チャットGPTハルシネーションの実例集|AIが嘘をついた事件と業務で防ぐ具体策
法律もAIも丸暗記より、危ない場面を先に知っておく方が安心ですよね。
実は架空の判例を裁判所に出して制裁になった例が世界で1,300件超あると聞いたら、自社のどこに二重チェックを置くべきか気になりませんか?

チャットGPT(ChatGPT)がもっともらしい嘘を生成し、それを業務で使ってしまったことが原因で、世界中で訴訟や賠償、企業の謝罪が相次いでいます。米国では弁護士が架空判例を裁判所に提出して制裁を受け、カナダでは航空会社がチャットボットの誤案内で賠償命令を受け、日本でも制作会社が存在しない日本語をサイトに載せて謝罪に至りました。
この記事では、AIが嘘をついた実際の事件8件を整理したうえで、なぜ起こるのか、どの業務で避けるべきか、どう検証すべきかを、現場で今すぐ使える形にまとめます。読み終えたとき、自社業務のどこに人間の二重チェックを必ず挟むべきかがはっきり決められる状態を目指します。
ハルシネーションとは何か(「嘘」ではなく確率予測の副産物)
ハルシネーションとは、生成AIが事実に基づかない情報を、もっともらしく自信を持って出力する現象です。総務省の令和6年版情報通信白書は、生成AIのリスクとしてこれを明記し、技術的対策が講じられても完全には抑制できないと指摘しています。
「AIが嘘をつく」という比喩は通じやすい一方で、厳密には悪意のある虚偽ではなく、確率的な言語予測の副産物です。AIは真偽を判定する装置ではなく、次に来る確率の高い語をつなげて文章を作る装置だと理解するところから出発したほうが、対策の方向を間違えにくくなります。
出典: 総務省「令和6年版 情報通信白書」生成AIが抱える課題
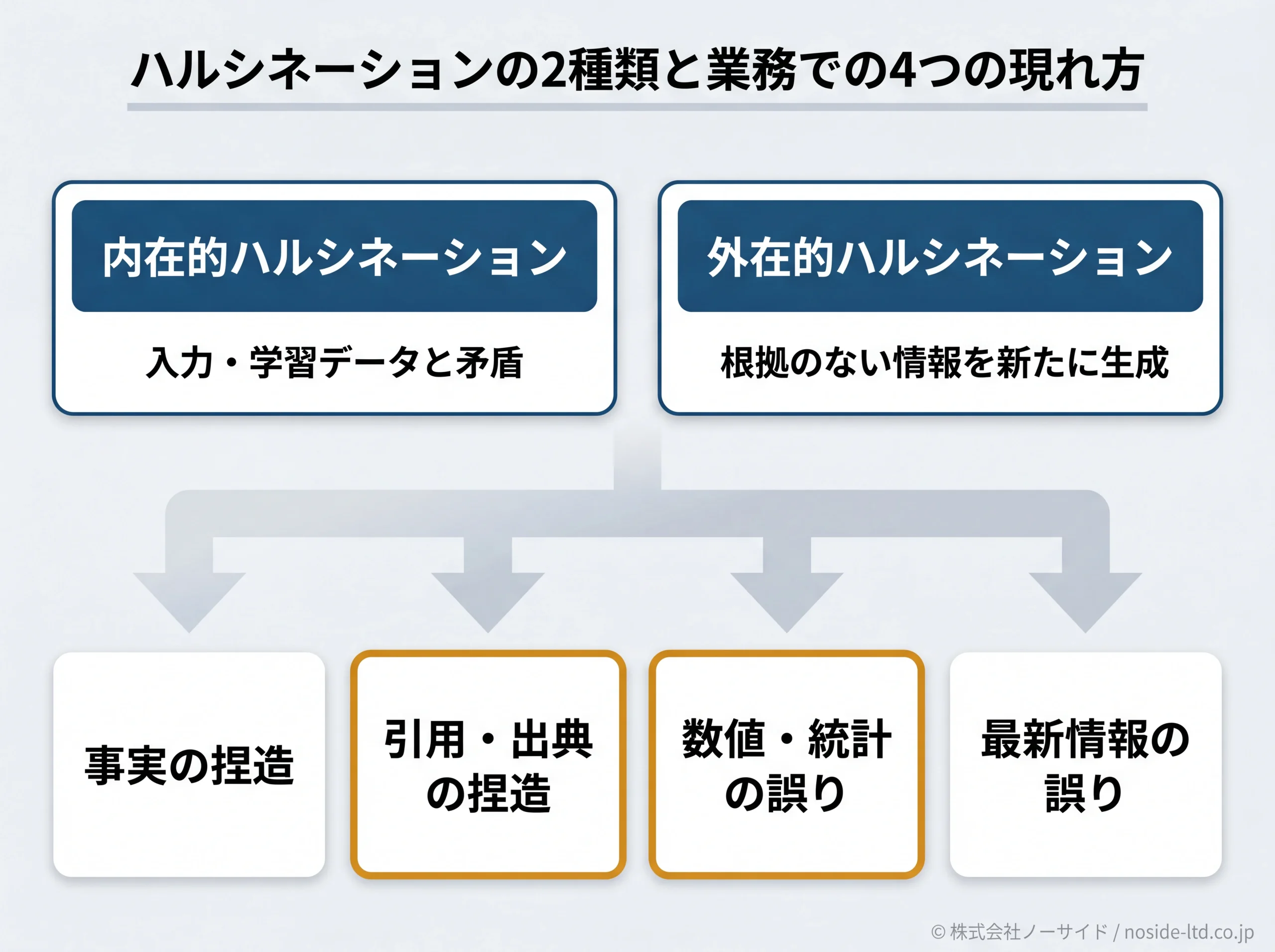
学術的な2種類と、業務で見える4つの現れ方
AI研究の世界では、ハルシネーションは大きく2種類に分けられます。内在的ハルシネーション(Intrinsic)と呼ばれるのは、与えた入力や学習データと矛盾する出力のことで、たとえば要約してもらった文書に、元の文書には書かれていない結論が混入する例がこれにあたります。
もう一方の外在的ハルシネーション(Extrinsic)は、学習データや入力に根拠がない情報を新たに生成してしまうことです。架空の判例や実在しない論文を作り出してしまうのは、この外在的ハルシネーションに分類されます。
ただし業務の現場では、この学術分類だけでは話が抽象的すぎます。私たちは実務で問題になりやすい4つの現れ方として整理しておくことをすすめています。
- 事実の捏造(実在しない出来事・人物・関係を作る)
- 引用・出典の捏造(架空の判例・論文・記事URLを生成)
- 数値・統計の誤り(それらしい桁・単位で値が出る)
- 最新情報の誤り(学習時点以降を知らない、または古い前提で断定)
記事の後半で出てくる事件のほとんどは、引用の捏造か、人物情報の捏造です。自社業務でこの4つのどれが起こりうるかを先に押さえておくと、後の判断軸が立てやすくなります。
