チャットGPT情報漏洩の実例まとめ|企業で起きた事故と業務利用で守るべきリスク回避策
チャットGPTで一度ヒヤッとした話を聞くと、対策の見え方がぐっと変わります。
実は入力・提供側・乗っ取りの3つに分けて押さえるだけで、自社の守り方がはっきりしてくる、と聞いたら気になりませんか?

チャットGPT(ChatGPT)を業務で使い始めた現場から、最も多く出る不安が「過去の事故のように、自社の機密や顧客の個人情報を流出させてしまわないか」というものです。実際、2023年にはOpenAI側のシステム不具合で有料会員の決済情報が他者に見えうる状態になり、Samsung電子では従業員が機密ソースコードを入力して社外送信される事案が起きています。
この記事では、実際に起きた漏洩事例を「3つの経路」で整理し、入力禁止情報・今すぐやる設定・プラン選び・社内規程・漏洩時の報告フロー・準拠すべき公的指針まで、読者が今日から動ける具体策として並べます。事実はOpenAI公式・個人情報保護委員会・IPA・経済産業省などの一次ソースで裏取り済みです。
チャットGPTで実際に起きた情報漏洩事例と、そこから見える「3つの経路」
チャットGPTの情報漏洩を「漠然と怖い」で終わらせないために、まず過去の事故を3つの経路に分けて把握します。経路ごとに原因と対策が違うため、混同したまま対策を立てると的を外します。3経路とは、(1) 利用者が機密情報を入力してしまう「入力起因」、(2) 提供側のシステム不具合による「サービス側起因」、(3) アカウントが乗っ取られる「認証情報流出起因」です。
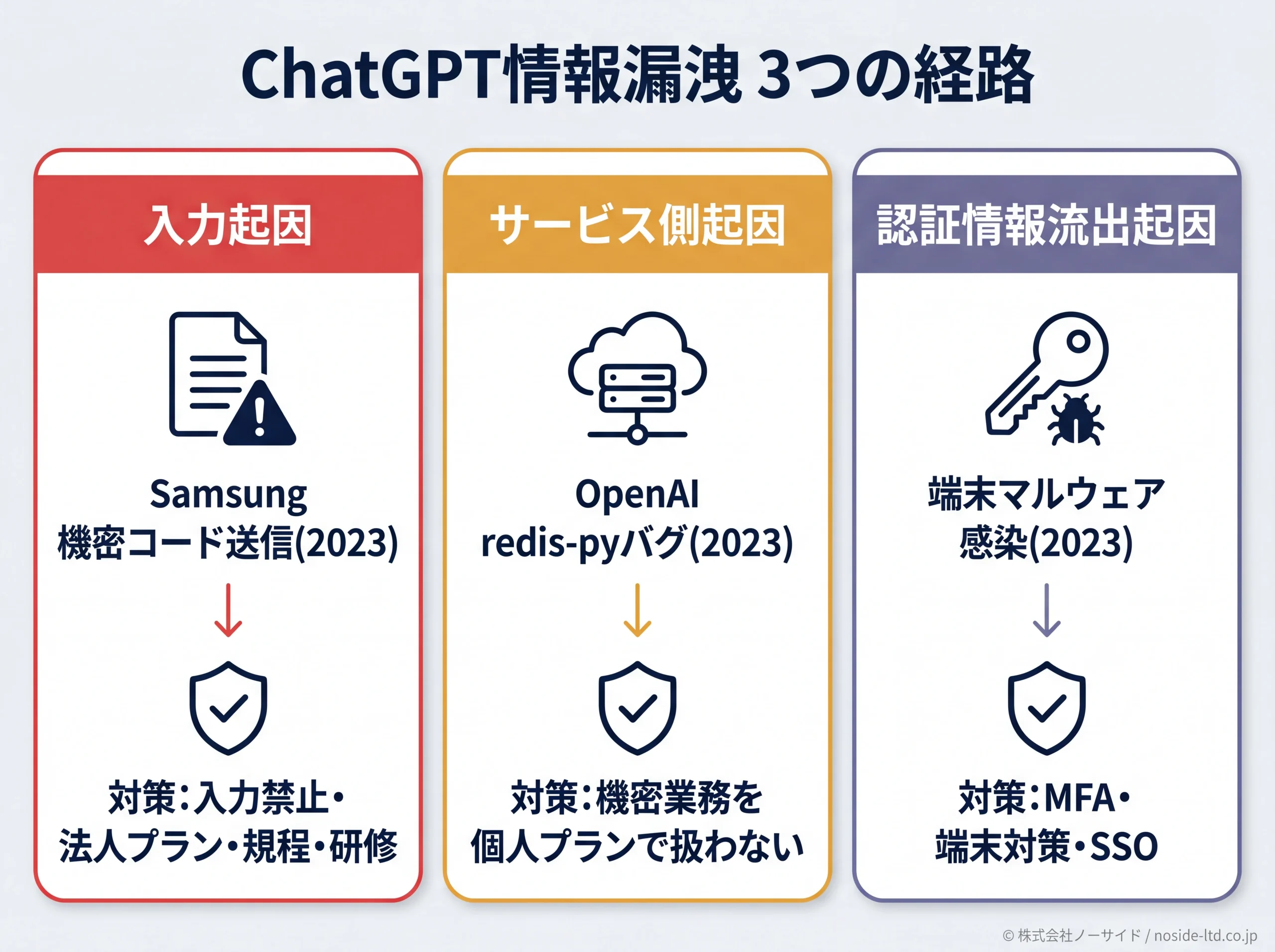
入力起因:Samsung電子の機密ソースコード送信事案(2023年3月)
韓国Samsung電子では2023年3月、従業員が半導体関連のソースコードや社内会議の録音データなどをチャットGPTに入力し、機密情報がOpenAIのサーバへ送信される事案が複数件発生しました(国内外の主要IT報道で広く報じられた事案)。
同社はその後、生成AIの社内利用を一時的に禁止する措置を取っています。
この事故が示すのは、「便利だから」を統制なしで現場任せにすると、入力起因の漏洩が高確率で起きるという現実でしょう。Samsungほどの大手で起きた以上、中小企業の現場でも「私物アカウントでとりあえず使ってしまう」形で同じ経路の漏洩が起きうると考えるべきです。Samsung自身が禁止に振った後に法人プランを検討した経緯は、後述の「規程と環境を整えてから解禁する」発想の典型例といえます。
提供側のシステム不具合起因:OpenAI redis-pyバグ(2023年3月20日)
