Claude Securityとは|経営者がAI脆弱性診断を業務に組み込む使い方と限界
社内の1人がClaude Securityをそっと回すだけで、コードに眠る危なっかしい箇所が直し方つきで先に見えてくる、と聞いたら気になりませんか?
外部診断の前に自分たちで気づける範囲が、思ったより広がります。
「AIがコードの脆弱性を見つけて、直し方まで提案してくれる」。
Claude Securityはそんな触れ込みで登場し、セキュリティの専門チームを持てない会社にとっては気になる存在になりました。ただ、経営者として本当に知りたいのは、自社の業務にどこまで組み込んでよくて、どこは人や外部診断に残すべきかという線引きではないでしょうか。
この記事では、Claude Securityで何ができて何ができないのかを整理したうえで、今導入すべきか待つべきかの判断軸、社内や委託先への安全な指示の出し方、そしてAI診断の限界とその埋め方までをまとめます。
読み終えたとき、「自社なら何から試すか」「監査で問われたらどう説明するか」を自分で決められる状態を目指しましょう。
Claude Securityとは|「Claudeに診断させる」と何が違うのか
Claude SecurityはAnthropicが提供する、コードの脆弱性を見つけて修正パッチ案まで出す専用ツールです。一般的な「Claudeのチャットにコードを貼って聞く」使い方とは別物で、GitHubのコードとつないで動く専用の画面を持っています。もともとは「Claude Code Security」という名前で限定公開され、その後に名称と提供範囲を広げてきました。
エージェント型の脆弱性診断という位置づけ
最大の特徴は、既知のパターンと照合するのではなく、セキュリティ研究者のようにコードを読んで推論する点にあります。
ファイルやモジュールをまたいで処理のつながりを理解し、入力された値がコードのどこを通って使われるか(データの流れ)をたどる仕組みです。
だから、単純なパターン照合のツールが見逃しがちな、権限まわりや処理のつじつまの不整合まで拾えるかもしれません。
実力の目安として、Anthropicはリサーチプレビューの段階で本番のオープンソースから500件を超える脆弱性を発見したと公表しました。これは当時の上位モデルClaude Opus 4.6を使った結果で、長年の専門家レビューでも見つかっていなかったものが含まれていたといいます。
Anthropicはこの取り組みを「最前線のサイバーセキュリティ能力を守る側(defenders)に届ける」と位置づけています。AnthropicやClaudeの安全性に対する姿勢そのものは、Claudeはどこの会社が作ったAIかでも整理しました。