なぜ自信満々に間違えるのか
ハルシネーションが起こる根本原因は、言語モデルの仕組みそのものにあります。AIは「次に来る確率が高い語」を予測して文章化する装置で、真偽の判定器ではないからです。
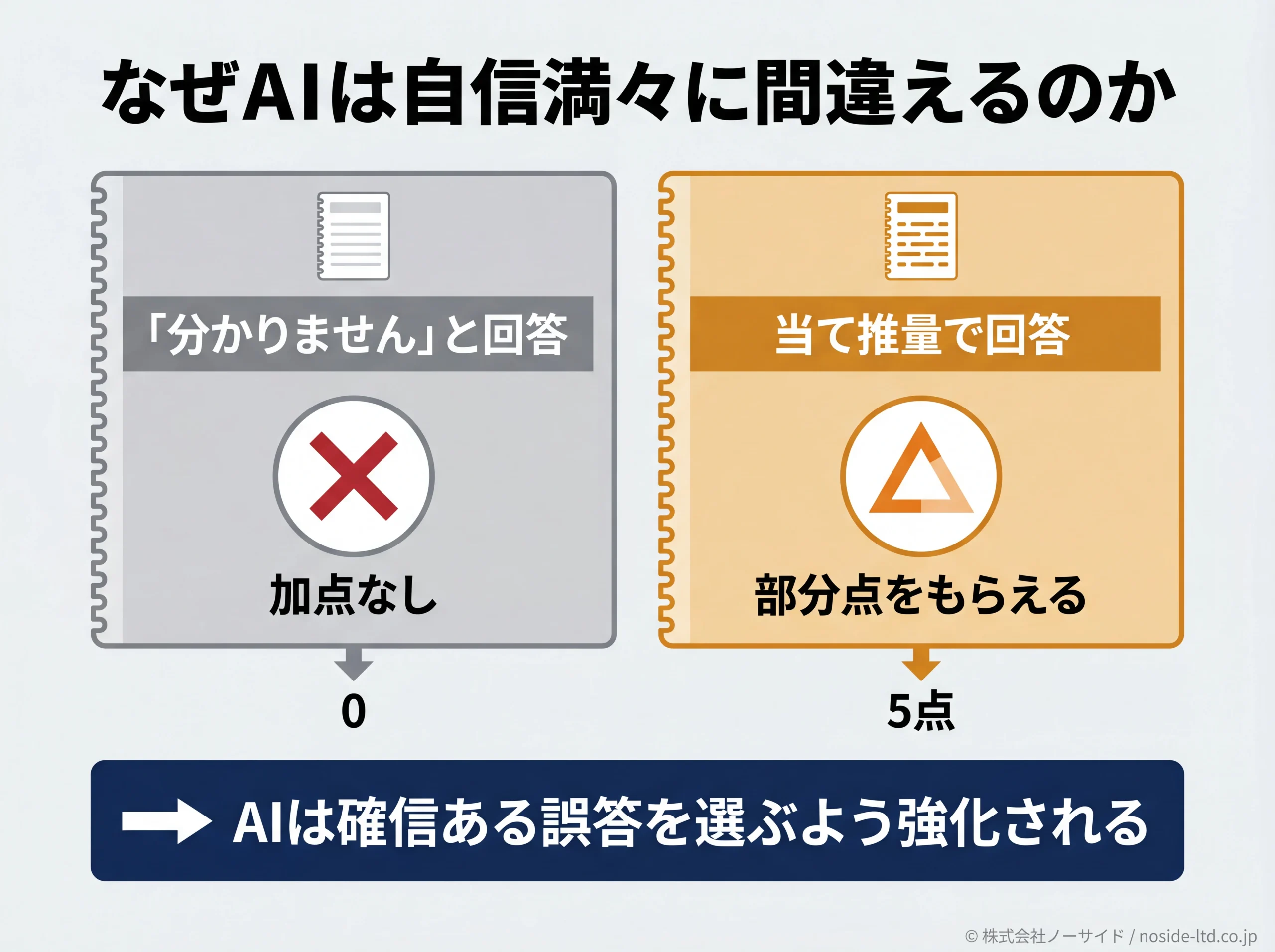
2025年9月にOpenAIの研究者らが公開した論文「Why Language Models Hallucinate」は、もう一歩踏み込んでいます。学習と評価の段階で「分かりません」より「当て推量」の方が高く採点されるために、AIは自信を持って推測する方向に強化されていく、という構造的な指摘です。
言われてみれば学校のテストと同じで、空欄で出すより当てずっぽうで書いた方が部分点をもらえるのと似ています。AIも、確信のある誤答を選びやすい仕組みのなかで育っているわけです。
これを補強しているのが、学習データの偏り・不足・古さ、曖昧な前提や誤前提を含むプロンプト、ニッチで固有な情報のデータ希薄さです。「最新モデルにすればハルシネーションは解決する」「日本語対応が進んだから正確になった」は誤解で、頻度は下がってもゼロにはなりません。
出典: Kalai et al.「Why Language Models Hallucinate」(arxiv 2509.04664・英語)
【実例集】AIが嘘をついた事件8件
ここからが本記事の中心です。世界と日本で実際に起きた8件の事件を、何が起きたか・何が問題だったか・自社業務への示唆の順で整理しました。共通するのは、AIの出力をそのまま事実として扱った瞬間に事故が起きているという構造です。
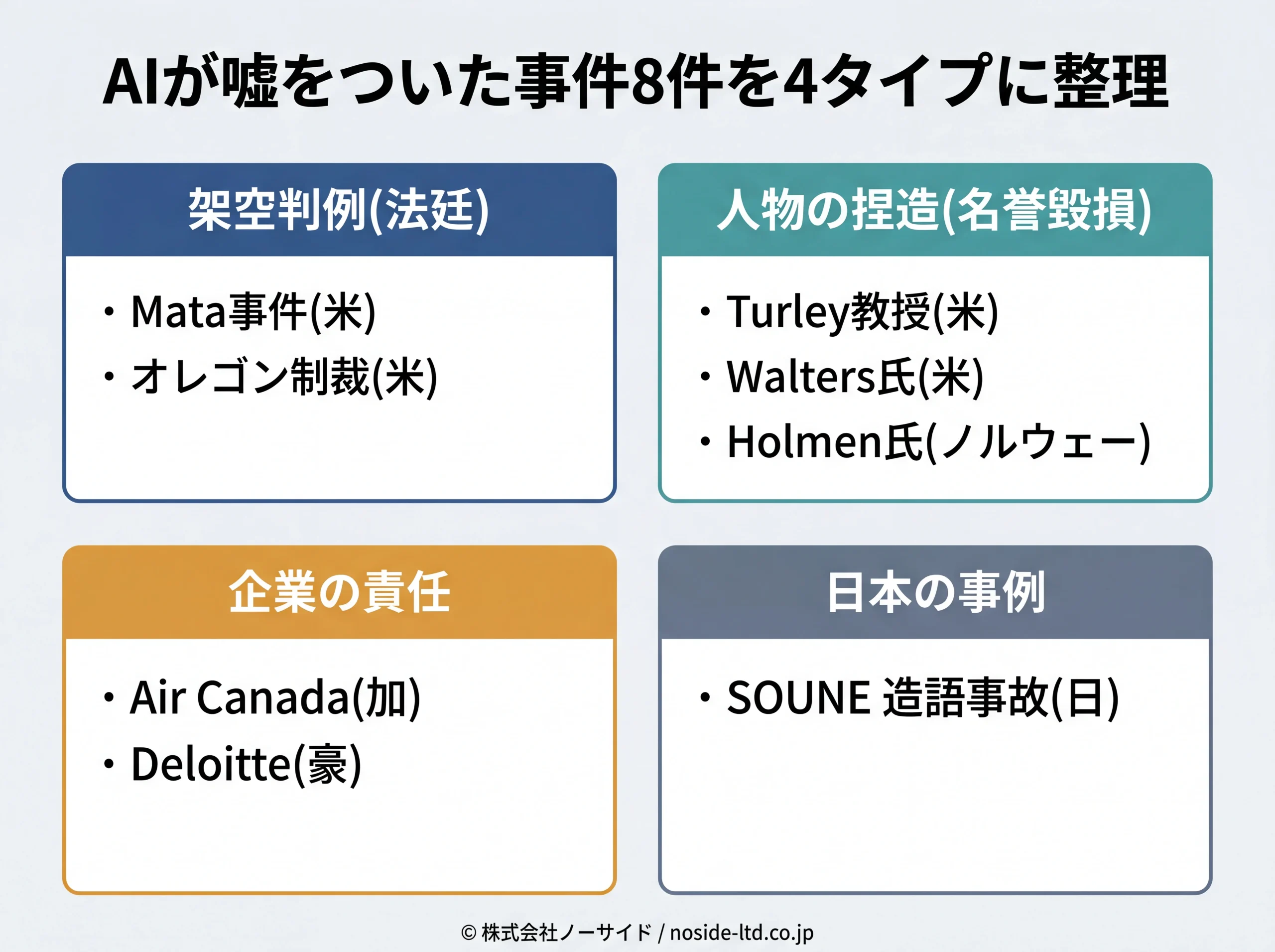
法廷を揺るがした架空判例(Mata事件・米オレゴンの制裁・世界1,300件超)
最も有名なのが、米国のMata v. Avianca事件(2023年6月)です。ニューヨークの弁護士スティーブン・シュワルツ氏らが、チャットGPTに調べさせた実在しない判例6件を裁判所に提出し、合計約5,000ドルの制裁金が科されました。
何が問題だったかというと、チャットGPTが架空の判例を、実在する判例とまったく区別がつかない形式で出力したこと、そして提出前にひとつも一次ソースを当たらなかったことです。弁護士本人は、チャットGPTに「この判例は本物か」と聞き、「本物だ」と返事をもらって安心したと述べています。AI自身に確認させても意味がないという、いま振り返れば当然の教訓が、最初に大きな代償とともに突きつけられた事件でした。
これは個別の事件で終わらず、構造的なトレンドへと変わってきました。法学者のダミアン・シャルロタン氏が運営する「AIハルシネーション判例データベース」によれば、2026年時点で1,300件を超える捏造引用事案が確認されており、件数は更新のたびに増え続けている状況です。米オレゴンでは、捏造引用23件と架空引用8件を提出した弁護士に対し、約11万ドルの制裁が科された事案も報じられました。日本でも士業の現場で同じことが起きないようにする、最低限の社内ルールが必要な段階に来ています。
