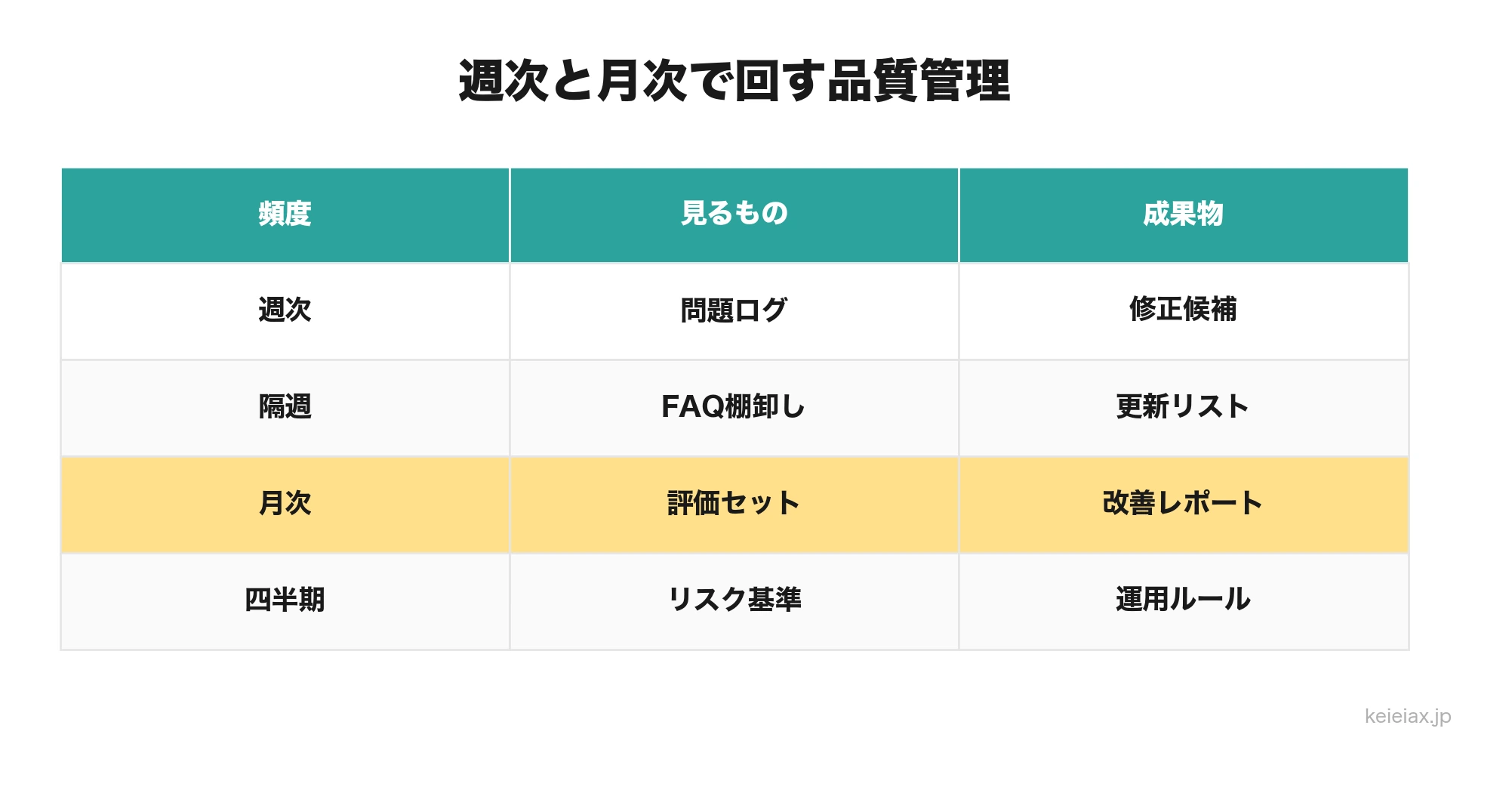
| 頻度 | 見るもの | 担当 | 成果物 |
|---|---|---|---|
| 週次 | ノーヒット、低評価、有人引き継ぎ上位 | 問い合わせ責任者、AI運用担当 | 修正候補リスト |
| 隔週 | FAQ統合、古い文書、表記揺れ | ナレッジ責任者 | FAQ更新、類義語追加 |
| 月次 | 評価用データセットの再実行 | 業務責任者、AI運用担当 | 正答率、解決率、誤回答一覧 |
| 四半期 | 回答範囲、有人引き継ぎ基準、リスク | 経営・管理部門 | 運用ルール改定 |
週次で見るのは上位50件程度の問題ログで十分なこともあります。大事なのは件数より、同じ分類で毎週見て、修正したFAQやRAG設定が翌月の評価で効いたかを確認することです。
運用責任者を4つに分ける
問い合わせ現場はログを見る人、ナレッジ責任者はFAQを直す人、AI運用担当は評価と設定を見る人、業務責任者は回答範囲とリスクを決める人です。AI担当だけに任せると、期待回答と業務判断が更新されません。
2027年に向けて品質管理を資産化する
AIチャットボットは、2027年に向けて単なるFAQ検索から、社内システムや業務エージェントとつながる方向へ進みます。だからこそ、今から評価用データセット、ログ分類、ナレッジ更新の仕組みを持っておくことが重要です。
Microsoft Learnは、生成AIアプリの観測で評価指標、ログ、トレース、モデル出力、品質、安全性、運用健全性を見える化する考え方を示しています。問い合わせAIでも、会話ログと評価結果を残して、あとから説明できる状態にすることが品質管理になります。
総務省・経済産業省のAI事業者ガイドライン第1.2版も、AIのリスクを認識し、ライフサイクル全体で必要な取り組みを進める考え方を示しています。顧客対応AIでは、リスクの高い問い合わせをAIだけで処理しないことも、品質改善の一部です。
出典: 総務省・経済産業省「AI事業者ガイドライン 第1.2版」
最後に、改善の出発点は高機能なツール選びではありません。自社のユーザーが何を聞き、どこで困り、どの根拠で答えるべきかを管理することです。ここが整えば、FAQ型でもRAG型でも、改善の効果を数字で追えるようになります。
FAQ
QAIチャットボットの回答精度は何で測ればよいですか?
AAIチャットボットの回答精度は、正答率だけでなく、解決率、カバー率、CSAT、有人引き継ぎ率を分けて測ります。正しい回答か、ユーザーが解決したか、答えられる範囲を拾えたかは別の問題です。
Q正答率と解決率はどう違いますか?
A正答率は期待回答に照らして正しいかを見る指標です。解決率は、ユーザーが追加問い合わせなしに目的を達成したかを見る指標です。
Q評価用データセットは何件必要ですか?
A評価用データセットに公式の一律件数はありません。初期は代表質問30〜50件から始め、公開前や重要領域ではカテゴリと難易度を広げて50〜100件以上に増やすのが現実的です。
QLLM-as-a-Judgeだけで評価してもよいですか?
ALLM-as-a-Judgeだけで評価を完結させるのは避けます。大量評価や一次判定には使えますが、人手評価との照合で採点基準のずれを確認する必要があります。
Qナレッジ改善とRAG設定改善はどちらを先にやるべきですか?
A先にナレッジ本文を整えます。参照元が古い、重複している、曖昧な場合、RAG検索やプロンプトを直しても誤回答は残ります。
Q精度改善は誰が責任を持つべきですか?
A精度改善はAI担当だけでなく、問い合わせ現場、ナレッジ責任者、業務責任者が分担します。AI担当だけでは期待回答や回答範囲の業務判断を更新できません。