AutoDANとは
AutoDANとは、人の手で作られてきた脱獄プロンプト(DAN)を、機械が自動でつくり出せるようにした攻撃手法です。2023年10月に研究者が公表しました。意味の通る自然な文章を保ったまま安全装置をすり抜けようとする点が特徴で、不自然さを手がかりに怪しい入力を弾く防御に、引っかかりにくいよう工夫されています。
なぜ自然な文章のまま効いてしまうのか
AutoDANの肝は、遺伝的アルゴリズム(生物の進化をまねて、文章を少しずつ変えながら効くものを選び抜く探索のやり方)で攻撃文を自動生成する点にあります。世代を重ねるごとに、安全装置をすり抜けやすい言い回しへと”進化”させていく仕組みです。出来上がるのは記号の羅列ではなく、人が読んでも意味の通る自然な文章。見た目の不自然さで怪しい入力をはじく防御の網に、かかりにくいのが厄介なところでしょう。
敵対的サフィックス攻撃との違い
同じ自動生成型の敵対的サフィックス攻撃(GCG)と混同されがちですが、見た目がまるで違います。GCGが意味をなさない記号列を質問の末尾に貼り付けるのに対し、AutoDANは自然な文章を保つところが分かれ目です。記号列は機械的なフィルタで比較的見つけやすい一方、自然文をまとうAutoDANは検知が難しくなります。人手のDANを自動化したうえで、読みやすさという”隠れみの”を足した後継、と捉えると整理しやすいはずです。
経営の視点で知っておきたいこと
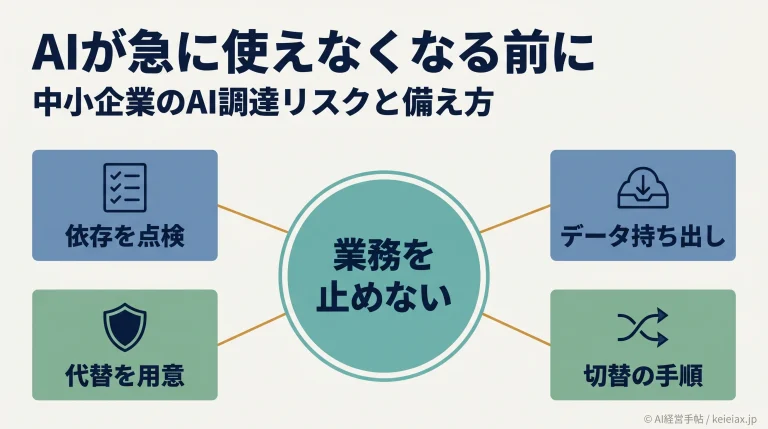
自動化された攻撃は、なぜ厄介なのでしょうか。最大の理由は、人手をかけずに大量の攻撃文を生み出せる点にあります。しかも自然な文章なので、単純なパターン照合では止めにくい。自社で対話AIを使うなら、入力の見た目だけに頼る防御は過信しないのが賢明です。出力側の検査や利用状況の監視を重ね、攻撃の自動化に多層で備えておきたいところ。守りもまた、一枚の壁では足りない時代に入っています。
Topic攻撃文も「進化」する時代に
AutoDANに関するよくある質問
- AutoDANは実際の攻撃ツールなのですか?
- 学術研究として2023年10月に公表された手法です。攻撃に悪用されうる一方、防御側がモデルの弱点を測り対策を強くするためにも使われます。本ページは仕組みを知り防御に役立てる目的で解説しています。
- AutoDANはどんなAIに効くのですか?
- 人の指示に従うよう調整された対話型のAIが主な対象です。研究では、あるモデル向けに作った攻撃文が別のモデルにも効きやすい(転移しやすい)と報告されています。