ユタ州では、AIで生成した架空判例を含む書面を提出した弁護士が制裁を受けたBednar事件も発生しています。米国の法律実務では、AI利用そのものは禁じられていないものの、出典の実在確認をしないまま提出すると弁護士本人の責任になるという線が明確に引かれつつあります。
人物を貶めた捏造(Turley・Walters・ノルウェーHolmen)
人物情報の捏造は、業務というより名誉毀損のリスクに直結します。2023年4月、ジョージワシントン大学のジョナサン・ターリー教授は、チャットGPTが自分について架空のセクハラ疑惑と、実在しないワシントン・ポストの記事を「裏付け」として生成したと自身のブログで公表しました。AIは「もっともらしい裏付けの記事URL」まで作り出すのが恐ろしいところです。
米国ジョージア州のラジオ司会者マーク・ウォルターズ氏のケース(Walters v. OpenAI)では、チャットGPTが彼について「非営利団体から横領した」という虚偽を生成しました。ウォルターズ氏はOpenAIを名誉毀損で訴えましたが、2025年5月19日、裁判所はOpenAI勝訴の略式判決を出しています。AI開発者を被告とした初の名誉毀損訴訟として注目された事件ですが、勝訴したからAIの出力をそのまま使ってよい、という話にはなりません。
ヨーロッパで起きたのが、ノルウェー人男性Arve Hjalmar Holmen氏の事案(2025年3月)です。彼がチャットGPTに自分の名前を入力すると、AIは「子ども2人を殺害し、懲役21年を受けた殺人犯」と回答しました。ところが出身地と子の人数は実在情報と一致しており、罪状だけが完全な捏造でした。
プライバシー保護団体のnoybは、これをGDPR第5条(個人データの正確性)違反としてノルウェーのデータ保護当局に申し立てました。実在情報と捏造が混ざるのがこの種の事故の一番の落とし穴で、一部が正しいと「全部正しいかもしれない」と読者は誤解しがちです。人物情報の出力は事実として扱わない、公開しないを社内ルールに入れておくことが安全策になります。
企業が責任を負った事故(Air Canada・Deloitte豪)
企業の顧客対応AIが誤った案内をして賠償命令が出たのが、Moffatt v. Air Canada事件(2024年)です。カナダのエア・カナダのチャットボットが、死別運賃(家族の葬儀のための割引運賃)について事後申請が可能だと誤案内し、それを信じて航空券を購入した男性が後日返金を断られました。
ブリティッシュコロンビア州民事決済法廷は、約812.02カナダドルの損害賠償をエア・カナダに命じました。航空会社は「チャットボットは別人格」と抗弁しましたが、この主張は退けられ、自社サイトに乗せたボットの発言は会社の発言と扱われることが明確になりました。
もう1件、対外納品物での事故が2025年のDeloitte豪です。同社が豪州の雇用・職場関係省(DEWR)向けに提出した約29万豪ドルの報告書に、架空の参考文献と連邦裁判官の捏造引用が含まれていることが発覚しました。AzureのOpenAI機能を使ったことを後日開示し、一部返金に至っています。
