RSP(アールエスピー)とは
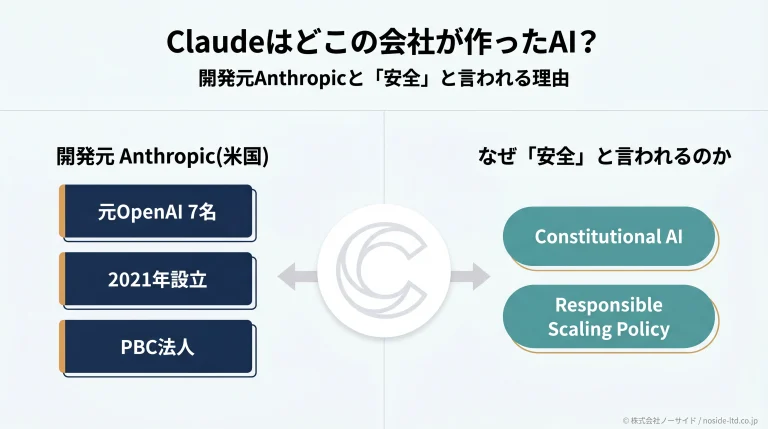
RSPとは、最先端のAIがもたらしうる重大なリスクに備えて、Anthropic(対話AI「Claude」の開発元)が自主的に定めた安全管理の方針です。AIの能力が一定の危険な水準に近づいたら、それに見合った安全対策を必ず講じる、という「能力に応じて手綱を締める」考え方を指します。法律で課された義務ではなく、開発する企業が自分自身に課したルールという点が特徴になります。

英語表記:Responsible Scaling Policy
安全レベル「ASL」で対策を一段ずつ厳しくする
RSPの中心にあるのがASL(AI Safety Levels=AI安全レベル)という段階の考え方です。AIの危険度に応じて1から4までの水準を設け、上の段に上がるほど厳しい安全対策を義務づけるしくみになっています。たとえばASL-2はいまの一般的な大規模言語モデルが当てはまる基準です。ASL-3になると、化学・生物・核などの兵器の悪用を実際に後押ししかねない水準とされ、より厳重な守りが求められます。
守りは大きく2系統に分かれます。AIの設計図にあたる「重み」が盗み出されないようにするセキュリティ面の対策と、危ない使われ方をブロックする運用面の対策です。能力が上がるほど、この両面を一段ずつ強化していきます。実際に2025年5月には、Claude Opus 4というモデルで初めてASL-3の保護が発動されました。確実に危険水準を超えたとは断定できないものの、リスクを否定しきれないため予防的に一段上の守りに切り替えた、という慎重な運用がうかがえます。
他社の枠組みや法規制との違い
同じ発想の枠組みは他社にもあります。OpenAIの「Preparedness Framework」やGoogle DeepMindの「Frontier Safety Framework」も、AIの能力に応じて安全対策を強める自主的なしくみです。ただし呼び名や区分は各社で異なり、AnthropicはASL、他社はそれぞれ別の用語を使っています。考え方は近くても、横並びでそのまま比較できるわけではありません。
もう一つ大切な区別が、RSPは法律ではなく、あくまで企業の自主的な方針だという点です。国や地域が定めるEU AI法のような規制とは性質が違います。だから「方針を公表している=安全が保証されている」とは限りません。約束をどう実行しているかを継続して見ていく姿勢が欠かせない、という点に注意が必要です。
経営から見た使いどころ
取引先や委託先として検討するAIベンダーが、こうした能力ベースの安全方針を公開し、更新し続けているかは、ガバナンス上のチェック項目になります。RSPは一度決めて終わりではなく、改訂を重ねる「生きた文書」として運用されているのが実情です。2023年9月に初版が公表され、その後も複数回にわたって改訂が重ねられてきました。ベンダー選定や社内の説明責任を考えるうえで、安全への向き合い方を読み解く手がかりとして使えます。
Topic「ASL」はバイオの安全基準をまねて名づけられた
ASL(AI安全レベル)という呼び名は、研究所で危険な病原体を扱うときの「バイオセーフティレベル(BSL)」になぞらえて作られたと、Anthropic自身が説明しています。病原体の危険度が上がるほど実験室の封じ込めを厳重にするのと同じ発想で、AIの能力が上がるほど守りを一段ずつ引き上げる。危険物を扱う科学の現場で積み上げられた知恵を、AIの安全管理に持ち込んだわけです。
RSPに関するよくある質問
- RSPに従えば、そのAIは完全に安全だと考えてよいですか?
- そうとは限りません。RSPは能力に応じて対策を強める自主的なしくみで、安全を100%保証するものではありません。2025年に予防的にASL-3が発動された例のように、リスクを否定しきれない段階では慎重に守りを固める運用が前提です。
- OpenAIやGoogleにも同じような枠組みはありますか?
- あります。OpenAIのPreparedness Framework、Google DeepMindのFrontier Safety Frameworkが同じ系統です。ただし呼び名や段階の区分は各社で異なり、そのまま横並びで比較はできません。
- いまのAIはASLのどの段階にありますか?
- 一般的な大規模言語モデルはASL-2が基準とされています。2025年5月にはClaude Opus 4で初めて一段上のASL-3の保護が予防的に発動されました。能力の高まりに応じて段階が引き上げられていきます。