「ハルシネーションしないでください」は効くのか?ChatGPTに正確な回答をさせるプロンプト設計
ChatGPTに「ハルシネーションしないで」と添えたこと、ありませんか?
実はあの一言、半分は効いて半分は効きません。
なぜ効かないのかと、代わりに何を指示すれば業務で使える正確さになるのかが分かれば、誤情報の事故はぐっと減らせます。
ChatGPTに「ハルシネーションしないでください」「嘘をつかないで」と一言添えてから質問する。一度はやってみた使い方ではないでしょうか。
ただ、それで本当に誤情報が止まるのか、確信が持てないまま業務に使っている方も多いはずです。
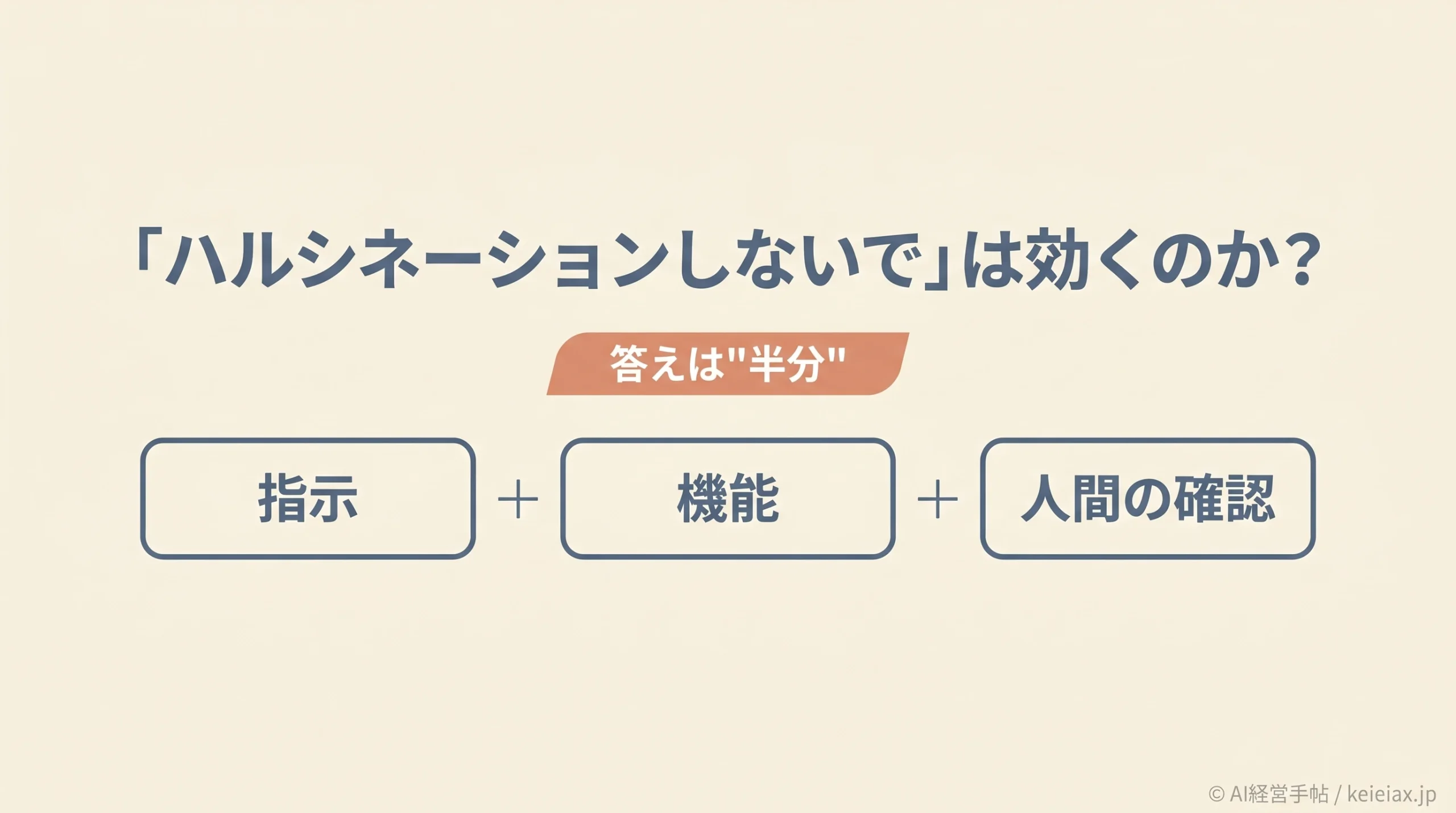
結論から言えば、この直接指示は“半分”だけ効きます。
効く理由と効かない理由を生成AIの仕組みから整理したうえで、代わりに何をどう指示・設定すれば、業務で使える精度に近づくのかまで具体的に示します。誤った情報を真に受けて取引先や社内に出してしまう事故を、現実的なところまで減らすのが狙いです。
結論:「ハルシネーションしないで」は”半分”効く
まず事実から確認します。「ハルシネーションしないで」と書くと、一定の効果はあります。
実際に試すと何が起きるか
第三者が実際に検証した例があります。GPT-4o miniに、実在しない架空のバンド名について尋ねたところ、最初は「4人組です」ともっともらしい嘘を返しました。
ところが「ハルシネーションしないで」と指示したうえで同じ質問をすると、今度は「申し訳ありませんが、そのバンドは知りません。存在しないかもしれません」と正直に答えたのです。
つまり、直接指示によってAIが「知らない」と言いやすくなったのは、確かに見て取れます。
出典: SIOS Tech Lab「chatGPTに『ハルシネーションしないで』とお願いしたら効果がある?」
効果の正体は「不確実性を言える様にする」こと
ここで注意したいのが、効果の中身です。直接指示が変えたのは「捏造そのものが消えた」ことではなく、「自信がないときに、知らないと表明しやすくなった」という点にすぎません。
同じ検証でも、質問が単純すぎると効きが鈍くなる傾向が見られました。指示の有無で結果が安定して変わるわけではなく、「効くこともある」程度の補助手段と捉えるのが正確です。
要点直接指示の正しい位置づけ
