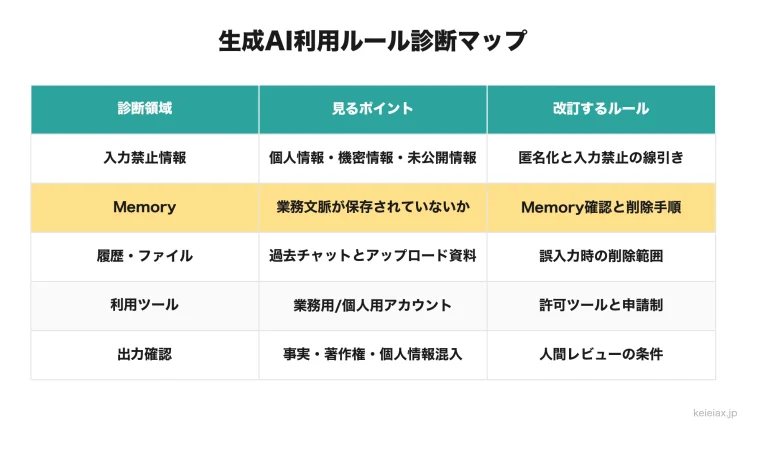
GQAとは
GQAとは、LLMの回答速度と品質のバランスを取りやすくするアテンション方式です。Grouped-Query Attentionの略で、複数の質問役の頭が、少数の共通メモを参照するように設計します。店頭の相談員がそれぞれ話を聞きつつ、在庫台帳は共有するようなイメージです。
英語表記:Grouped-Query Attention
GQAの仕組み
アテンションでは、クエリ、キー、バリューという情報を使って「次に何を見るか」を決めます。MHAは頭ごとにキーとバリューを持つため表現力は高い一方、保存する情報は増えがちです。GQAは、いくつかのクエリヘッド、つまり質問役のまとまりが同じキーとバリューを共有することで、計算と記憶の負担を抑えながら精度低下を避ける狙いがあります。
MHAとMQAの中間にある
MHAは丁寧だが重い方式、MQAはかなり軽い方式、GQAはその中間に置かれる方式です。論文では、GQAをMQAの一般化として説明し、品質をMHAに近づけつつ速度をMQAに近づける狙いが示されています。極端に削るのではなく、共有範囲を調整する発想。速度と品質の折り合いを探す設計です。
モデル選定での意味
GQAは、利用者が画面で直接触る機能名ではありません。けれども、チャットの応答速度、長文処理、同時アクセス時の安定性に関わる裏側の設計です。企業がLLMを選ぶときは、ベンチマーク点だけでなく、使う人数と待ち時間を含めて見る必要があります。調達時に見落としやすい、運用側の論点でしょう。
Topic一から学習し直さないためのレシピでもあった
GQA論文の面白い点は、方式の名前だけでなく、既存のmulti-headモデル、つまり複数の頭で見る既存モデルを少ない追加計算で変換する手順も提案したことです。研究としては「新モデルを丸ごと作り直す」より、手持ちの資産をどう軽くするかという実務寄りの発想も含んでいました。
GQAに関するよくある質問
- GQAはモデルの回答品質を下げませんか?
- 設計次第です。GQAはMHAより軽くしつつ、MQAより品質を保ちやすい中間設計として提案されました。実際の品質はモデル全体の学習や実装にも左右されます。
- GQAはユーザーが設定するものですか?
- 通常はユーザーが設定するものではなく、モデルの設計に組み込まれます。企業側は、採用するモデルの速度、費用、長文処理の性能を見るときの背景知識として使えます。
- GQAとMLAは同じですか?
- 同じではありません。GQAはキーとバリューをグループで共有する方式、MLAは保存情報を潜在表現に圧縮する方向の方式です。どちらも推論効率に関わりますが、軽くする場所が違います。