出典: Anthropic公式「Making frontier cybersecurity capabilities available to defenders」(英語)
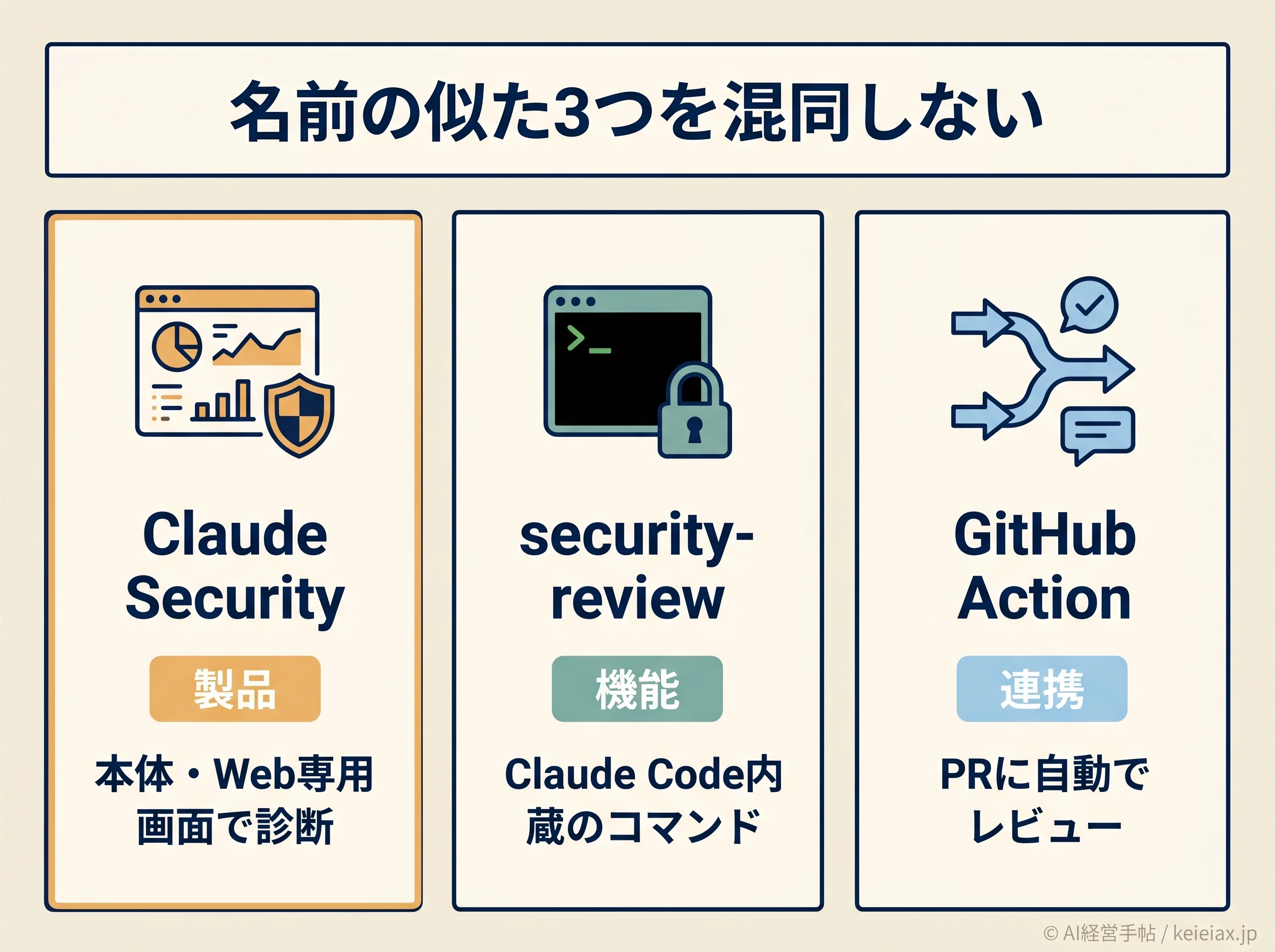
本体・/security-review・GitHub Actionの3つを混同しない
つまずきやすいのが、名前の似た機能の混在でしょう。
経営者がまず押さえるべきは、次の3つがそれぞれ別物だという点です。役割が分かれているので、自社の状況に合うものを選びます。
要点名前の似た3つの違い
Claude Security(本体)
Web上の専用画面でリポジトリをまるごと診断する製品。法人向けの上位契約が前提。
/security-reviewコマンド
開発ツールClaude Codeに内蔵された機能。個人の有料プランでも手元で使える。
GitHub Action
プルリクエスト(コードの変更提案)に自動でレビューコメントを返す連携。
本記事で主に扱う「Claude Security」は1つ目の本体を指します。
ただ、中小企業がまず触れるのは2つ目の/security-reviewになりやすいので、後半の手順で具体的に取り上げます。
何ができて、何ができないのか|経営者がまず押さえる範囲
導入判断の前に、できることと、できないこと(制約)を同じ重さで把握することが欠かせません。
できることだけ見て期待を膨らませると、運用に乗せてから「対象外だった」と気づくことになります。
できること|スキャンから人間承認までの流れ
Claude Securityの仕事は、おおまかに「見つける→検証する→直し方を出す→人が承認する」という流れで進みます。
まずコードを並行して読み込んで危ない箇所の候補を挙げ、次にClaude自身がその指摘を反証しようと再検査して(多段階検証)、思い込みの誤検知をふるい落とす仕組みです。
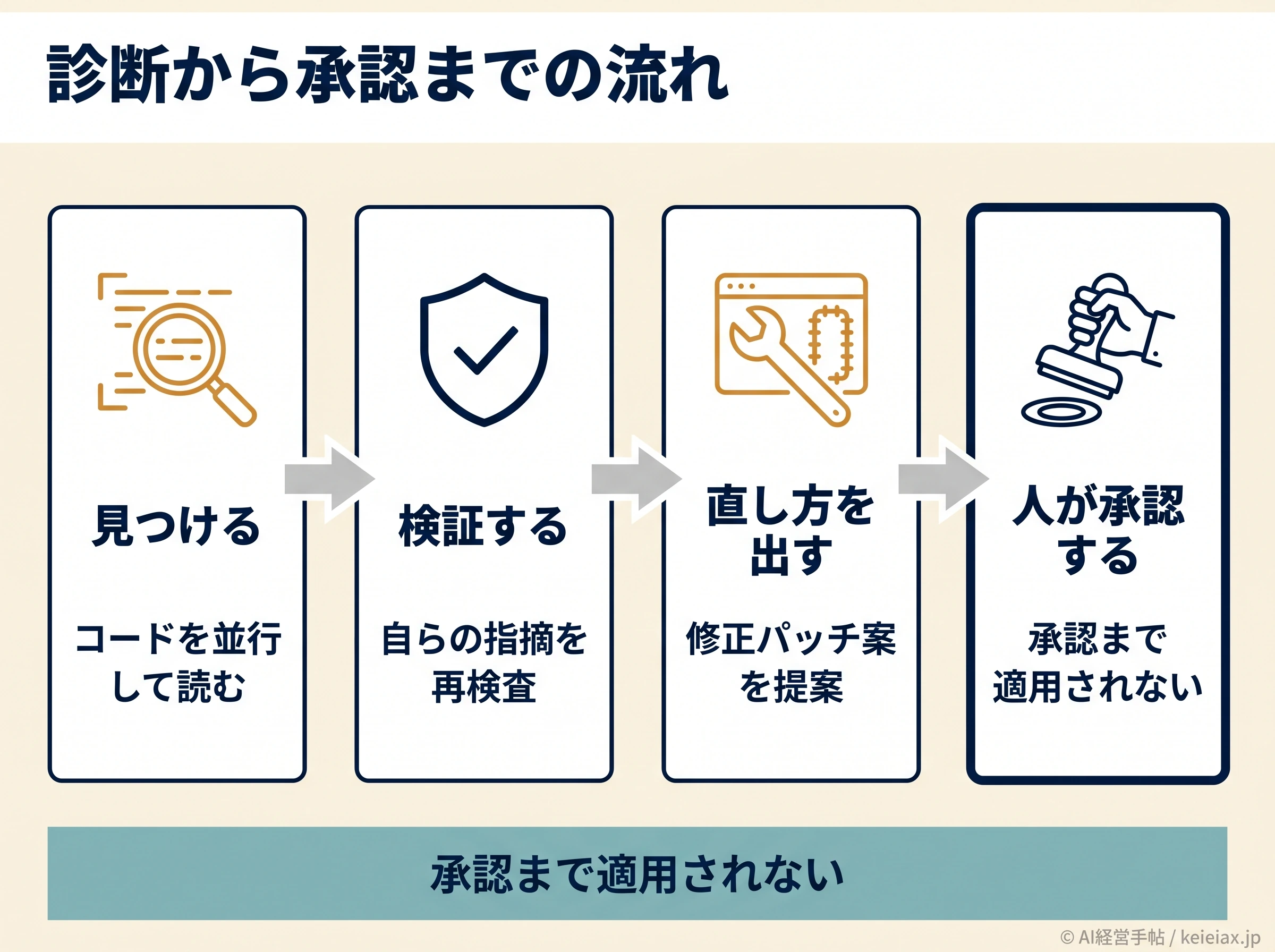
残った指摘には、重大度(HIGH・MEDIUM・LOWの3段階)と信頼度が添えられます。信頼度は「この指摘が本物である確からしさ」のことだと考えてください。
さらに、検証済みの指摘には修正パッチ案が生成され、レビュー用のブランチ(作業用の枝)として用意されます。
ここが経営判断の要です。