「ハルシネーションしないで」は誤情報をゼロにする魔法の呪文ではありません。AIが不確実さを言いやすくなる補助にすぎず、これだけで安心して検証を省くのが最も危険です。
なぜ直接指示だけでは防ぎきれないのか
効果が限定的な理由は、ハルシネーション(幻覚)が起きる根本の仕組みにあります。ここを理解すると、どんな指示が効いてどんな指示が空振りするかの見当がつきます。
嘘ではなく「確率的に選んだ言葉」
ハルシネーションとは、大規模言語モデル(LLM、大量の文章で学習したAI)が、事実と異なる内容を、もっともらしく自信ありげに生成してしまう現象です。
ここで誤解しやすいのですが、AIは「嘘をつこう」としているわけではありません。
生成AIは「次に来る確率が高い言葉」を一つずつ選んでいるだけで、誤りはその過程で出てくる副産物です。
OpenAIの研究者らが2025年9月に公開した論文も、この点を裏づけています。論文は、世の中に一度しか現れないような事実(特定の人物の誕生日など)は統計的な手がかりが乏しく、もっともらしい誤りを選びやすいと説明しています。
実際、この論文では「確信があるときだけ答えよ」と指示しても、あるモデルは同じ人物の誕生日を毎回違う日付で誤答したと報告されています。博士論文のタイトルを尋ねた実験でも、複数のAIがそれぞれ別々の偽のタイトルを自信満々に答えました。
これが、推測を禁じる一言だけでは捏造が止まらない理由です。

出典: OpenAI「Why Language Models Hallucinate」(2025年9月・英語)
「わからない」が損をする採点の罠
もう一つ、根が深い理由があります。AIの賢さを測る多くのテストでは、「わかりません」と答えると0点で、当て推量でも当たれば加点される仕組みになっています。
これは、自信がなくても空欄にせず適当に埋めたほうが得をする試験と同じ構造です。
その採点に最適化された結果、AIは「黙るより、それらしく答えるほうが有利」という癖を身につけてしまいます。
メモだから「嘘をつかないで」という倫理に訴える言い方は、仕組みの上ではずれた指示になりがちです。AIには善悪の意図ではなく、具体的な動作のルールで伝えるほうが効きます。
プロンプトで防げる範囲・防げない範囲
仕組みがわかると、プロンプトの工夫が効く領域とそうでない領域がはっきり分かれます。ここを線引きできるかどうかが、業務での事故率を大きく左右します。