2023年3月20日、チャットGPTはオープンソースライブラリredis-pyのバグにより、他ユーザーのチャット履歴のタイトルなどが一時的に閲覧可能になる不具合を起こしました。
同事故ではChatGPT Plus加入者の約1.2%に対し、氏名・メールアドレス・請求先住所・カード種別・有効期限・カード番号下4桁が他者に見えうる状態が生じました(完全なカード番号は漏洩していません)。
窓は同日約9時間(米太平洋時間1:00〜10:00)に限定されたものの、これは利用者がどれだけ気をつけても防げない、提供側のリスクだという点が重要です。だからこそ、「無料・個人プランで機密業務を扱わない」「プラン選定でリスク面を小さくする」という、利用者側で制御できる対策にエネルギーを割くべきです。
出典: OpenAI公式声明「March 20 ChatGPT outage: Here’s what happened」(英語・redis-pyバグ事案)
アカウント乗っ取り起因:端末マルウェアによる認証情報流出(2023年6月・Group-IB)
セキュリティ企業Group-IBは2023年6月、ダークウェブ上でチャットGPTアカウントの認証情報10万1,000件超が取引されていたと公表しました(日本でも約660件が確認・複数報道で報じられた調査結果)。
主因はチャットGPT本体の侵害ではなく、利用者の端末がインフォスティーラー型マルウェアに感染し、ブラウザに保存された認証情報が抜き取られたケースです。
ここで誤解しがちなのが「チャットGPTがハッキングされた」という受け取り方です。実際は端末側の防御が破られた結果で、対策の主戦場は多要素認証(MFA)の有効化・端末のマルウェア対策・パスワード管理ツールの側にあります。法人導入の場合は、SSO連携と組織のエンドポイント対策まで含めて初めてこの経路を塞げます。
3経路ごとの対策の主戦場
(1) 入力起因 → 入力禁止情報の徹底+法人プラン+規程+研修
(2) サービス側起因 → プラン選定でリスク面を小さくする(機密業務を個人プランで扱わない)
(3) 認証情報流出起因 → MFA・端末マルウェア対策・SSO連携
チャットGPTに入力してはいけない情報と、今すぐやる設定(オプトアウト・一時チャット)
3経路のうち、利用者側で最も即効性があるのが「入力起因」への対策です。やることは2つで、(A) 何を入れないかをはっきりさせる、(B) 設定を変えて学習対象から外す。順に説明します。
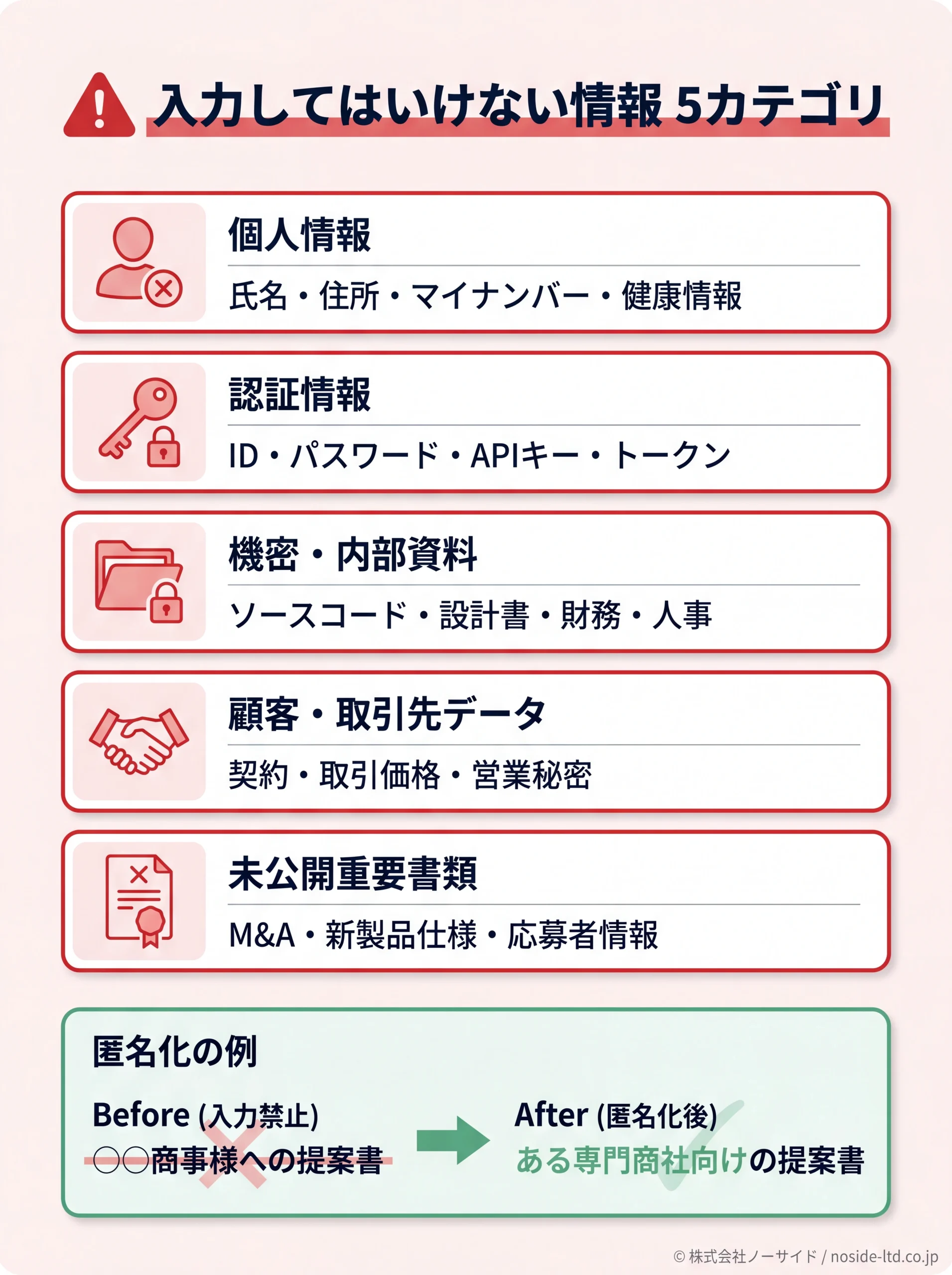
チャットGPTに入力してはいけない情報リスト