この2件から見えるのは、対外公表物・顧客対応・納品物はAIの出力をそのまま使うと、企業そのものが責任を負う立場になるという事実です。必ず人間の最終承認と、出典の全件チェックを挟む運用を社内で決めておく必要があります。
日本でも起きている(SOUNE「視覴」造語の拡散)
海外事例だけでなく、2023年6月、日本国内でも事故が起きています。相模原市の制作会社SOUNEが、チャットGPTを使って制作したサイト上に「視覴(しちょう)」という、辞書にも存在しない日本語を載せて公開してしまいました。
担当者の目視確認はあったものの、「視聴」を「視覴」と書く誤字はあまりに自然に紛れ込み、すり抜けて公開されました。指摘を受けたあと、同社は公式ページで詳細な経緯を説明して謝罪しています。X(旧Twitter)では1,700万回を超える閲覧が確認され、日本語の見慣れた業務でもAI出力の検証は別レベルで必要だという教訓を残しました。
注意したいのは、「日本語ネイティブが見ればすぐ気づける」と思っていると、かえって誤字や造語を見逃す点でしょう。AI生成のテキストはリズムも文体も自然で、人の脳が「これは正しい日本語だ」と先に判定してしまうからです。校正は流し読みではなく、キーワード単位や辞書照合で行う必要があります。
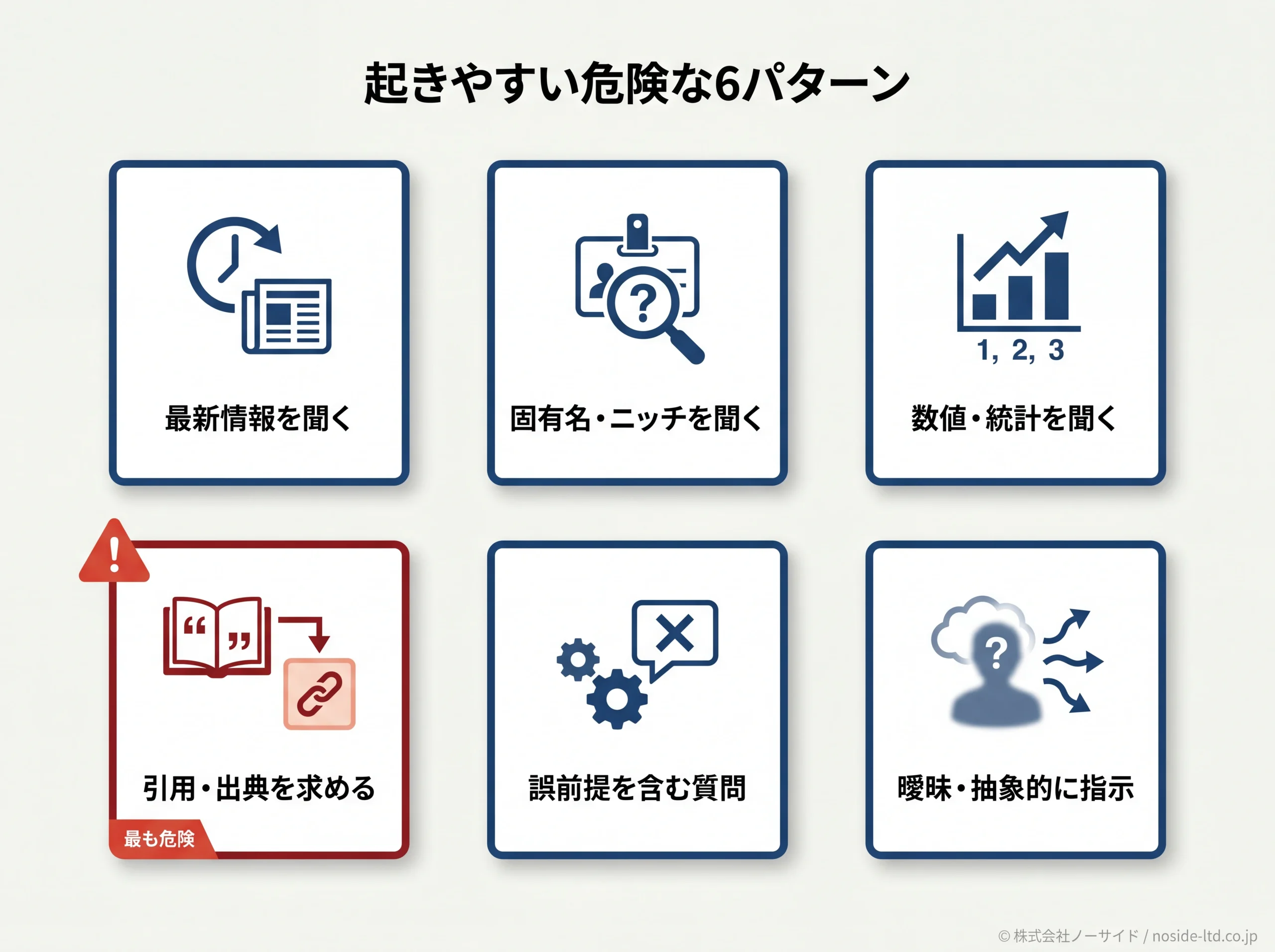
どんな質問・場面で起きやすいか(危険な6パターン)
事件8件を眺めると、ハルシネーションが起きやすい場面には明確な型があります。
私たちは現場で6つの危険パターンとして整理しており、AIに質問する前に、自分の問いがこの6つのどれかに該当しないか1秒でも考える習慣をつけると、事故の確率は目に見えて下がります。
- 1. 最新情報を聞く(学習時点以降の話・最近の制度改正・直近のニュース)
例:「今年の補助金で対象になるのは?」 - 2. 固有名・ニッチな情報を聞く(中小企業名・地域限定の制度・専門家の経歴)
例:「○○商会の創業年は?」 - 3. 数値・統計を聞く(市場規模・人口・歴史的数値)
例:「日本のEC市場の2024年の規模は?」 - 4. 引用・出典を求める(判例名・論文タイトル・記事URL)
例:「この主張の論文を教えて」 - 5. 誤前提を含む質問をする(架空の判例の要約・存在しない論文の解説)
例:「○○判決の要旨を教えて」(その判決自体が存在しないケース) - 6. 曖昧・抽象的に指示する(具体的な制約や対象を示さない)
例:「よさそうな会計ソフトをまとめて」
このうち4の引用・出典の捏造は、AIが最も得意としてしまう領域です。判例名・論文タイトル・著者名・出版社・年号まで、いかにも本物らしい組み合わせを作り出します。引用は「実在確認をしてから使う」を社内で必ず徹底してください。
5の誤前提については、たとえば「22世紀に活躍した経営者を3人挙げて」と聞けば、AIは存在しない人物を「いた」かのように説明します。前提が間違っていれば、AIは前提を疑わずに作話する、と覚えておくと自衛になります。