資料の中で完結する作業は、ほぼ防げる
要約、言い換え、与えた文章の校正、アイデア出しのように、答えが「渡した情報の中」で完結する作業は、プロンプトの工夫でかなり安定します。
AIが外部の知識を持ち出す必要がないため、捏造の入り込む隙が小さくなるからです。
後述する参照テキストの添付と組み合わせれば、ここはほぼ実用域に乗ります。
外部の事実は、最良のモデルでも残る
一方で、固有名詞、数値、日付、出典といった「外部にある事実」を答えさせる質問は、プロンプトだけでは防ぎきれません。
どのくらい残るのか。OpenAIが公表したGPT-5のシステムカードによると、難しい事実質問を集めたテストでは、じっくり考える推論モードでも、回答の約4割でハルシネーションが起きていました。
最新の高性能モデルでさえ、難問では4割を取りこぼすという事実は、頭に入れておく価値があります。

プロンプトで防げる範囲の早見表
| 作業の性質 | プロンプトで防げるか |
|---|---|
| 要約・言い換え・校正(資料内で完結) | ほぼ防げる |
| アイデア出し・文体変換 | ほぼ防げる |
| 固有名詞・数値・日付・出典の事実 | 防ぎきれない(要・検証) |
| 最新情報・時事・製品仕様 | 検索機能が必須 |
注意プロンプトは確率を偏らせるだけ
どんなに上手な指示でも、誤りの確率を下げられてもゼロにはできません。事実を扱う質問では「プロンプト+機能+人間の確認」をひとそろいにする前提で設計してください。
正確性を上げる指示の設計
では、「しないで」の代わりに何を指示すればよいのか。
ここからは、OpenAI公式が推奨する考え方をもとに、コピペで使える土台まで落とし込みます。
正確性を上げる5つの設計原則
OpenAIの公式プロンプトガイドは、精度を上げる第一の方法として「参照テキストを与え、その中だけで、出典を示して答えさせる」ことを挙げています。これを軸に、現場で効く原則は次の5つに整理できます。
- 参照テキストを渡し、その範囲内で答えさせる(捏造の入り口を断つ最優先策)
- 出典・引用を明示させる(人間が後から検証できる状態にする)
- 不明なら「わかりません」と言う許可を与える(黙る選択肢を用意する)
- 役割と前提、出力の形式を固定する(解釈の幅を狭める)
- 段階的に考えさせ、最後に自己点検させる(裏取りの弱い箇所を自分で挙げさせる)