人間が承認するまで、修正がひとりでに適用されることはありません。パッチはあくまで提案で、最後に取り込むかどうかは開発者が判断する設計になっています。AIの出力をそのまま信じて当てる怖さについては、ハルシネーションを起こすプロンプトの典型パターンもあわせて読むと腹落ちしやすいはずです。
できないこと・制約|ここを知らずに導入しない
一方で、知らずに導入すると効果が出ない制約もはっきりしています。
とくに次の点は、社内のエンジニアに任せる前に経営者が把握しておくべき線引きです。
注意導入前に知るべき5つの制約
1. GitHub上のコードだけ
現時点ではGitHubにあるリポジトリのみが対象。社内Gitや他サービスは対象外です。
2. 自社が所有するコードだけ
自社が所有し権利を持つコードに限られ、第三者やオープンソースのコードは診断できません。
3. 結果は実行ごとに変わる
スキャンは確率的な設計で、同じコードでも実行のたびに指摘が少し変わります。1回で全部出るとは限りません。
4. 重大度は自分で調整できない
HIGH・MEDIUM・LOWの付け方を会社の基準に合わせて変える、といった設定はできません。
5. まだパブリックベータ
正式版ではなく検証段階で、仕様や提供範囲は今も動いています。
もうひとつ、業務ロジックの細かな判断はソースコードだけからは読み取りにくいため、指摘には信頼度が添えられているとAnthropicも説明しています。
言い換えると、確からしさが低い指摘ほど人間が確かめる前提で作られている、ということです。
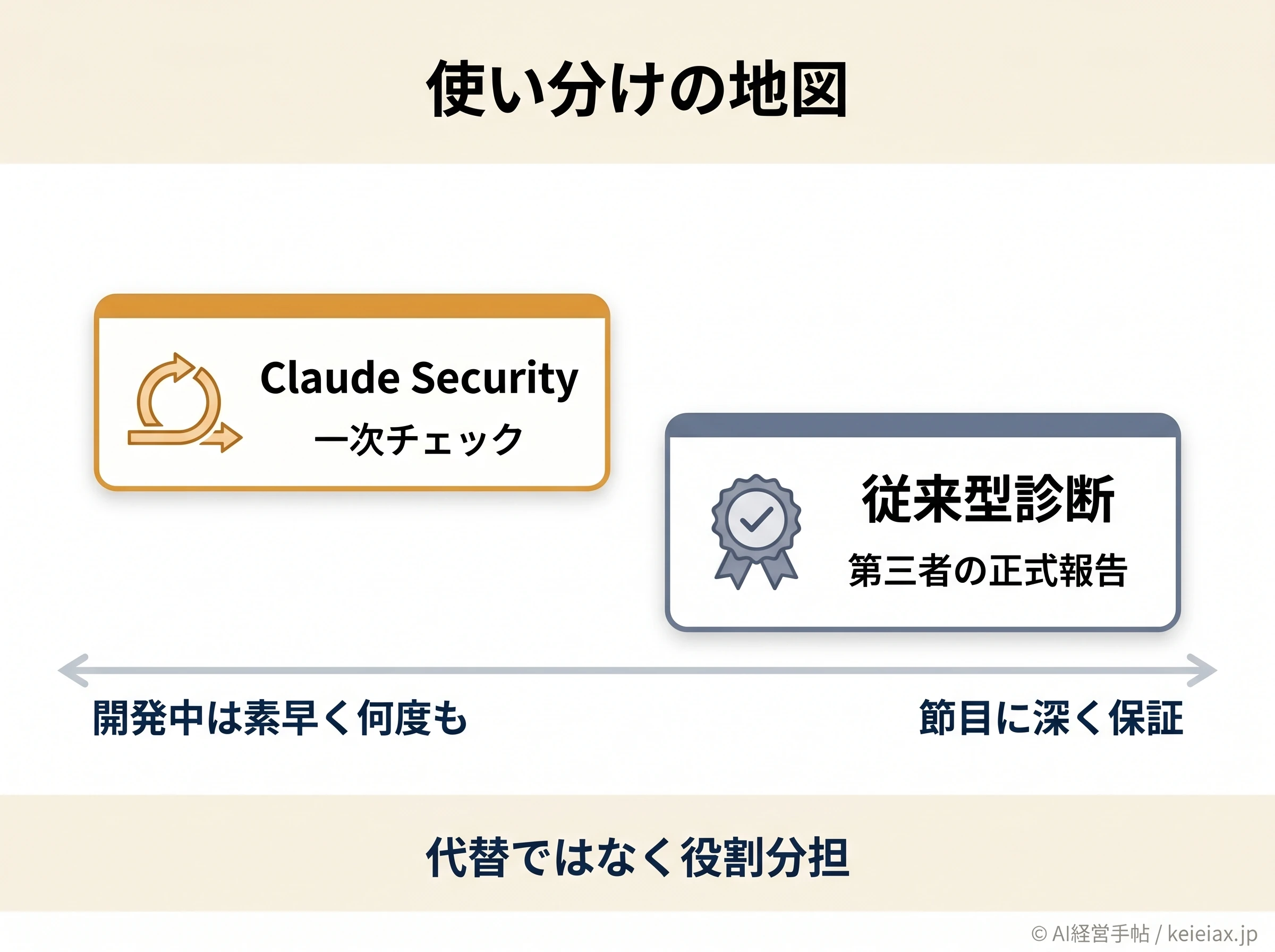
従来型の脆弱性診断と何が違うか
外部の専門会社による従来型診断と、Claude SecurityのようなAI診断は、役割が違う道具です。どちらが上という話ではなく、同じ土俵で長所と短所を並べて使い分けるのが現実的でしょう。
| 比較軸 | 従来型診断 | Claude Security |
|---|---|---|
| 検出方式 | 専門家+ツール | AIが文脈推論 |
| 再現性 | 手順で一定 | 実行ごとに変動 |
| 速さ | 日数〜週単位 | 短時間で反復 |
| 出力 | 診断報告書 | 指摘+パッチ案 |
| 対象範囲 | 契約で柔軟 | 自社GitHub限定 |
| 正式報告 | 第三者性あり | ベータ・補助的 |
ざっくり言えば、日常的な作り込みの段階で素早く何度も回すのがAI診断、節目に第三者の保証つきで深く見てもらうのが従来型です。
この後の判断軸は、この使い分けを前提に組み立てます。
今すぐ導入すべきか、待つべきか|経営者の5つの判断軸
「早期アクセスのうちに入れるべきか、もう少し待つべきか」。