致命的な業務では「どこまで使い、どこから避ける」か
ここまでで「起きること」と「起きやすい場面」を見てきました。次に決めるのは、自社のどの業務でチャットGPTを使ってよく、どこから人間に切り戻すかです。判断軸は、誤りが取り返しのつくものか、対外的に出るか、検証可能か、業種規制があるかの4つです。
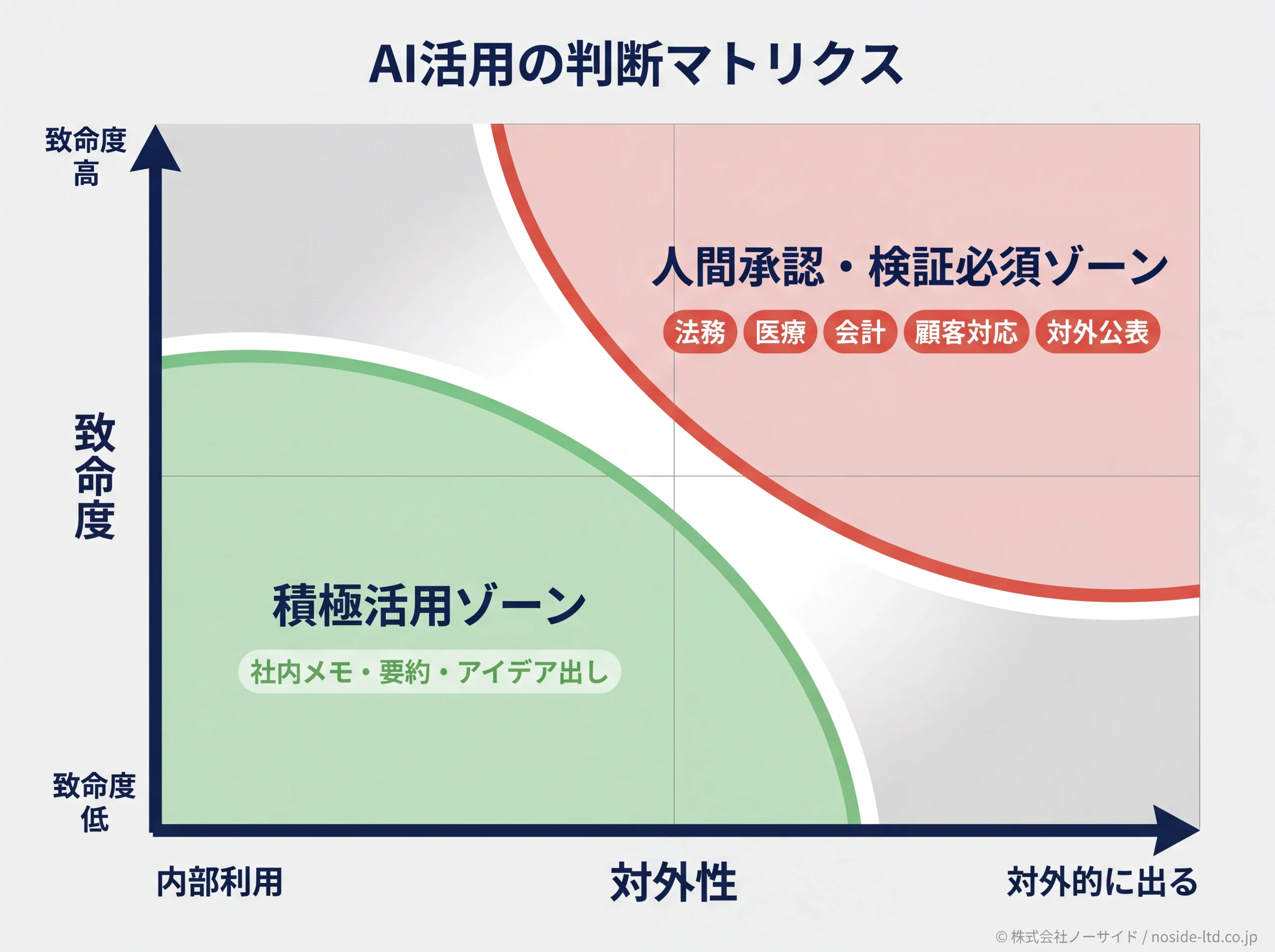
業務別の判断表
下の表は、私たちが現場で推奨している業務別の判断です。記事冒頭で示した4つの判断軸に基づき、それぞれの業務でどこまで踏み込んでよいかを整理しました。
| 業務 | 使ってよい範囲 | 避けるべきこと | 主な理由 |
|---|---|---|---|
| 法律相談・判例引用 | 下書き補助のみ | 判例・条文をそのまま採用 | 架空判例の事故が世界で多発 |
| 医療・健康判断 | 情報整理の参考まで | 最終判断・患者説明文の確定 | OpenAI自身が人間監督必須と明記 |
| 会計・税務・決算 | 説明文の叩き台のみ | 数値をAIに作らせる | 数値はハルシネーションの典型 |
| 顧客対応AI | FAQの自動応答(範囲限定) | 料金・契約条件の確定回答 | Air Canada事故=企業が責任 |
| 対外公表文 | 下書き・要約 | 人間レビューなしの公開 | Deloitte事故=出典捏造の流出 |
| 人物情報 | 調査の手がかり程度 | 事実扱い・公開 | Turley・Holmen=名誉毀損リスク |
| 社内メモ・要約 | 積極活用 | (なし) | 誤りが致命的でなく検証も容易 |
| 自社文書の参照回答 | RAGで限定運用 | 外部知識との混在 | RAGで当て推量を減らせる |
この表で「避けるべきこと」に書かれた行動を今やっている業務があれば、そこが優先的に検証手順と人間承認を組み込む対象です。今週中に1リストアップしてみてください。
業種別の許容度(法務・医療・会計の温度差)
同じ「AI活用」でも、業種によって許容できる誤り率の温度感は大きく違うのが現実です。法務・医療・会計は誤りが金額や法的責任、命に直結するため、ハルシネーションの許容度はほぼゼロでしょう。一方、社内メモ・アイデア出し・翻訳の下書きは誤りが致命的ではなく、再生成や修正で取り戻せるため、積極活用してよい領域になります。
業種規制の観点では、医療は薬機法・医療広告ガイドライン、金融は金商法・各種ガイドライン、法務は弁護士法・弁護士職務基本規程の制約があります。AIの誤りで規制違反が発生すれば、責任はAIではなく業務を行った人または会社に帰属する、という前提で線引きをしてください。
誤情報を出していないか確認する現実的な検証手順
業務でAIを使う以上、完璧に防ぐ手段はありません。代わりに、出力を「そのまま使わずに通す」検証フローを社内に組み込みます。ここでは出力前のプロンプトの型と、出力後のチェック手順を切り分けて示します。