このうち上の2つは、先ほどの公式ガイドが名指しで推奨しているタクティクです。外部の知識に頼らせないほど、捏造の余地が減るという発想が共通しています。
出典: OpenAI「Prompt engineering」公式ガイド(英語)
コピペで使える土台プロンプトと、その前提
5原則をひとつのプロンプトにまとめると、次のようになります。
そのまま貼り付け、最後の質問だけ差し替えて使ってください。
あなたは正確性を最優先する事実確認アシスタントです。 【ルール】 1. 確実に裏が取れる事実だけを述べる 2. 不明・自信がない点は「確認できません」と正直に書き、推測で埋めない 3. 事実と、あなたの解釈・意見は分けて書く 4. 主張には可能な限り出典(資料名やURL)を併記する 5. 数値・日付・固有名詞は特に慎重に扱い、不確かなら断定しない 【進め方】 手順を分けて考え、回答後に「この回答で裏取りが弱い箇所」を1〜3点、自分で指摘してください。 【参照資料】(あれば下に貼る・無ければ空欄) (ここに社内資料やWebからコピーした原文を貼る) 【質問】 (ここに質問を書く)
ただし、これは万能ではありません。固有名詞・数値・最新情報を含む質問では、このプロンプト単体で事実を確定させないのが鉄則です。
そうした質問では、次に説明する「参照テキストの添付」か「検索機能のオン」を必ず組み合わせてください。
プロンプトより効く「機能」の併用
正確性の底上げで見落とされがちなのが、プロンプトの文面ではなく「機能」で解くべき問題があるという視点です。指示文をいくら磨いても解けない種類の誤りは、機能の切り替えで対処します。
指示で直すこと、機能で解くこと
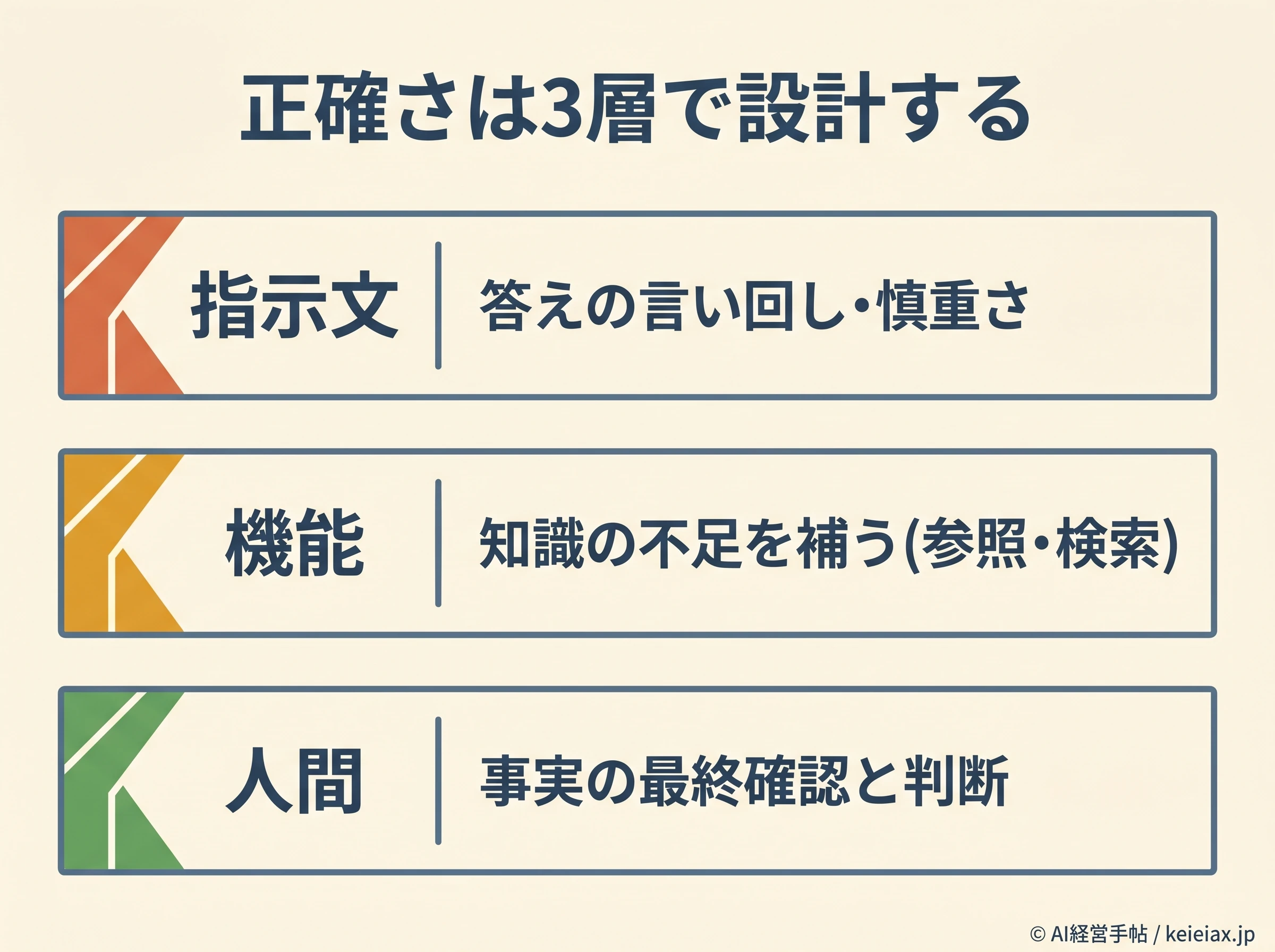
役割分担はシンプルで、答えの言い回しや慎重さは指示文で整え、知識の不足は機能で補うと切り分けるだけです。
ここでは代表的な3つの機能を、効く場面とあわせて見ていきます。
機能と「効くハルシネーション」の対応
| 機能 | 効く場面 | 前提・限界 |
|---|---|---|
| 参照テキストの添付 | 渡した資料の中で答えさせる | 「資料外は記載なしと書く」と明示が必要 |
| 検索(ブラウジング) | 最新情報・時事・製品仕様 | 引いた出典は人間が開いて確認 |
| カスタム指示 | 毎回の慎重ルールを固定 | 指示忘れは防げるが事実確認は別 |