これを5つの判断軸に分けて、自社の条件に当てはめてください。「状況による」で止めないのが、ここでの目的です。
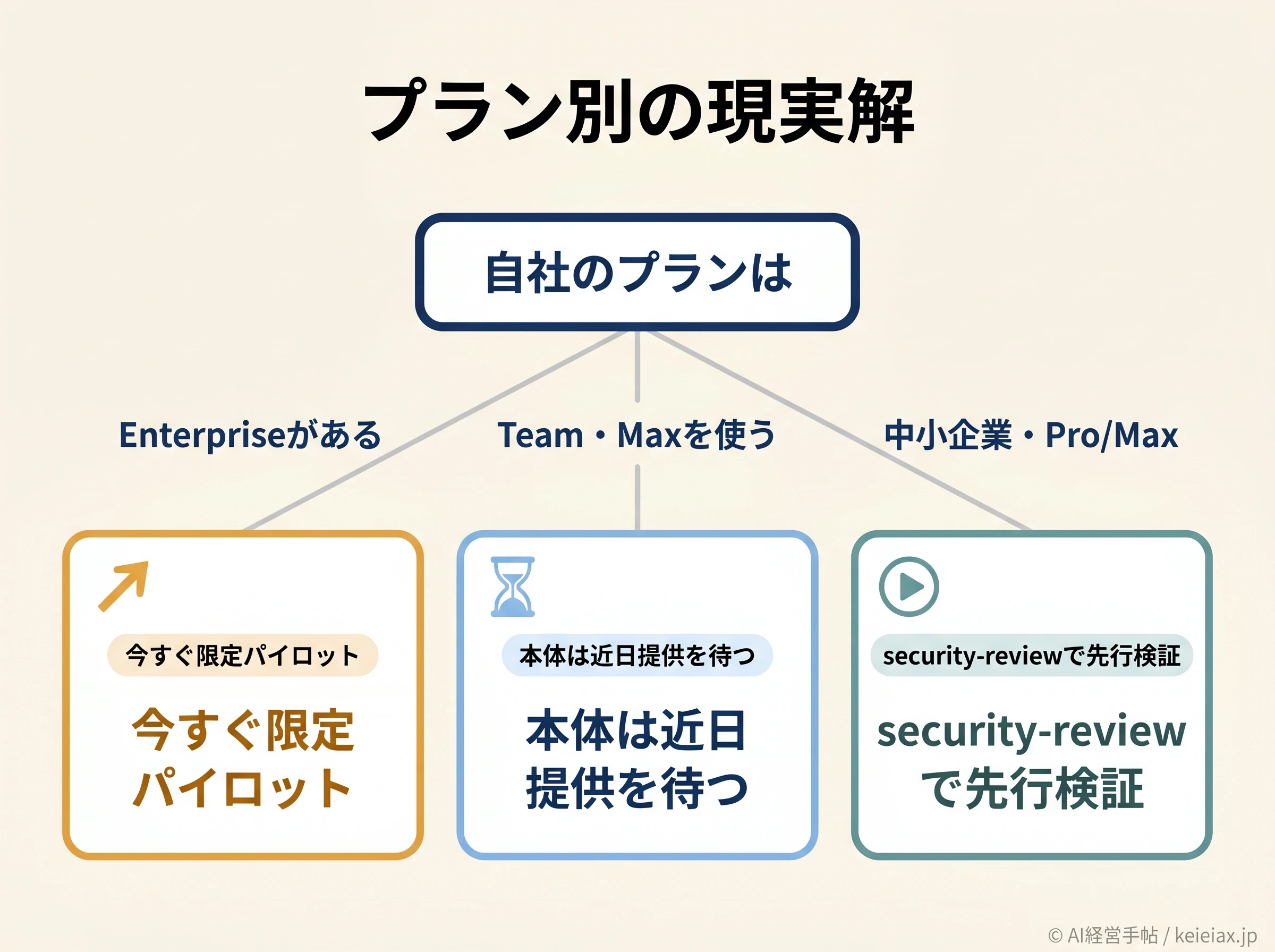
プラン別の現実解(今使えるのは誰か)
本体のパブリックベータは、2026年4月30日から大企業向けの上位契約であるClaude Enterpriseで使えるようになりました。Claude TeamとMax向けは「近日提供予定」とされていますが、具体的な時期は2026年6月時点で公式に示されていません。
つまり、すでにEnterprise契約があるなら今すぐ小さく試せますが、それ以外は本体を待つ立場になります。
出典: Claude公式ブログ「Claude Security is now in public beta」(英語)
では、中小企業は手をこまねくしかないのか。そうではありません。
本体は待ちつつ、開発ツールの/security-reviewを個人の有料プランで先行検証するのが現実解です。プラン体系そのものの考え方は、Claude for Small Businessとはでも触れています。
一次スクリーニングか、正式な脆弱性診断か
もうひとつの分かれ目は、何のために使うかです。
開発中の常時チェック(一次スクリーニング)が目的なら相性は良い一方、取引先に出す正式な診断報告が目的なら単独では足りません。後者は確率的でベータという性質上、第三者の正式診断と組み合わせる前提になります。
判断軸導入可否を決める5つの問い
- プラン:Enterpriseがあるか。なければ/security-reviewで先行できるか
- 対象コード:自社所有でGitHubにあるか
- 用途:常時チェックか、正式な診断報告か
- コスト許容度:従量の費用に上限を設けて運用できるか
- 体制:指摘を確かめて承認する人を1名置けるか
5つのうち「はい」が多いほど、限定スコープでのパイロット導入に向いています。
逆に体制の「はい」が作れないなら、AIスキャンの結果をさばききれずに放置されがちなので、外部診断に役割を寄せる判断が無難でしょう。新しいAIベンダーをどの軸で見極めるかは、経営者がAIベンダー選定で見直すべき判断軸も参考になります。
安全に試す手順と、社内エンジニア・委託先への指示の出し方
「claude code security使い方」を調べる読者がいちばん知りたいのは、どう指示すれば安全に試せるかでしょう。
経営者が現場に丸投げせずに済むよう、試す前の準備と実行の流れを分けて整理します。
試用前チェックリスト(社内ルールにする)