嘘を出させにくくするプロンプトの4つの型
OpenAIの研究が示した「当て推量を報酬づけてしまう構造」を踏まえると、プロンプトの工夫だけでも、確信のある誤答を減らせます。型としては次の4つが有効です。
- 1. 根拠の明示を要求:「回答の根拠(出典・該当箇所)を併記して。確証がない箇所は『不確実』と明記して」
- 2. 不知の許可:「わからない場合は推測せず『わかりません』と答えて」(当て推量を抑える)
- 3. 回答範囲の制限:「以下に貼る資料の範囲内だけで答えて。範囲外は『資料に記載なし』と答えて」
- 4. 前提の検算:「○○の判例を要約して」の前に「その判例は実在するか確認して」を一段挟む
とくに2の「不知の許可」は強力でしょう。指示がないと、AIは「分かりません」と答えるよりも、何かしらの回答を返そうとするからです。この一文を入れるだけで、断定的な作話が体感できるほど減ります。
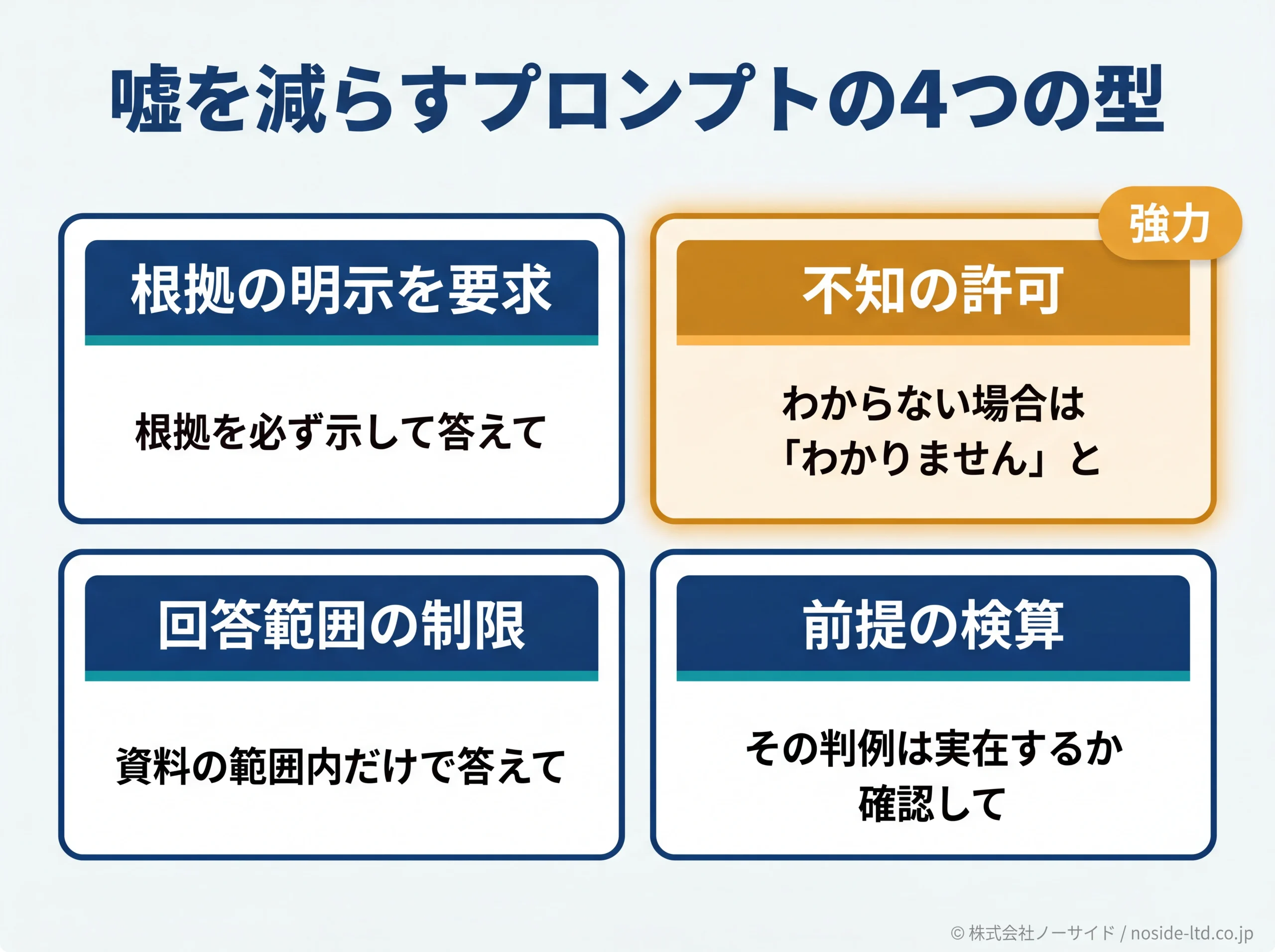
公開前の検証フロー5ステップ
出力後の検証は5ステップで組み立てます。すべてを毎回やる必要はなく、業務の致命度に応じて軽重をつけます。
- Step 1:一次ソース照合:数値・固有名・日付・引用は公式・一次データ(政府公式・公式ドキュメント・原典)で裏取り。所要は1主張あたり数分。
- Step 2:引用・出典の実在確認:URL・判例名・論文名が実在しクリックで開けるか全件確認。架空URL・架空判例の検出はここで止めます。
- Step 3:クロスチェック:同じ質問を別の生成AI(たとえばClaudeやGemini)に投げ、食い違う点を再確認に回します。
- Step 4:自己再確認の活用:チャットGPT自身に「この回答に事実誤認や不確実な箇所はあるか」と再点検させます。ただしAIの自己申告も誤るため、Step 1〜3の代替にはしません。
- Step 5:人間の最終承認:対外公表物は「発信責任は人間」の原則で、担当外の二重確認を必須化します。
Mata事件の弁護士はStep 4の自己再確認だけで満足し、Step 1とStep 2を省きました。自己再確認は最後の手段であって、最初の手段にしてはいけないのが現場の教訓です。
公開前チェックリスト8項目
下記の8項目は、対外公表物を出す前に印刷して机に貼るレベルの最終チェックです。社内の承認フローに組み込んでください。
- ① 数値・統計に一次ソースがあるか
- ② 引用元のURL・判例・論文は実在し、開けるか
- ③ 学習時点以降の最新情報を別途確認したか
- ④ 人物・固有名の事実は裏取りしたか
- ⑤ 誤前提を鵜呑みにしていないか
- ⑥ 別AIとのクロスチェック差分を解消したか
- ⑦ 致命度の高い業務は専門家確認を通したか
- ⑧ 誰が最終承認したか記録したか
とくに⑧の「誰が承認したか」の記録は、後で問題が起きたときに再発防止と責任所在の整理に直結します。承認者と日付を1行残すだけで、組織のAI運用は格段に安定します。
社内で安全に運用するために最低限決めること