個人情報保護委員会(PPC)も2023年6月の注意喚起で「個人情報の入力は必要最小限」を呼びかけています。これに自社内の機密情報・契約情報を加えると、入力禁止情報の最低ラインは次の5カテゴリです。
- 個人情報:氏名・住所・連絡先・マイナンバー・健康情報など(自社・顧客・取引先問わず)
- 認証情報:ID・パスワード・APIキー・トークン・社内システムのログイン情報
- 機密・内部資料:未公開のソースコード・設計書・財務データ・人事評価・経営戦略
- 顧客・取引先データ:契約内容・取引価格・与信情報・営業秘密に該当するもの
- 未公開の重要書類:M&A資料・新製品仕様・採用選考の応募者情報
これらは入力前に匿名化・抽象化するか、そもそも入れない運用にします。「○○商事様への提案書を作って」ではなく「ある専門商社向けの提案書を作って」と置き換えるだけで、入力起因のリスクは大きく下がります。
出典: 個人情報保護委員会「生成AIサービスの利用に関する注意喚起等について」(2023/6/2)
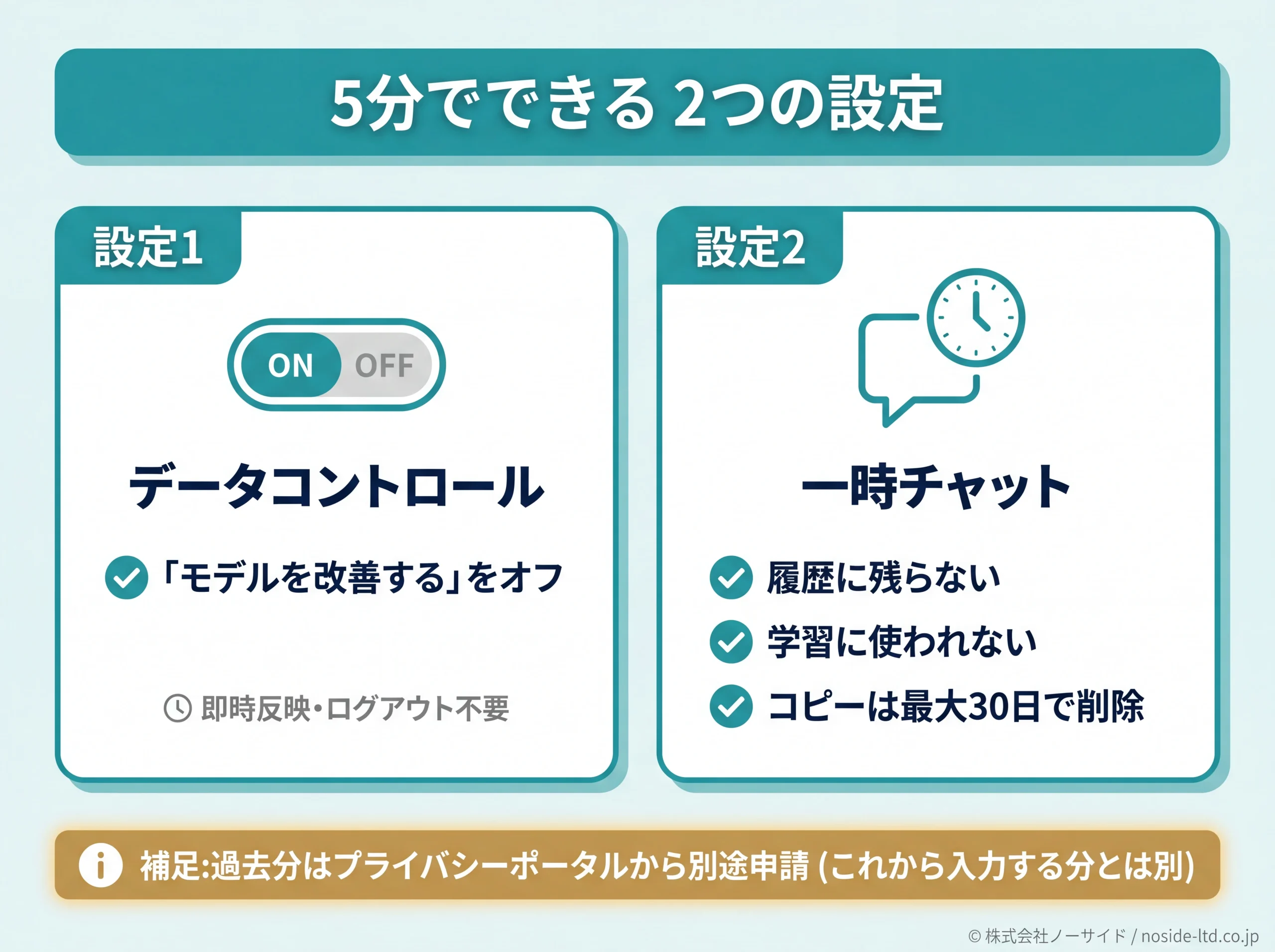
5分でできるデータコントロール設定と一時チャット
個人向けプラン(Free/Plus/Pro)を業務で使わざるを得ない場合、最低限やるべき設定が2つあります。所要は5分以内です。
- データコントロールで学習対象から外す:左下プロフィール → 設定(Settings) → データコントロール(Data Controls) を開き、「すべての人のためにモデルを改善する(Improve the model for everyone)」をオフにする。即時反映でログアウト不要。
- 機密相談は一時チャット(Temporary Chat)で行う:履歴に残らず、モデル改善に使われず、コピーは最大30日間で削除される。機密性の高い相談は迷わずこちらに切り替える。
過去に入力した内容を学習対象から除外したい場合は、OpenAIのプライバシーポータルから申請します(反映に数日〜数週間)。これは「これから入力する分」を外す設定とは別に、過去分を遡って取り下げる手続きです。
出典: OpenAI Help「モデルのパフォーマンスを向上させるためのデータの使用方法」(プラン別データ取扱)
「したつもり」を防ぐ注意点
設定でリスクを下げるときに見落とされやすい3点を押さえておきます。
設定の「したつもり」を防ぐ3点
1. オプトアウトは「これから入力する分」が対象:設定前に入れてしまった機密は別途、履歴削除+プライバシーポータルからの削除申請が必要です。
2. 設定はアカウント単位:同僚や部下が自分の設定でオプトアウトしている保証はないため、組織として安全を担保するなら法人プランで契約レベルの学習除外を取りに行く必要があります。