参照テキストの添付は、社内資料やWebの原文をプロンプトに貼り、その中だけで答えさせる使い方で、OpenAI公式も第一の精度向上策として挙げています。
このとき「資料に書かれていないことは、資料に記載なしと答えて」と一言添えるのが肝心です。
検索(ブラウジング)機能が効くのは、学習データの古さが原因の誤りで、最新情報や製品仕様のように指示文では直せない領域を機能側で補います。
ChatGPTの検索は出典リンク付きで答え、無料プランを含むすべての利用者が使えます。
出典: OpenAI Help Center「ChatGPT Search」(英語)
カスタム指示に恒久ルールを登録する
毎回プロンプトを書くのが面倒で、つい省いてしまう。これが事故の温床になります。
そこで使いたいのがカスタム指示(Custom Instructions)です。
設定の「Customize ChatGPT」から、「裏が取れる事実だけを述べる」「不明は不明と言う」「出典を併記する」といった恒久ルールを一度だけ登録しておけます。これは以降のすべてのチャットに自動で適用され、無料を含む全プラン、パソコンとスマホの両方で使えます。
メリットカスタム指示が効く理由
毎回の「言い忘れ」によるブレを物理的に防げます。指示の有無に成果が左右される状態から抜け出せるのが、現場での最大の利点です。
用途・モデル別の使い分け
ここまでを踏まえ、「どこまでプロンプトに任せ、どこから検証に回すか」を、よくある場面ごとに整理します。迷ったら、この基準で仕分けてください。
固有名詞・数値・日付を含む事実を求めるとき。
プロンプトだけで確定させず、参照テキストの添付か検索のオン、または人間の出典確認を必ずセットにします。最良のモデルでも難問で約4割外す領域だからです。
要約や言い換えなど、渡した資料の中で完結する作業のとき。
ここはプロンプトの工夫で十分実用になります。参照テキストを渡し、範囲内で答えさせれば捏造はほぼ抑えられます。
誤りが法的・財務的に大きな実害になるとき。
AIは下書きや選択肢出しに役割を限定し、最終判断と公開前の確認は人間が出典の原本で行います。ハルシネーションは構造上ゼロにできず、責任は人に委ねられないためです。
より高い正確性が要る重要タスクのとき。