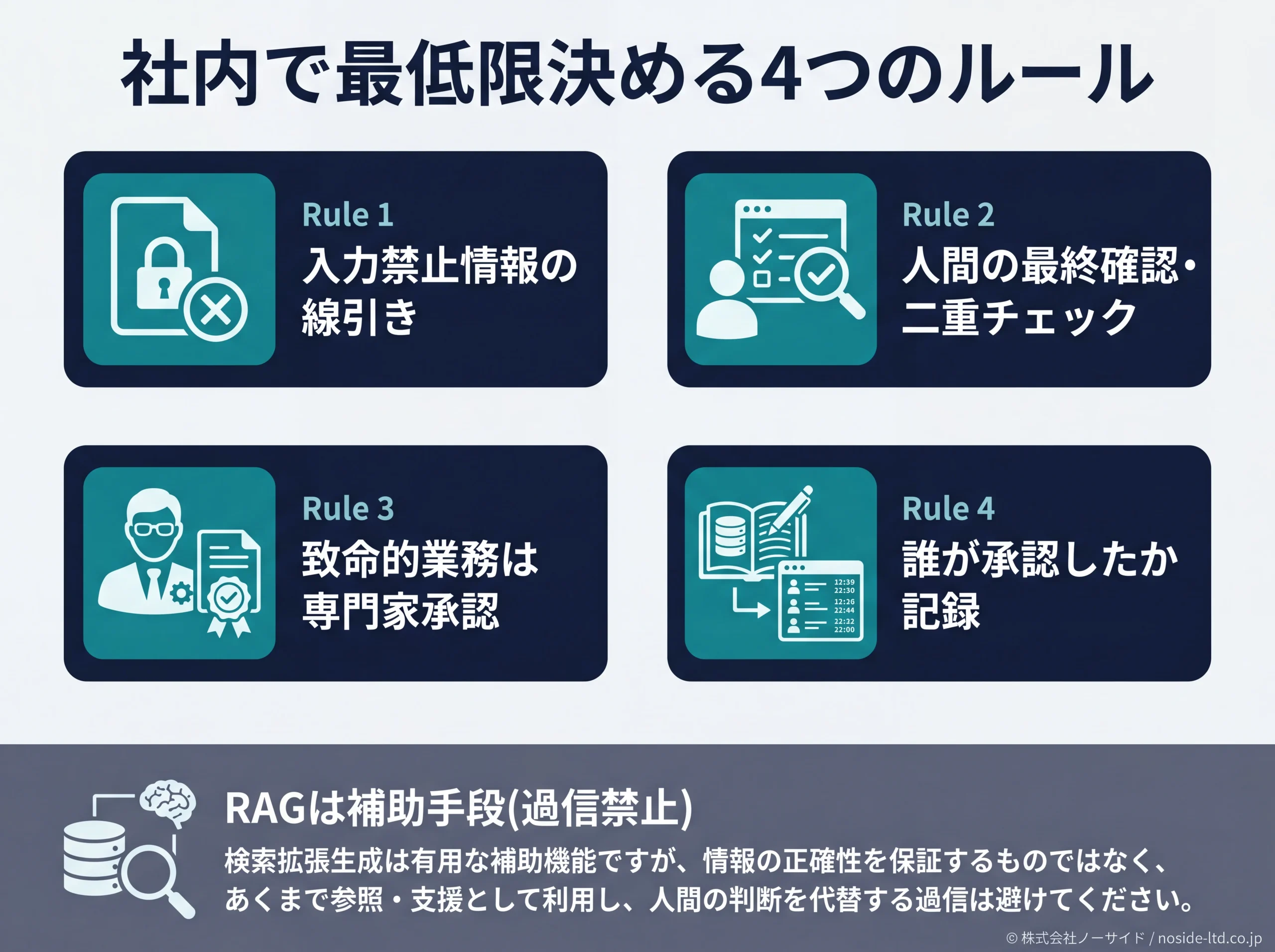
個人の工夫だけでは限界があり、ハルシネーションは「組織で防ぐ」フェーズに入っています。私たちが企業に推奨している最低4ルールと、RAGの位置づけを以下にまとめました。
最低限決めるべき4つのルール
- ① 入力禁止情報の線引き:顧客個人情報・契約条件・未公表のM&A情報など、AIに入力してはいけない情報を一覧化。法人向けの設定で学習に使われないオプションを必ず有効化。
- ② 人間の最終確認・二重チェック:対外公表物・顧客向け文書・数値資料は担当者と承認者の二重チェック必須。
- ③ 致命的業務は専門家承認:法務・医療・会計・労務など、誤りが法的責任や安全に直結する業務は、必ず該当領域の専門家のレビューを通す。
- ④ 誰が承認したかの記録:承認者・承認日・参照したAI出力のスナップショットを記録。事故時に経緯を追える状態にしておく。
この4点をA4一枚のAI利用ガイドラインに落とし込み、入社時研修と年次更新に乗せるところまでをセットにします。総務省と経済産業省が2025年3月に公開したAI事業者ガイドライン(第1.1版)は、企業向けの体系的な指針として参照できるので、まずはここに目を通すと社内ルールの土台が早く整います。
出典: 総務省・経済産業省「AI事業者ガイドライン(第1.1版)」(令和7年3月28日・PDF)
RAGの役割と限界(過信禁止)
RAG(Retrieval-Augmented Generation)は、AIが回答する際に自社の文書データベースを参照しながら答える仕組みです。社内FAQ・規程・製品マニュアルなどの「正しい元データ」に回答を縛ることで、外部知識からの当て推量を減らせます。
実装は大きく6ステップで進めます。①対象業務と参照文書の棚卸し → ②データ整備と権限設計(機密区分) → ③検索基盤(ベクトル化)の用意 → ④回答に出典(参照箇所)を必ず表示させる設定 → ⑤テスト運用(既知のQ&Aで誤答率を測定) → ⑥本番と継続監視、の流れです。
ただしRAGは万能薬ではありません。検索のヒット精度が低い、または元データそのものが誤っていればハルシネーションは残ります。「RAGを入れたから安全」と言い切るのではなく、「外部知識からの当て推量を減らす手段」と過信しない姿勢が必要です。
それでもゼロにはできない(リスクを許容範囲に抑える着手順)
GPT-5(2025年8月)では、Web検索を有効にしたときの主要な事実誤りを含む回答が、GPT-4o比で約44%減少しました。それでもOpenAI自身が公開したSystem Cardは、高リスク領域(医療等)では人間の監督が不可欠と明記しています。
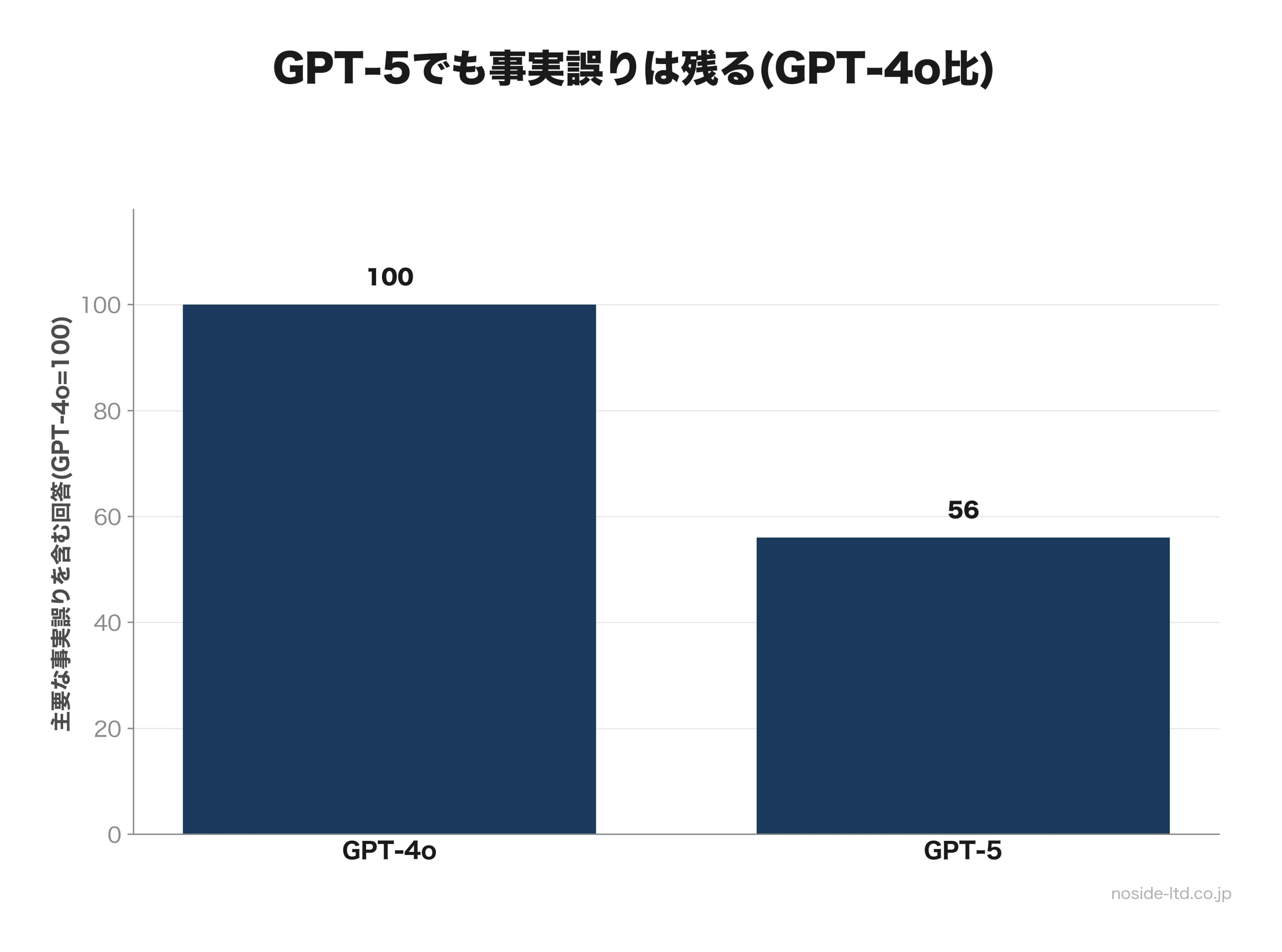
つまり、「最新モデルにすれば解決」ではないのです。私たちの結論は、「一定確率で必ず起こる前提で、業務を仕分けし、高リスク側だけに人間承認と検証手順を集中投下する」です。