3. 履歴削除=サーバから即消滅ではない:画面から消えても運営側に残るケースがあり、完全な除外にはプライバシーポータルでの申請が要ります。
機密情報を扱うならどの構成か:Free/Plus・Business・Enterprise・API/Azureの選び方
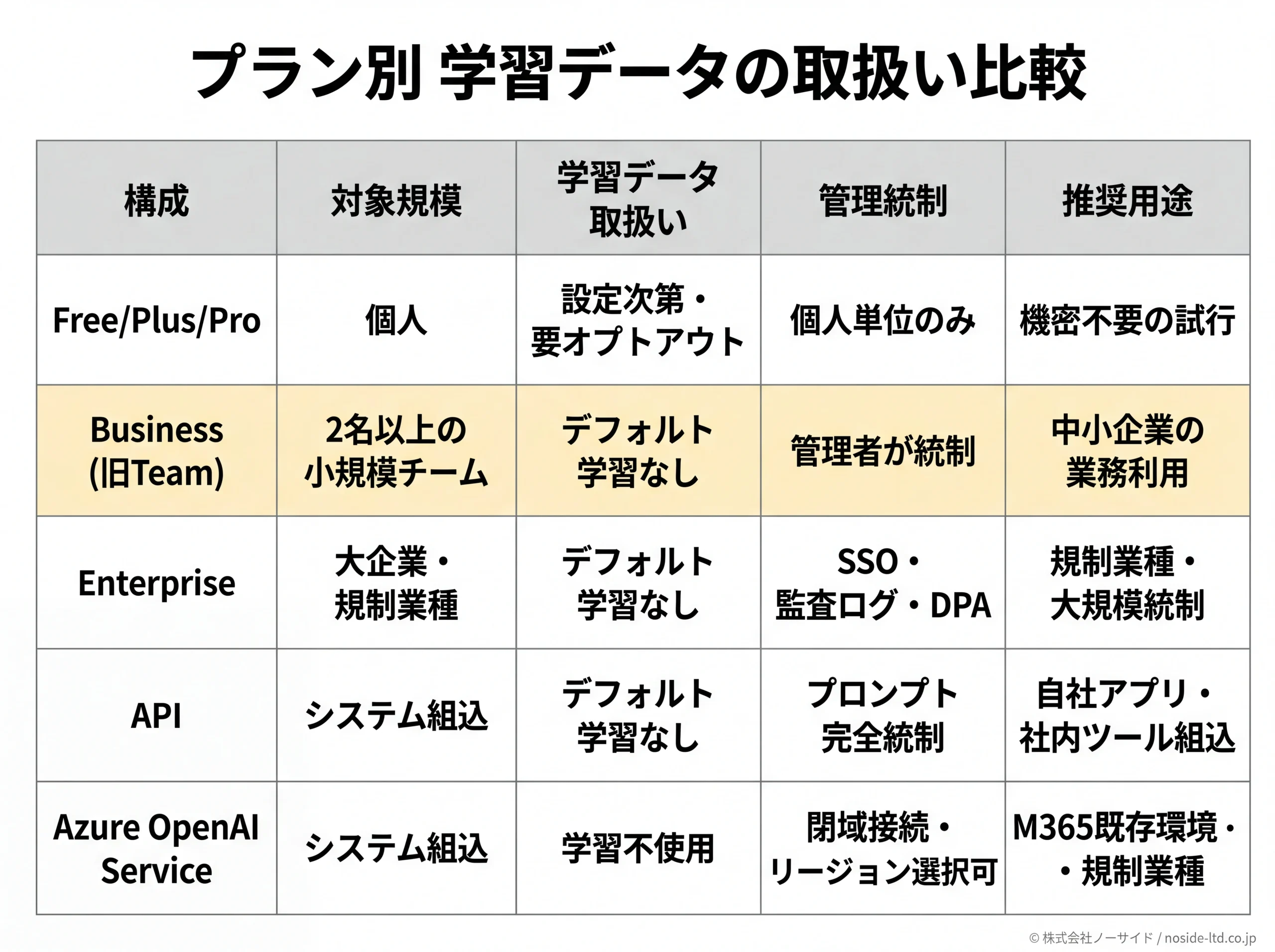
個人プランで設定をいくら頑張っても、「契約レベルで学習に使われない」を取りに行くなら法人プランかAPI構成が前提です。OpenAIのプラン別データ方針は明確で、ChatGPT Business(旧Team)・Enterprise・Edu・APIは入力データをデフォルトでモデル学習に使用しません。Azure OpenAI Serviceも同様で、Microsoft公式が「プロンプト・生成物は基盤モデルの学習に使用しない」と明記しています。
プラン別「学習に使われるか」の違い
| 構成 | 対象規模 | 学習データ取扱 | 管理統制 | 推奨用途 |
|---|---|---|---|---|
| Free/Plus/Pro | 個人 | 設定次第(オプトアウト要) | 個人単位のみ | 個人学習・機密不要の試行 |
| Business(旧Team) | 2名以上の小規模チーム | デフォルト学習なし | 管理者がワークスペース統制 | 中小企業の業務利用 |
| Enterprise | 大企業・規制業種 | デフォルト学習なし | SSO・監査ログ・DPA・カスタム保持 | 規制業種・大規模統制が必要 |
| API | システム組込 | デフォルト学習なし(最大30日不正監視保持) | プロンプト・呼出を完全統制可 | 自社アプリ・社内ツール組込 |
| Azure OpenAI Service | システム組込 | 学習不使用(最大30日不正監視保持) | 閉域接続・リージョン選択可 | Microsoft 365既存環境・規制業種 |
ChatGPT Businessの料金は約20米ドル(年払)〜約25米ドル(月払)/ユーザー/月・最低2名から(2026年4月時点)です。AI系SaaSは改定が速いので、導入検討時は必ず公式の最新価格を確認してください。Enterpriseは個別見積、Azure OpenAIは従量課金です。
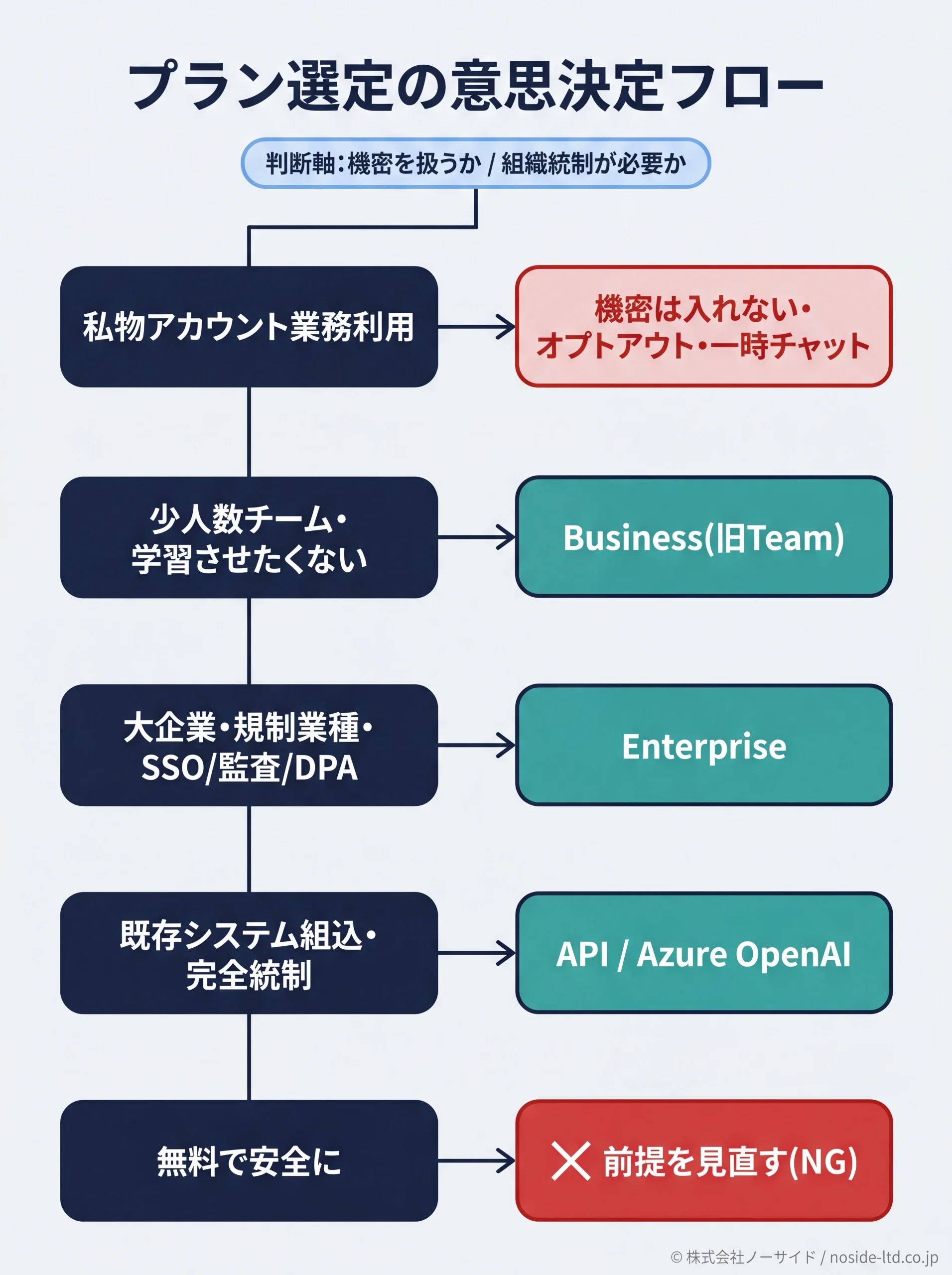
if→結論型の意思決定フロー
自社の状況をif分岐に当てはめれば、現実的な構成は機械的に決まります。
- if個人が私物アカウントで業務利用している → 機密・個人情報の入力は禁止し、最低でもオプトアウト+一時チャット併用。それでも会社の機密は入れない(統制不能のため)。