いきなり全社のリポジトリをスキャンするのは避けます。
次の項目を小さな運用ルールとして紙1枚にまとめてから、社内エンジニアや委託先に渡してください。
準備試す前に決めておく6項目
- 対象は自社所有でGitHub上のリポジトリに限る
- 最初は1リポジトリ・1ディレクトリに範囲を絞る
- 従量コストの上限とスキャン頻度を先に決める
- 承認者を1名指名し、無検証で本番に当てない
- 確率的で偽陽性が出る前提で、却下と再スキャンの運用を決める
- 機密度の高いコードを対象にするかを社内で合意しておく
実行の流れと、つまずきやすいポイント
本体の標準的な流れは、GitHub連携→範囲の指定→スキャン→指摘の確認→修正の承認→記録の順です。
各段でつまずきやすい点を添えておきます。
連携でつまずくのは権限不足、範囲指定でつまずくのは対象を広げすぎてコストが膨らむことです。スキャン後は重大度と信頼度の高いものから確認し、信頼度が低い指摘や業務ロジック寄りの指摘は人手での精査が欠かせません。
修正はテストやステージングで動作を確かめてから本番に取り込むのが鉄則です。最後にCSVやMarkdownで書き出して、記録に残しておきましょう。
メモ料金は使った分だけ後払いする従量制(電気代のような仕組み)です。公式はスキャンを「トークンの直接コストのみで、追加のプラットフォーム手数料はない」と説明しています。実額はコードの規模で変わるため、上限設定が予算管理の肝になるでしょう。
Enterprise未契約でも「待つ間」にできる先行検証
本体を待つ会社こそ、準備の差が後で効いてきます。
とくに有効なのが、開発ツールClaude Codeの/security-reviewを個人の有料プラン(Pro・Max)で先に試すことです。これは2025年8月から提供されており、SQLインジェクション・クロスサイトスクリプティング(XSS)・認証や認可の不備・安全でないデータ処理・依存関係の脆弱性といった代表的な弱点を、手元のターミナルから確認できます。
待つ間にやれることは、ほかにもあります。
(1) 自社コードをGitHubに集約する
(2) 外部診断会社との役割分担を先に決める
(3) 機密コードをスキャン対象にするかのルールを作る
この3点を進めておけば、本体が自社プランに届いたときにすぐ着手できます。AIにデータを預ける運用全般の注意は、Claude Coworkを経営者向けに解説した記事でも整理しました。
AI脆弱性診断の限界を直視する|CSRF見落とし事例に学ぶ
AI診断を業務に組み込むうえで、いちばん危ういのは「AIが見つけなかった=安全」と思い込むことです。