じっくり考える推論モード(Thinkingなど)を選ぶ手があります。OpenAIのシステムカードでは、推論モードのGPT-5が従来モデルに比べ、検索のオン・オフどちらでも事実の誤りが約5分の1に減ったと報告されています。
要点推論モードも万能ではない
推論モードは事実の誤りが減る傾向にありますが、タスクによってばらつきがあり、難しい事実質問では依然として無視できない割合で誤ります。「賢いモデルだから検証は不要」とは考えないでください。
業務で事故ゼロに近づけるレビュー工程
最後に、プロンプトと機能を組み込んだうえで、業務の流れとしてどう回すかを設計します。ここが整っていないと、どれだけ良い指示を書いても誤情報はすり抜けます。
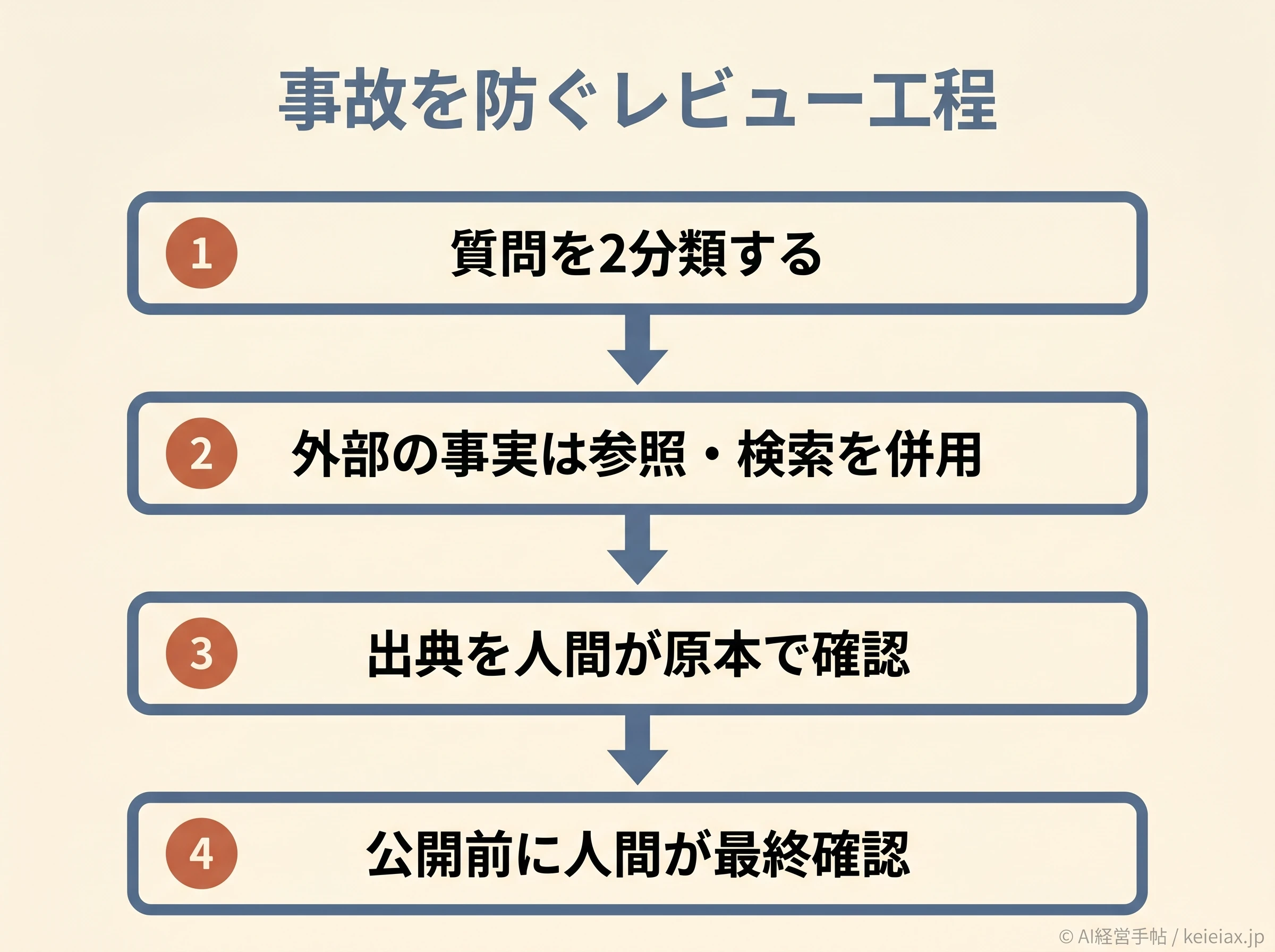
考え方の中心は、人間とAIの責任を分けることです。AIに任せるのは「下書き」と「選択肢出し」まで、事実の最終確認と意思決定は人間が担う、という線引きを最初に決めておきます。
AIの答えを点検する簡単な手として、同じ内容を聞き方や角度を変えて2〜3回たずねる方法があります。
毎回ぶれずに同じ答えが返れば確度は高く、聞くたびに数値や固有名詞が変わるなら、それは裏取りが必要なサインです。
公開・提出前のチェックリスト
具体的には、次の項目を業務フローに組み込みます。
全部を毎回やるのではなく、事実を扱う質問のときだけ必ず通す関門として運用すると現実的です。
- この質問は「資料内で完結」か「外部の事実」かを分類した
- 外部の事実なら、参照テキストの添付か検索のオンにした
- 「不明なら不明と言う」許可を与えた
- 出典を併記させ、その出典を人間が1つでも実物で確認した
- 数値・日付・固有名詞を、原本で1点でも突き合わせた
- 怪しい箇所は角度を変えて再質問し、答えが揺れないか確かめた
- 恒久ルールはカスタム指示に登録し、言い忘れを防いだ
- 公開・提出の前に、人間が最終確認する関門を置いた
警告参照テキストと機密情報
参照テキストの添付は強力ですが、顧客情報や未公開の財務資料を無防備に貼り付けると情報漏洩のリスクがあります。何を入力してよいか、社内ルールを先に決めてから運用してください。
よくある質問
Q「ハルシネーションしないで」と書けば嘘をつかなくなりますか?
A完全には防げません。第三者の検証では、その指示後にChatGPTが「知りません」と正直に答える効果は確認されていますが、これは不確実さを表明しやすくなるだけで、捏造そのものをゼロにはしません。事実を扱う質問では、参照資料の添付か検索機能、そして人間の確認を併用してください。