- if少人数チーム(2名〜)で社内導入し、入力データを学習させたくない → ChatGPT Business(旧Team)。管理者がワークスペースを統制でき、業務データはデフォルトで学習に使われない。
- if大企業・規制業種でSSO・監査ログ・DPA・データ保持ポリシーを要件化 → ChatGPT Enterprise。エンタープライズ級のセキュリティ統制とDPA締結が前提。
- if既存システム・社内ツールにAIを組み込む/プロンプトを完全統制したい → APIもしくはAzure OpenAI Service。Azureは閉域接続・リージョン選択も可能。
- if 「とにかく無料で安全に」を求めている → その前提自体を見直す。無料プランは契約レベルの学習除外を満たさず、安全な業務利用の土俵に立っていない。
判断軸は「機密を扱うかどうか」と「組織として統制が必要か」の2つです。両方Yesなら個人プランは選択肢から外れ、BusinessかEnterprise、もしくはAPI・Azure構成に絞られます。
社内利用ルール・規程の作り方(最低項目とひな形の使い方)
プランを決めても、「使ってよい範囲」と「禁止事項」を文書化しておかないと現場任せに戻ってしまいます。ここでは規程とガイドラインの違いを整理し、最低限盛り込む8項目とJDLAひな形の使い方を示します。
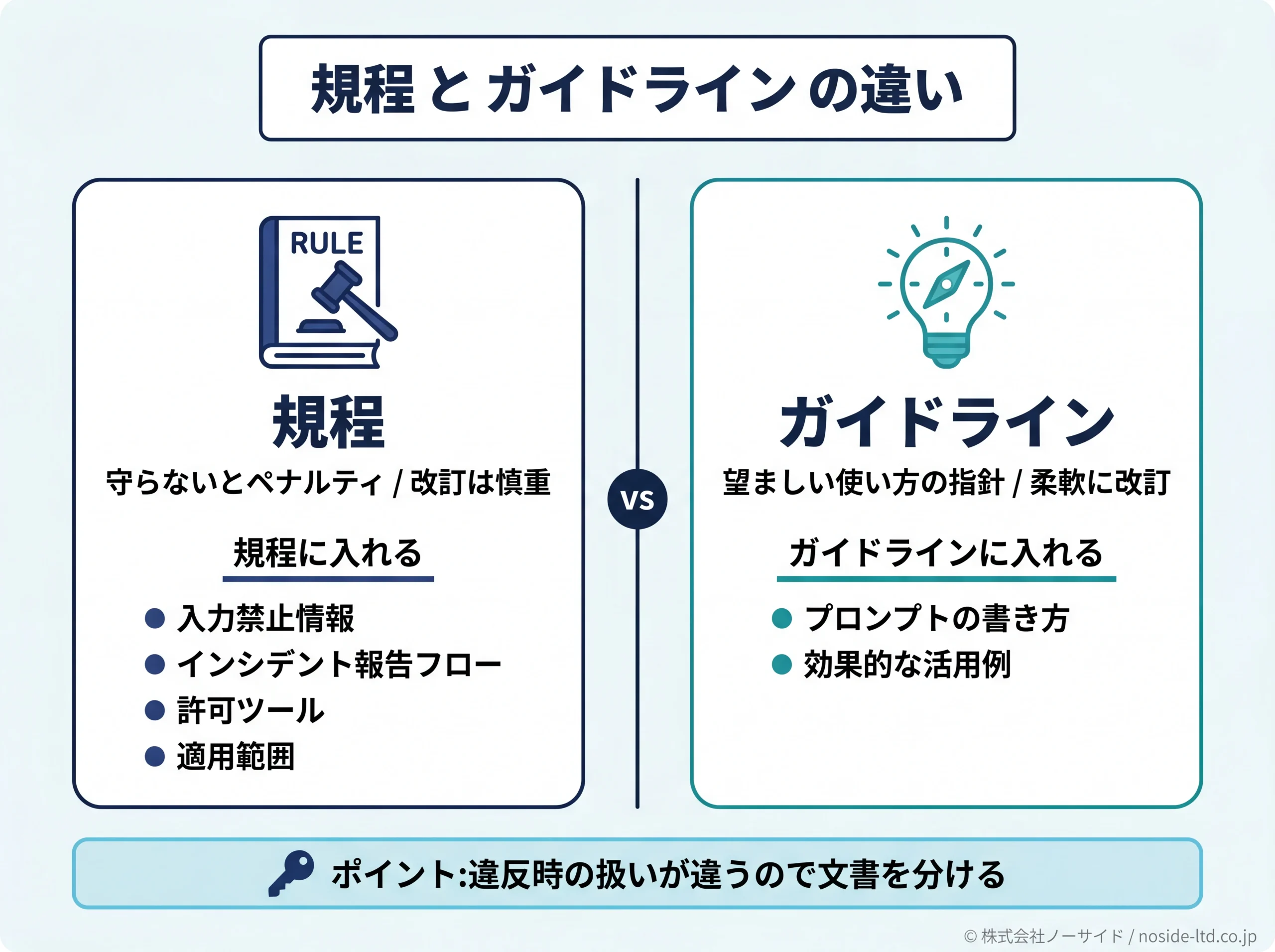
「規程」と「ガイドライン」の違い
この2語は社内文書でしばしば混同されますが、規程は「守らないとペナルティがあるルール」、ガイドラインは「望ましい使い方の指針」です。違反時の扱いが違うので、書く前に決めておくと運用がブレません。
たとえば「機密情報を個人アカウントのチャットGPTに入力した社員に対する処分」を定めるなら規程側に記載し、「効果的なプロンプトの書き方の推奨例」はガイドライン側に分けます。禁止事項は規程・推奨は別文書のガイドラインと整理しておくと、改訂サイクルが違っていても運用がブレません。
規程に盛り込む8項目とJDLAひな形の活用
日本ディープラーニング協会(JDLA)が無料公開している「生成AIの利用ガイドライン」ひな形は、多くの企業が自社規程の土台に使っています。ここから不要部分を削り、自社の特殊事情を足すのが最短です。最低限盛り込む項目は次の8つです。
チャットGPT利用規程に盛り込む8項目チェックリスト
□ 目的と適用範囲:誰の・どの業務に適用するか
□ 用語の定義:規程/ガイドライン/生成AI/プロンプト等
□ 利用が許可されるAIツール・プラン:私物アカウントの業務利用可否を明記