実際に、AIが見落とす種類の脆弱性が報告されています。
なぜ文脈依存の脆弱性を見落とすのか
国内のセキュリティ専門会社の検証では、Claude CodeもCodex Securityの/security-reviewも、あるCSRFトークン漏洩を検出できなかったと報告されています。
具体的には、フレームワークのフォーム機能が自動で埋め込むCSRFトークンが、送信先を外部サービスにしたSAMLのフォームを通じて外部へ漏れてしまうという実装でした。両ツールは代わりにハードコードされた署名鍵などを指摘し、肝心のトークン漏洩は素通りしたとされています。
このパターンが見落とされやすいのは、人にもAIにも気づきにくい文脈依存の問題で、ライブラリのサンプルコードにも潜む典型だからです。
スキャンが確率的である点も重なり、同じ箇所でも常に拾えるとは限りません。
出典: GMOサイバーセキュリティ(イエラエ)「Claude CodeもCodex Securityも見落とした、CSRFトークン漏洩の脆弱性」
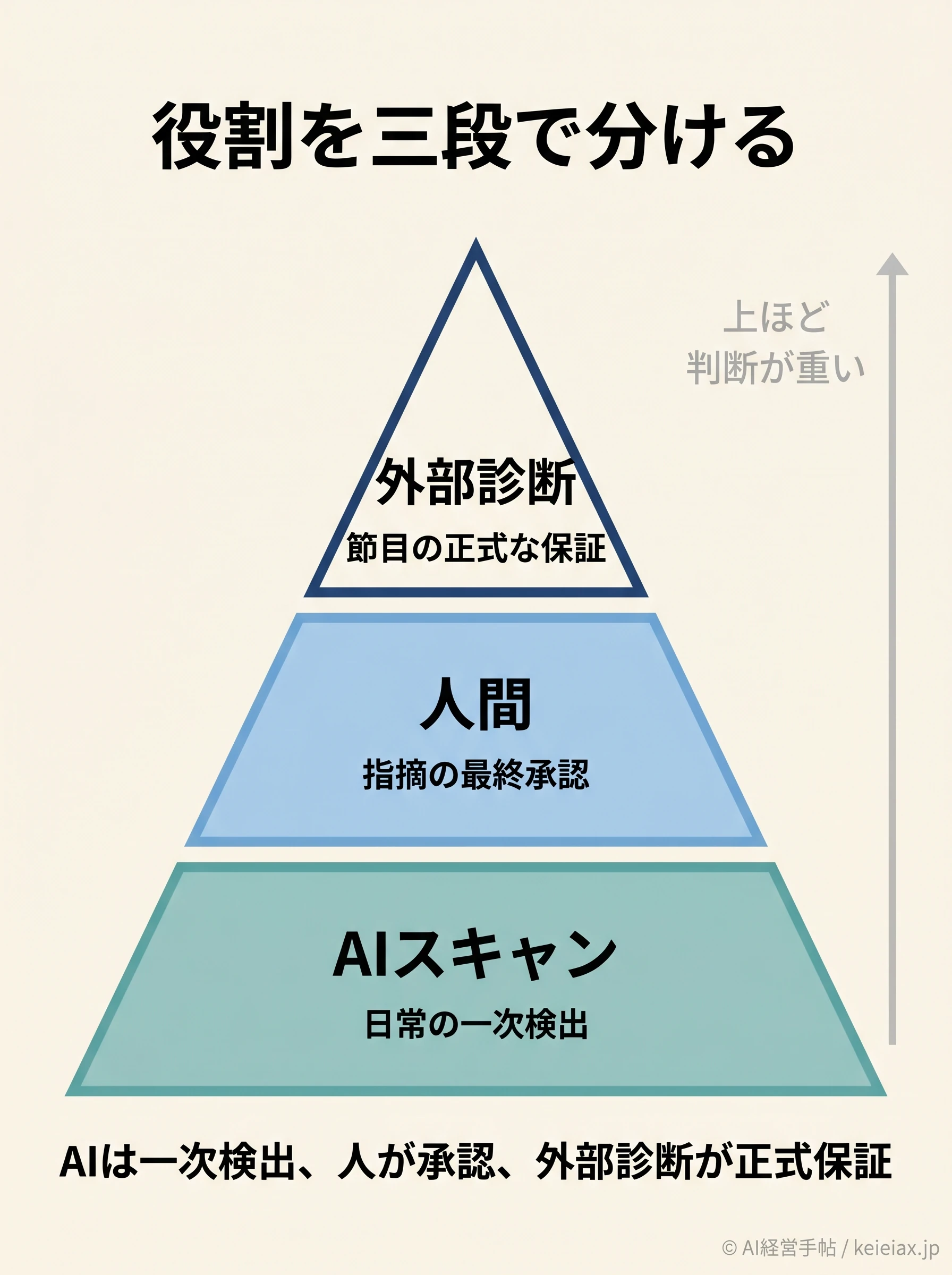
人間レビューと外部診断を組み合わせる二重化設計
だからこそ、AIスキャンを一次検出、人間を最終承認、外部診断を正式保証という三段の役割分担で設計します。
とくに認証・SSO・外部連携まわりは見落としの起きやすい領域なので、AI任せにせず人手や外部診断で二重化しておきたいところです。Anthropic自身も、自動レビューは既存のセキュリティ慣行や手動レビューを「補完するもので、置き換えるものではない」と明言しています。
警告やってはいけない使い方
AIスキャンに合格したから安全、と顧客や監査に言い切るのは危険です。見落としがあり得る前提で、外部の正式診断を定期的に組み合わせ、穴を埋める運用にしてください。
ガバナンスと説明責任|取引先監査・インシデント時にどう説明するか
AI診断を入れると、「それで監査や取引先に説明が通るのか」という論点が必ず出てきます。
ここを整理しておくと、現場の判断もぶれません。
監査証跡の残し方と経営への報告
Claude Securityは検出結果をCSVやMarkdownで書き出したり、プロジェクト単位のWebhookで自社の管理ツールへ送ったりできます。
これを使い、「いつ・どの範囲を・どの重大度で・誰が承認したか」を残すと、経営報告にも監査対応にも使える記録です。定期スキャンの予約や、指摘をコメントつきで却下する機能もあるので、対応の経緯も残せます。
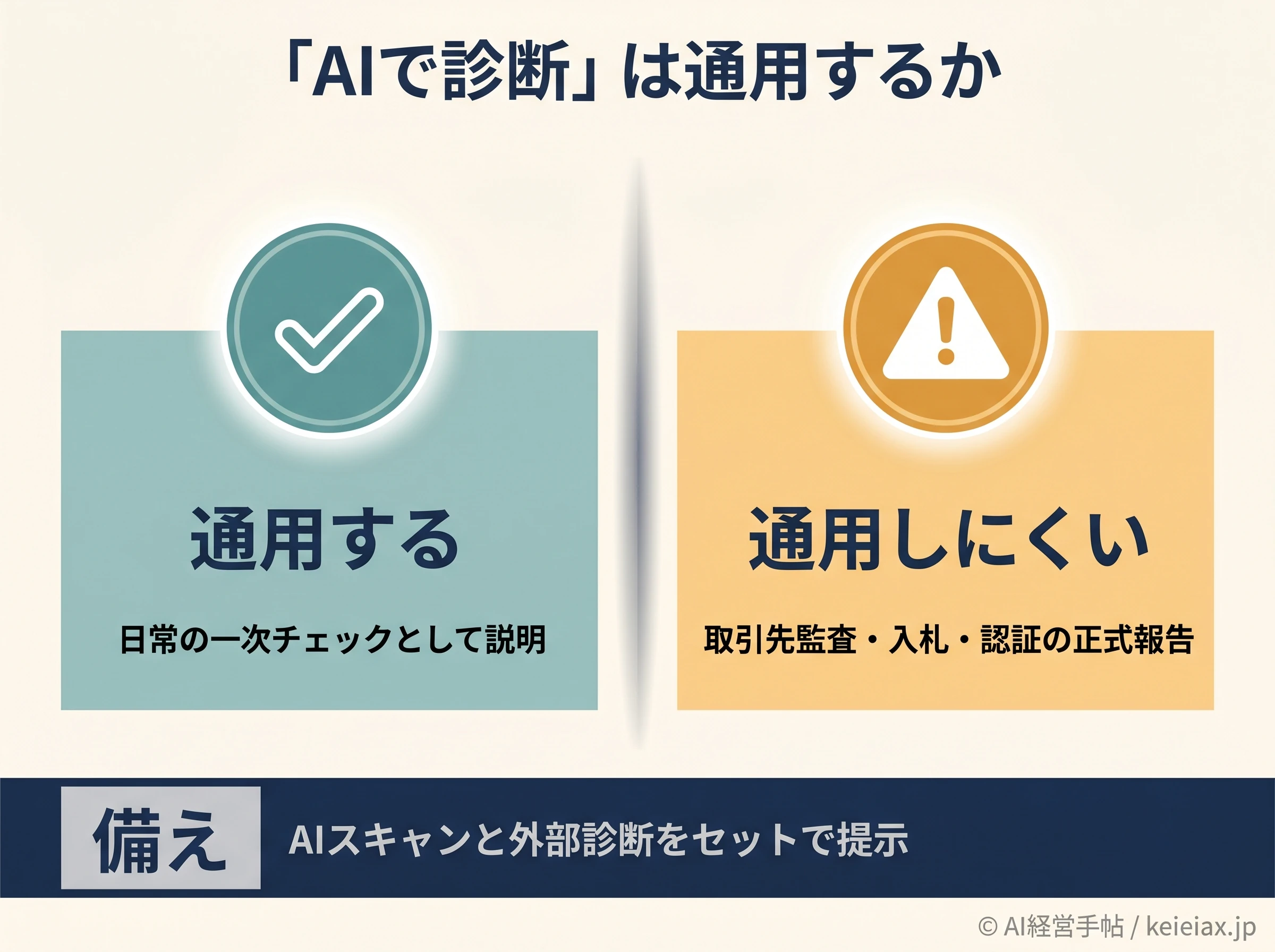
