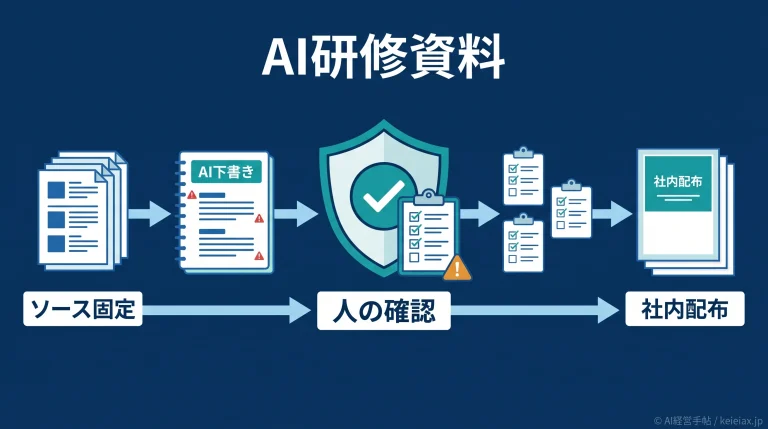
識別モデルとは
識別モデルとは、データを見て「どの種類か」を見分けることに特化したAIのモデルのことです。新しいデータを作り出す生成モデルと対になる考え方で、分類や予測の土台として広く使われています。
境界線を引いて見分ける仕組み
識別モデルは、データの「作られ方」までは踏み込みません。猫と犬を見分けたいなら、両者を分ける境界線をどこに引けばよいかを直接学ぶのが基本的な発想です。データ全体の成り立ちを覚えるより、答えを出すことに集中するぶん、分類の精度を出しやすいという利点があります。
代表例には、ロジスティック回帰、サポートベクターマシン(SVM)、線形判別分析などが挙げられます。スパムメールの判定や画像の分類など、「仕分ける」仕事の多くを担ってきました。
生成モデルとの違い
生成モデルが「猫の画像とはそもそもどういうものか」までさかのぼって学び、新しい画像まで作れるのに対し、識別モデルは「これは猫か犬か」を見分けることだけに集中します。作れるのが生成、見分けるのが識別、という対比で捉えると分かりやすいでしょう。
ビジネスでの使われ方
識別モデルは、判断を自動化したい場面で活躍します。問い合わせの自動振り分け、不正取引の検知、与信の判定など、「仕分ける・見分ける」業務と相性が良い技術です。生成AIが注目を集める今も、現場の地道な判断を支えているのは、こうした識別の仕組みだったりします。
Topic「分類なら識別が強い」という古い論争
生成と識別、分類で強いのはどちらか。これは研究の世界で長く議論されてきたテーマです。Andrew NgとMichael Jordanという2人の著名研究者が2002年に発表した比較論文がよく知られ、純粋に「仕分ける」精度では識別モデルが有利になりやすいと示されました。ChatGPTのような生成AIが広まるずっと前から、研究者はこの問いと向き合ってきたわけです。
関連用語
識別モデルに関するよくある質問
- 生成モデルとは何が違うのですか?
- 識別モデルは「これは猫か犬か」を見分けることだけに集中するのに対し、生成モデルは「猫の画像とはそもそもどういうものか」までさかのぼって学び、新しい画像まで作れます。見分けるのが識別、作れるのが生成、という対比です。
- 識別モデルにはどんな例がありますか?
- ロジスティック回帰、サポートベクターマシン(SVM)、線形判別分析などが代表例です。スパムメールの判定、不正取引の検知、与信の判定など「仕分ける・見分ける」業務を支えてきました。
- 分類では、生成と識別のどちらが強いのですか?
- 純粋に「仕分ける」精度では識別モデルが有利になりやすいとされます。Andrew NgとMichael Jordanが2002年に発表した比較論文がよく知られ、ChatGPTのような生成AIが広まるずっと前から研究者はこの問いと向き合ってきました。