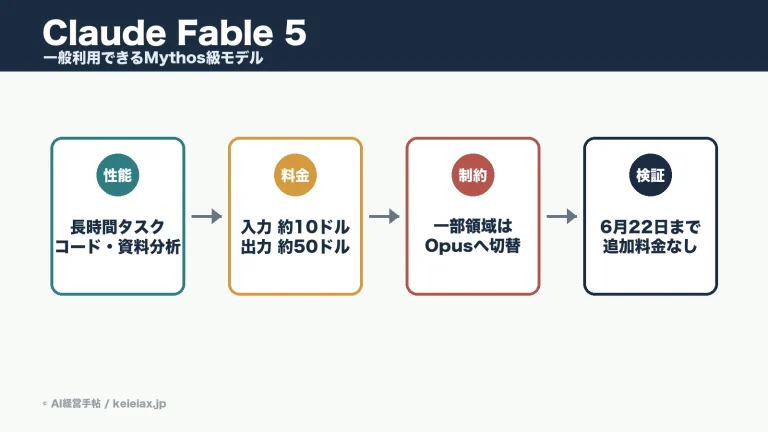
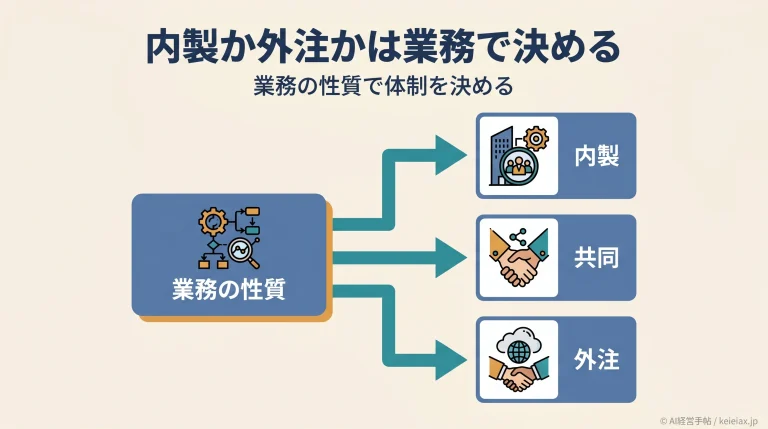
TD-Gammonとは
TD-Gammonとは、時間差分学習とニューラルネットワークでバックギャモンを学んだ、強化学習の古典的な成功例です。人が正解を一手ずつ教えるのではなく、自己対戦を通じてゲームの局面評価を学んだことで知られる存在です。
自分との対戦から強くなる発想
時間差分学習は、今の予測と次の状態から見た予測の差を使って学ぶ強化学習の考え方。TD-Gammonでは、この考え方をバックギャモンに使い、ニューラルネットワークが局面の良し悪しを評価するように学びました。大量の正解データを人が用意するのではなく、試行錯誤から判断基準を育てる点が重要です。
ゲームAIの歴史では、Deep BlueやAlphaGoと並べて語られることがあります。ただしTD-Gammonは、探索だけで勝つというより、自己対戦による学習が強さを生んだ例として理解すると、強化学習の流れが見えやすいでしょう。局面評価を人が細かく書き込むのではなく、対戦経験から調整するところに研究上の面白さがあります。
ビジネスのAI活用に置き換えるなら、最初から完全な正解表を作れない仕事で、結果を見ながら判断基準を改善していく発想に近いかもしれません。正解を教えるAIではなく、経験から評価のものさしを育てるAIとして押さえると、現代の強化学習とのつながりも見えてきます。
Topic人間の常識にない手も評価した
TD-Gammonは、人間の棋譜をただ暗記するだけのプログラムではありませんでした。自己対戦から局面評価を学ぶため、人間の定石とは違う手を高く評価し、バックギャモン研究にも影響を与えた例として知られています。
関連用語
TD-Gammonに関するよくある質問
- TD-GammonのTDは何を指しますか?
- TDはTemporal Differenceの略で、日本語では時間差分と訳されます。次の状態を見た予測との差を使って学ぶ考え方で、TD-Gammonの名前にもその学習方法が入っています。
- TD-GammonはAlphaGoと同じものですか?
- 同じものではありません。どちらもゲームAIと学習の歴史で重要ですが、TD-Gammonはバックギャモンを対象にした早い時期の強化学習の成功例として位置づけられます。