「AIで診断している」が通用する場面・しない場面
線引きはシンプルです。
日常の品質管理として「AIで一次チェックしている」と説明するのは妥当です。一方で、正式な脆弱性診断の報告書を求められる場面(取引先監査・入札・認証取得など)では、確率的でベータのAIスキャン単独では通用しにくいと考えるべきでしょう。
補足監査で問われたら、AIスキャンの記録と外部の正式診断報告をセットで提示できる体制を先に作っておくと、説明に困りません。責任の所在(AIは補助・最終判断は人)も書面で明確にしておきましょう。
よくある誤解と費用感の整理
最後に、導入判断を鈍らせがちな誤解をほどいておきます。
事実に立ち返るほど、判断は軽くなります。
回避つまずきやすい5つの誤解
「Claudeのチャットに貼れば診断になる」
別物です。本体はGitHub連携とデータの流れの解析を伴う専用機能です。
「中小企業でもすぐ本体を使える」
本体はEnterprise対象で、Team・Maxは近日(時期未公表)。まずは/security-reviewが現実的です。
「AIが脆弱性を全部見つける」
CSRFのような文脈依存の弱点は見落とし得ます。人と外部診断の併用が前提です。
「信頼度が高いパッチは自動で当ててよい」
人間承認なしには適用されない設計。テストは必須です。
「どんなコードでもスキャンできる」
自社所有でGitHub上のコードに限られます。
費用感も誤解されがちです。
公式は「スキャンはトークンの直接コストのみ、追加のプラットフォーム手数料はない」としています。少額から試せる一方、対象を広げ高頻度で回すと従量で膨らむため、予算上限と範囲の管理がそのまま費用管理になります。実額はコードの規模で変わるので、最新の条件は公式でご確認ください。
出典: Claudeヘルプセンター「Claude Securityを使用する」
Claude Security使い方に関するよくある質問
QClaude Securityとは何ですか?
AAnthropicが提供する、コードの脆弱性を見つけて修正パッチ案まで出す専用ツールです。2026年4月30日にClaude Enterprise向けのパブリックベータが始まり、上位モデルのClaude Opus 4.7で動きます。検証は多段階で行われ、修正は人間が承認するまで適用されません。
Q中小企業でもClaude Securityを使えますか?
A本体のパブリックベータはClaude Enterprise対象で、Team・Maxは近日提供予定(2026年6月時点で時期は未公表)です。中小企業はまず、個人の有料プラン(Pro・Max)で使える/security-reviewコマンドから試すのが現実的です。