□ 入力禁止情報の明示(最重要):個人情報・認証情報・機密・顧客データ・未公開重要書類
□ 出力物の取り扱い:無検証での業務利用禁止・著作権・事実確認
□ ログ・データ管理方針:保存先・保持期間・定期確認
□ インシデント報告フロー:誰に・いつまでに・どう報告するか
□ 教育・研修と周知:年1回の見直し等
このうち「入力禁止情報」と「インシデント報告フロー」は具体名・連絡先までを書き切るのがポイントです。抽象表現にすると現場が判断に迷い、結局守られません。
出典: 日本ディープラーニング協会(JDLA)資料室「生成AIの利用ガイドライン」(ひな形・無料公開)
他社動向:3つの類型と「安全な環境を作って解禁」の発想
他社の規程・運用は大きく3類型に分かれます。
- 全面禁止:機密漏洩リスクを重く見て、業務利用を全面禁止する企業。Samsung電子の初期対応がこのパターン。
- 条件付き許可:個人プランを禁止し、法人プランの限られた業務でのみ許可する企業。多くの中堅企業がこの形に落ち着いています。
- 安全な独自環境を構築して解禁:自社専用のAI環境を構築して、学習に使われない土俵を社内に作る大企業のパターン。
セブン&アイ・ホールディングスは、ユーザーローカルChatAIなどの自社独自のAI環境を構築して活用し、リスクチェック業務の時間を約70%削減したと公表しています(企業自己申告値・公開導入事例)。「禁止」一辺倒ではなく、安全な土俵を用意してから解禁するという発想は、中小企業がそのまま真似はできなくても、「法人プラン契約+規程+研修」で同じ思想を再現できます。
万一漏らしてしまったときの対処と報告フロー
予防だけでなく「漏らしてしまった後」の動きも決めておきます。慌ててから手順を考えても遅く、個人情報保護法は速報3〜5日・確報30日の期限を定めているため、初動の遅れがそのまま法令違反に直結します。
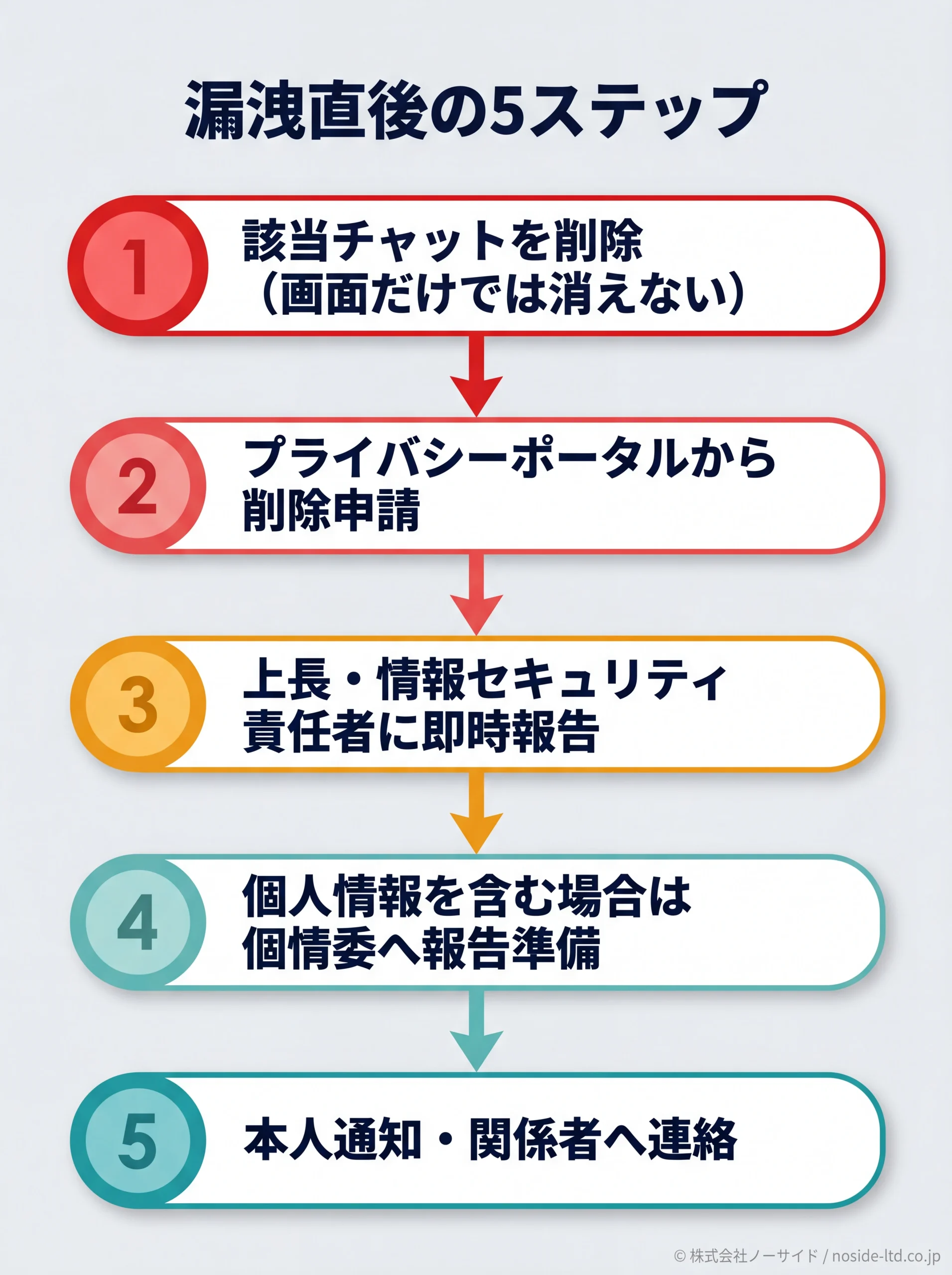
漏洩直後の動き(5ステップ)
- 該当チャットを削除:まず画面上の履歴を消す(これだけではサーバから消えない点に注意)。
- OpenAIのプライバシーポータルから削除申請:完全な除外にはこの申請が必要。反映に数日〜数週間。
- 上長・情報セキュリティ責任者に即時報告:規程に定めた連絡先へ、入力内容・日時・対象データを整理して報告。
- 個人情報を含む場合は個人情報保護委員会への報告準備:要件該当の判定と報告書作成(次項)。
- 本人通知・関係者への連絡:顧客・取引先の情報が含まれていた場合、要件に応じて本人通知を実施。
個人情報保護法の漏えい報告・本人通知
