マルチモーダルとは
マルチモーダルとは、テキスト・画像・音声・動画など、種類の異なる複数の情報をまとめて扱えるAIの性質のことです。文章だけ、画像だけといった一種類に限らず、いろいろな形の情報を一つのAIが横断して理解・生成できます。人が見る・聞く・読むを同時に使うように、AIも複数の“入り口”を持つイメージです。
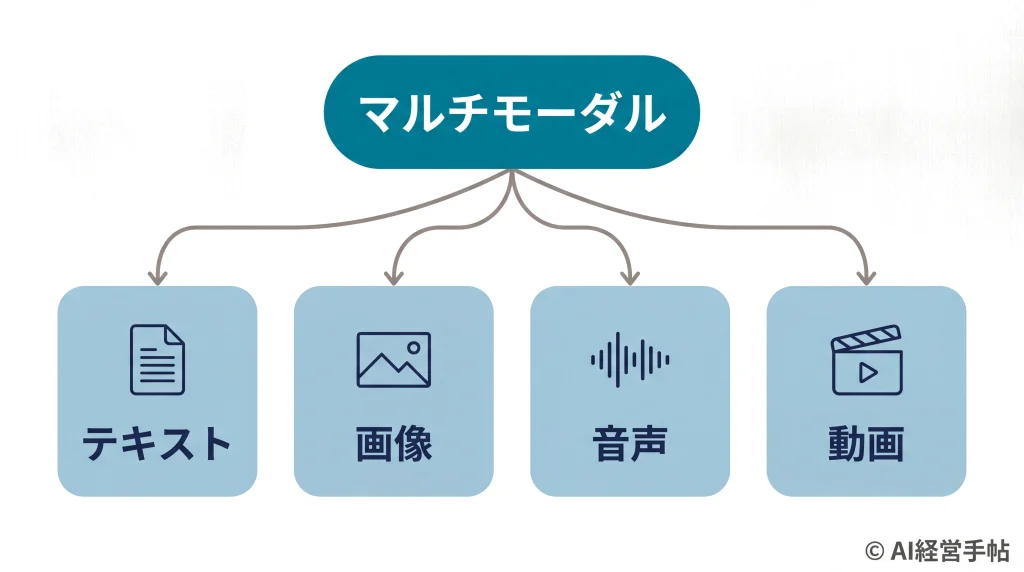
扱えるのは、この4つのモード
マルチモーダルの「モード(モダリティ)」とは、情報の種類のこと。代表的なのは次の4つです。
- テキスト:文章や文字。
- 画像:写真・図・イラスト。
- 音声:話し声や音。
- 動画:動きのある映像。
これらを組み合わせて扱えるので、たとえば写真を見せて「これは何?」と声で聞く、といったことができます。
ユニモーダルとの違い
対になる言葉が「ユニモーダル」です。文章だけ、画像だけ、と一種類しか扱えないAIを指します。以前は、文章を読むAI、画像を見分けるAIと、役割ごとに分かれているのが普通でした。マルチモーダルは、それらを一つにまとめた形といえます。複数の情報を突き合わせられるぶん、より深く、自然に内容をつかめるのが強みです。グラフの画像を見せて、その意味を文章で説明させる、といった芸当もこなします。
どうやって種類をまたぐのか
では、種類のちがう情報を、AIはどう結びつけているのでしょうか。ざっくり言えば、大量のデータから「この画像と、この言葉は、よく一緒に登場する」といった対応関係を学びます。たとえば犬の写真に「犬」という説明が何度も添えられていれば、画像と言葉が同じものを指すと少しずつ覚えていく。こうして、見たものを言葉で説明したり、言葉から絵を思い浮かべたりできるようになります。
身近な使われ方
マルチモーダルは、すでに身近なサービスで使われています。OpenAIのGPT-4oは、文章・画像・音声をまとめて扱えるモデルとして2024年5月に登場しました。GoogleのGeminiも、複数の情報を扱えることを売りにしています。写真の内容を説明させる、資料を読み取って要約させる、声で会話する。こうした使い方が、もはや特別なことではなくなってきました。
ビジネスでの活用が広がる
マルチモーダルは、仕事の進め方も変えつつあります。文字と図表が混じった資料をそのまま読み取って要約する、商品写真から説明文を作る、会議の録音を文字に起こして要点をまとめる。こうした作業を、一つのAIにまとめて任せやすくなりました。これまで情報の形ごとに別々のツールや人手を使っていた手間が、ぐっと減ります。情報がバラバラの形でも、AIがまとめて受け止めてくれるのが、マルチモーダルの実用的な価値です。
Topic人は生まれつきマルチモーダル
考えてみれば、私たち人間は生まれつきマルチモーダルです。犬を「見て」、鳴き声を「聞いて」、「犬」という言葉と結びつける。いくつもの感覚を一度に使って世界を理解しています。長らくAIは、文章なら文章、画像なら画像と“一つの感覚”しか持てませんでした。それが一つのモデルで複数を扱えるようになったのは、人の理解の仕方に一歩近づいた変化、ともいえます。
マルチモーダルに関するよくある質問
- マルチモーダルなAIは、どうやって種類の違う情報を結びつけているのですか?
- 大量のデータから「この画像と、この言葉は、よく一緒に登場する」といった対応関係を学びます。犬の写真に「犬」という説明が何度も添えられていれば、画像と言葉が同じものを指すと少しずつ覚えていく。こうして、見たものを言葉で説明したり、言葉から絵を思い浮かべたりできるようになります。
- ユニモーダルとの違いは?
- ユニモーダルは文章だけ、画像だけと一種類しか扱えないAIです。マルチモーダルはそれらを一つにまとめた形で、複数の情報を突き合わせられるぶん、より深く内容をつかめます。
- マルチモーダルなAIの例は?
- OpenAIのGPT-4o(2024年5月登場)や、GoogleのGeminiが代表例です。文章・画像・音声などをまとめて扱え、写真の内容を説明させる、声で会話する、といった使い方ができます。