具体的に今週から始めるなら、次の3ステップです。①自社のAI利用業務を1枚のリストにする → ②各業務を「致命度の高い側」「低い側」に二分する → ③高リスク側にだけ、本記事のチェックリスト8項目と承認ルールを必ず挟む規程を整える。低リスク側はむしろ積極的にAI活用を進めて生産性を上げるのが、現実的なバランスです。
AI料金プラン全体の選び方や、無料版と有料版の機能差については、別記事「チャットGPT無料と有料の違い」で整理しています。業務利用での課金プラン選定の参考にしてください。
出典: OpenAI「GPT-5 System Card」(2025年8月13日・PDF・英語)
よくある質問(FAQ)
QチャットGPTのハルシネーションとは何ですか?
A生成AIが事実に基づかない情報を、もっともらしく自信を持って出力する現象です。悪意の嘘ではなく、次に来る確率の高い語を予測する仕組みの副産物で、技術が進んでも完全にはなくせません(総務省・情報通信白書)。
QチャットGPTが嘘をついて実際に起きた事件はありますか?
Aはい、世界で多数発生しています。米国ではMata v. Avianca事件で弁護士が架空判例6件を提出し約5,000ドルの制裁、カナダではAir Canadaのチャットボット誤案内で約812.02カナダドルの賠償命令、日本でも制作会社SOUNEが存在しない語「視覴」を載せて謝罪しています。
QなぜAIは自信満々に間違えるのですか?
A学習と評価が「分かりません」より「当て推量」を高く評価してしまうためです。二値採点では推測した方が得点しやすく、確信のある誤答が誘発されます(OpenAI研究・2025年9月)。
Q法律相談や判例の引用にチャットGPTを使ってよいですか?
Aそのまま使うのは避けるべきです。引用・判例はAIが最も捏造しやすく、世界で1,300件以上の捏造引用が法廷で確認されています。下書き補助に限定し、必ず一次ソースで全件確認し、専門家のレビューを通してください。
Q業務で誤情報を見抜く現実的な方法は?
A①数値・固有名・日付・引用を一次ソースで照合 ②引用URLや判例が実在し開けるか確認 ③別の生成AIでクロスチェック ④対外公表物は人間が最終承認、の4段構えが現実的です。
Q最新モデル(GPT-5など)にすればハルシネーションは解決しますか?
A頻度は下がりますが解決しません。GPT-5はWeb検索有効時に主要な事実誤りを含む回答がGPT-4o比で約44%減りましたが、OpenAI自身が「高リスク領域では人間の監督が不可欠」と明記しています。
Q社内で安全に使うために最低限決めるべきことは何ですか?
A①利用ガイドライン(入力禁止情報・用途の線引き)②人間による最終確認・二重チェック ③致命的業務は専門家承認 ④誰が承認したかの記録、の4点です。RAGで自社文書に限定するのも有効です。
Qハルシネーションをゼロにできないなら、何から始めればよいですか?
A「一定確率で必ず起こる」前提で、まず致命度の高い業務(法務・医療・会計・対外公表)と低リスク業務(下書き・要約・アイデア出し)を仕分け、高リスク側に検証手順と人間承認を必ず挟むことから始めます。