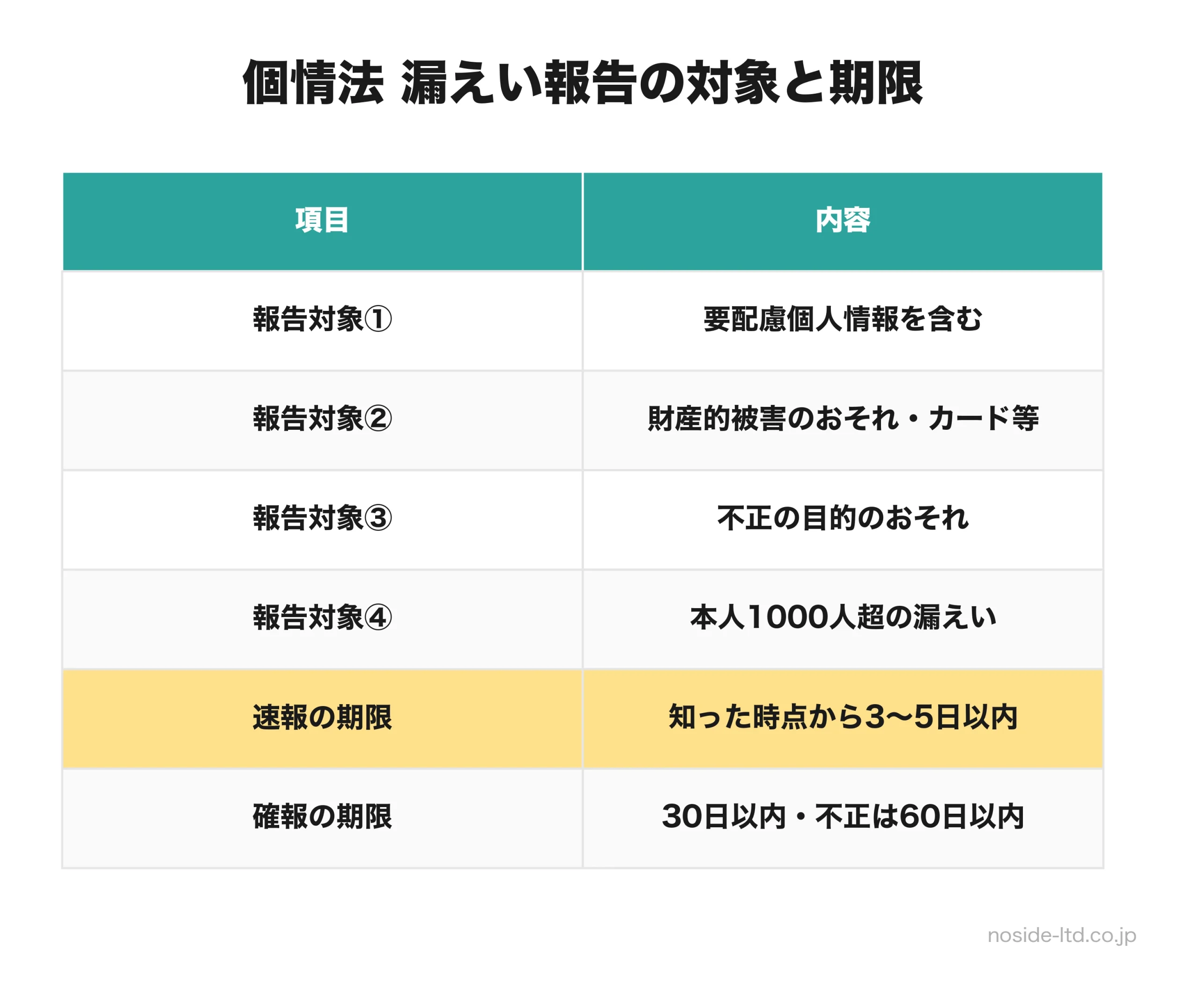
個人情報保護法は2022年4月から漏えい等報告・本人通知を義務化しています。報告対象は次の4類型のいずれかに該当する場合です。
- 要配慮個人情報(人種・信条・社会的身分・前科前歴・病歴等)が含まれる漏えい
- 財産的被害のおそれがある漏えい(クレジットカード情報等)
- 不正の目的をもって行われたおそれがある漏えい
- 本人の数が1,000人を超える漏えい
報告期限は速報が知った時点からおおむね3〜5日以内、確報が30日以内(不正の目的のおそれがあるケースは60日以内)です。本人通知も「事態の状況に応じて速やかに」行う必要があります。機密情報の入力=必ず報告ではない点(自社の機密だけなら個情法上の報告義務は出ない)も含めて、規程の中で判定フローを書いておくと現場が迷いません。
出典: 個人情報保護委員会「漏えい等報告・本人への通知の義務化について」
準拠すべき公的指針はどこを見ればよいか
自社規程の根拠条文として、日本の公的指針は次の3点を押さえれば十分です。海外規制(EU AI Act・イタリアGaranteの一時停止等)もありますが、日本企業の実務判断はまず国内指針を主軸に組み立てます。
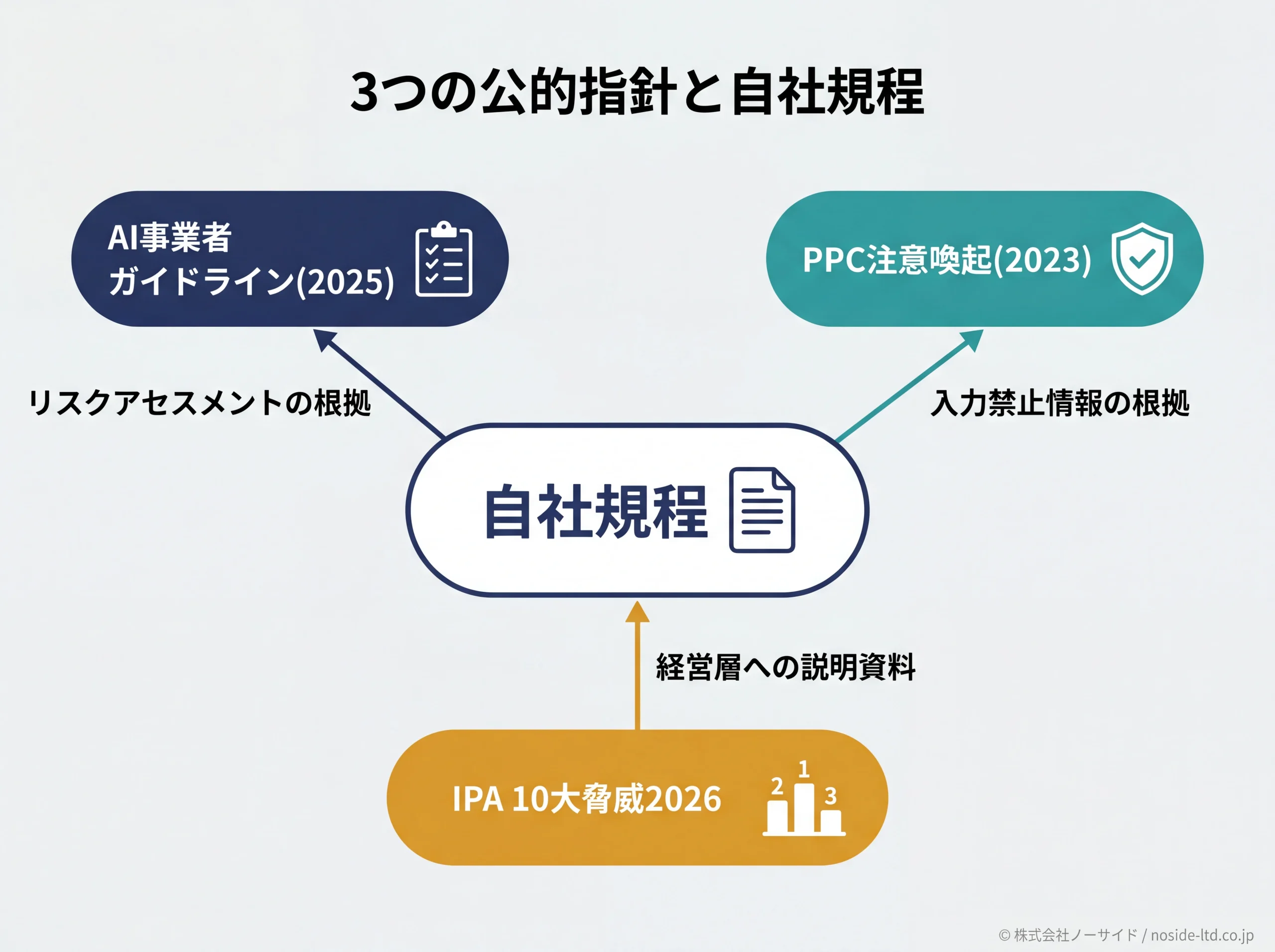
3指針の使い分け早見
| 指針 | 位置づけ | 自社で見るべきポイント |
|---|---|---|
| AI事業者ガイドライン(第1.1版・2025/3/28) | 総務省/経済産業省の実践指針(ソフトロー) | 開発者/提供者/利用者の三層で何をすべきか |
| PPC「生成AIサービスの利用に関する注意喚起」(2023/6/2) | 個人情報保護委員会の注意喚起 | 個人情報の入力最小化・要配慮個人情報の扱い |
| IPA「情報セキュリティ10大脅威2026」 | 独立行政法人IPAの脅威ランキング | AI利用リスクが組織向け第3位に初選出。経営層への説明資料として使える |
AI事業者ガイドラインは法的拘束力こそありませんが、有事の説明責任・社会的信用の観点で「準拠していること」が問われます。「努力目標だから関係ない」という整理は経営判断としてリスクです。自社規程の前文に「本規程はAI事業者ガイドライン第1.1版(2025年)の利用者向け事項に準拠する」と明記しておくと、有事の説明責任を最小コストで担保できます。
出典: 経済産業省「AI事業者ガイドライン」 / IPA「情報セキュリティ10大脅威2026」
自社規程への落とし込み方