Qなぜ「嘘つかないで」だけでは効かないのですか?
Aハルシネーションは意図的な嘘ではなく、確率的に次の言葉を選ぶ過程で生じる構造的な誤りだからです。OpenAIの研究は、学習データが完璧でも、また「わからない」と答えると損をする評価設計のために、自信過剰な誤答が残ると説明しています。
Q正確に答えさせる一番効果的な方法は何ですか?
AOpenAI公式が第一に挙げるのは「参照テキストを与え、その中だけで、出典を明示して答えさせる」方法です。外部の知識に頼らせないほど、捏造の余地が減ります。
Q最新の賢いモデルを使えば間違えませんか?
Aいいえ。OpenAIのシステムカードでは、最新の推論モデルでも難しい事実質問で約4割のハルシネーションが報告されています。モデルの進化は誤りを減らしますが、ゼロにはしません。
Q毎回プロンプトを書くのが面倒です。固定する方法はありますか?
Aカスタム指示(設定のCustomize ChatGPT)に「裏が取れる事実だけ」「不明は不明と言う」「出典を併記」などの恒久ルールを登録すれば、以降の全チャットに自動で適用され、言い忘れを防げます。無料を含む全プラン、パソコンとスマホで使えます。
Q業務でChatGPTの誤りによる事故を防ぐにはどうすればいいですか?
A「資料内で完結する作業か、外部の事実が必要か」で質問を仕分け、後者には参照テキストか検索を併用し、数値・固有名詞・出典は人間が原本で確認する関門を置きます。AIは下書きと選択肢出しに限定し、最終判断は人間が担うのが原則です。
まとめ:呪文ではなく「設計」で精度を上げる
「ハルシネーションしないで」は、AIが不確実さを言いやすくなる補助としては働きますが、それ一つで誤情報を止める呪文ではありません。
効くのは、質問の性質を見極めて「指示・機能・人間の確認」を組み合わせて設計するやり方です。資料内で完結する作業は指示で、外部の事実は機能で、最終判断は人間で。
この3層を業務フローに落とせば、ハルシネーションによる事故は現実的なところまで減らせます。
次の一歩として、まずは自分のよく使う質問を「資料内」か「外部の事実」かで分類し、カスタム指示に恒久ルールを登録するところから始めてみてください。
その小さな設計が、AIを安心して業務に組み込むための土台になります。