Q信頼度スコアや自動生成パッチを、そのまま本番に当てて大丈夫ですか?
Aいいえ。Claude Securityは人間の承認なしに修正を適用しない設計で、パッチはレビュー用のブランチとして提案されます。テストやステージングで動作を確かめ、人間が承認してから本番に取り込んでください。
QClaude Securityはどんなコードでもスキャンできますか?
A自社が所有しスキャンの権利を持つコードで、かつGitHubにあるリポジトリのみが対象です(現時点)。第三者が所有するコードやオープンソースのコードはスキャンできません。
QAIの脆弱性診断に限界はありますか?
Aあります。国内専門会社の検証では、Claude CodeもCodex Securityも、SAML実装におけるCSRFトークン漏洩を見落とした事例が報告されています。スキャンは確率的で実行ごとに結果が変わるため、人間レビューや外部診断との併用が前提です。
QClaude Securityの料金はいくらですか?
A公式にはスキャンが「トークンの直接コストのみ」で課金され、追加のプラットフォーム手数料はありません。実額は対象コードの規模やトークン消費で変わるため、予算上限の設定が費用管理の要になります(2026年6月時点・最新は公式でご確認ください)。
Q取引先監査で「AIで脆弱性診断しています」と説明して通用しますか?
A日常の一次チェックとしては有効です。ただし確率的でベータであり、公式も「手動レビューを補完するもので置き換えではない」としているため、正式な診断報告が必要な場面では外部の正式診断と役割分担するのが現実的です。
まとめ|小さく試し、限界は外部診断で埋める
Claude Securityの正体は、コードを研究者のように読み、脆弱性と直し方を人間の承認前提で提案するツールです。
速く何度も回せる一方で、GitHub限定・自社所有のみ・確率的・ベータという制約があり、文脈依存の弱点は見落とし得ます。
経営者の次の一手は、立場で分かれます。
Enterpriseがあるなら、1リポジトリ・予算上限つきで限定的にパイロット。それ以外なら、/security-reviewで先行検証しつつ、GitHub集約と外部診断との役割分担を準備。そしてどの立場でも、AIスキャンは一次検出、最終判断は人、正式保証は外部診断という三段の設計を崩さないこと。
この順番なら、過剰な期待にも過度な警戒にも振り回されずに、AI脆弱性診断を業務へ組み込めるはずです。