3指針は読み込むだけで終わらせず、自社規程の各項目に対応する条文を引用する形で落とし込みます。たとえば「入力禁止情報」の根拠としてPPC注意喚起を、「リスクアセスメント」の根拠としてAI事業者ガイドラインを、「経営層への報告フォーマット」の参考としてIPA10大脅威を引くと、規程の説得力と監査対応の両方に効きます。
規程は年1回の見直しを前提に作っておくと、ガイドラインの版改訂(現行は第1.1版・2025年)や、新しいプラン名称への切替(Team → Businessなど)にも追従しやすくなります。
よくある質問(FAQ)
QチャットGPTで実際に情報漏洩は起きていますか?
Aはい。2023年にOpenAI側のシステム不具合(redis-pyバグ)でChatGPT Plus利用者の約1.2%の決済情報の一部が他者に見えうる状態になり、また従業員が機密情報を入力して社外に送信された企業事案(Samsung等)も報告されています。
QチャットGPTに入力してはいけない情報は何ですか?
A個人情報、ID・パスワード等の認証情報、未公開の機密・内部資料、顧客や取引先のデータ、契約書・経営戦略などの重要書類です。入力前に匿名化・抽象化するか、そもそも入力しない運用にします。
Q入力した内容をAIに学習させない設定はありますか?
Aあります。個人向けは設定の「データコントロール」で「すべての人のためにモデルを改善する」をオフにします。Business(旧Team)・Enterprise・API・Azure OpenAI Serviceは入力データをデフォルトで学習に使いません。
Q機密情報を扱う業務ではどのプランが安全ですか?
A少人数ならChatGPT Business、規制業種・大企業ならEnterprise、システム組み込みならAPIまたはAzure OpenAI Serviceが現実的です。無料・個人プランでの機密業務利用は避けます。
Q社内ルール(規程)には最低限何を入れればよいですか?
A目的・適用範囲、用語定義、許可ツール、入力禁止情報、出力物の取り扱い、ログ管理、インシデント報告フロー、教育・研修の8項目です。JDLAが無料公開するひな形を土台に自社向けに調整できます。
Q万一、機密情報を入力してしまったらどうすればよいですか?
Aまず該当チャットを削除し、OpenAIのプライバシーポータルから削除申請を行い、上長・関係者へ報告します。個人情報保護法の要件に該当する場合は、個人情報保護委員会への報告(速報3〜5日・確報30日)と本人通知が必要です。
Q準拠すべき公的な指針はどこを見ればよいですか?
A総務省・経済産業省「AI事業者ガイドライン(第1.1版・2025年)」、個人情報保護委員会の注意喚起・漏えい報告ルール、IPA「情報セキュリティ10大脅威2026」が中心です。