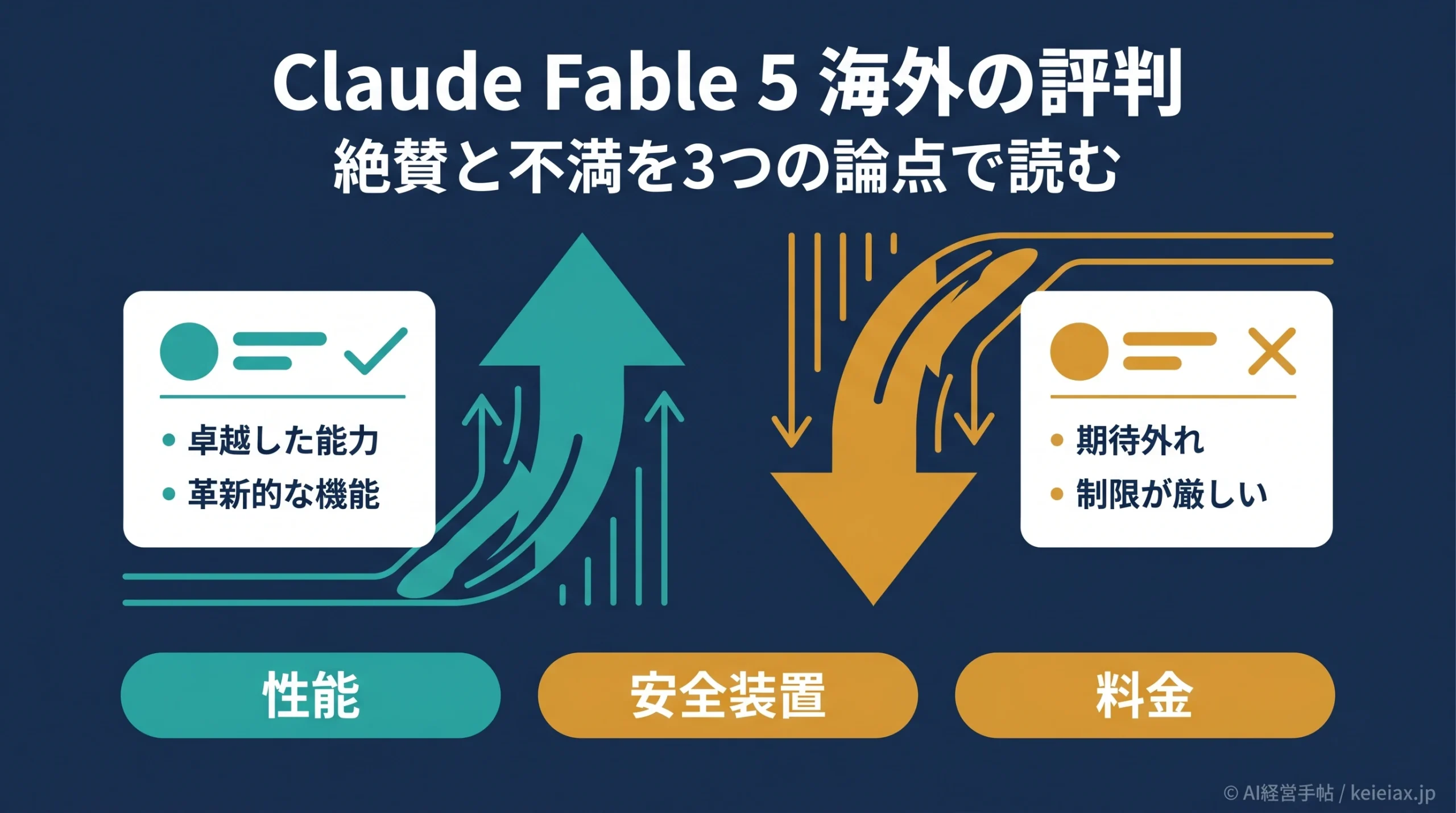
Claude Fable 5に関する海外の反応や評判を調査【Reddit・X等】
新しいClaude Fable 5は、海外で『すごい』と『使えない』の声が同じ日に飛び交っています。
実は評判を3つの論点に分けて読むだけで、自社が今乗り換えるべきか、Opus 4.8で待つべきかが見えてくる、と聞いたら気になりませんか?
Anthropicが2026年6月9日に公開したClaude Fable 5は、これまで一部の組織にしか開かれていなかった最上位クラスのAIを、一般のサブスク利用者が初めて触れる節目になりました。
公開直後から海外の開発者の評価は割れています。
「コーディングは別格」と絶賛する声がある一方で、「拒否が多すぎる」「コストが跳ね上がる」という不満も、同じ日のうちに飛び交いました。
この記事では、海外の生の声を発言者と媒体まで明示して整理しつつ、公式ベンチと独立実測の食い違い、安全装置の誤作動、6月22日で変わる料金という4つの論点を順にたどります。読み終えるころには、自社が今乗り換えるべきか、Opus 4.8で待つべきかを判断できるはずです。
Claude Fable 5とは|「Mythos級」を安全装置つきで一般公開した最上位モデル
Claude Fable 5は、Anthropicが「一般提供する中で最も高性能」と位置づける新しい最上位モデルです。要求の重い推論や、長時間にわたって自律的に作業を続けるエージェント用途を主な狙いとしています。
同時に発表されたClaude Mythos 5とは、中身がまったく同じ。重み(モデルの本体)も能力も価格も同一で、違いは安全装置だけにあります。Mythos 5は安全分類器を外した制限なし版で、政府系のサイバー防衛事業者など審査を通った相手にのみ提供される限定モデル(Project Glasswing)でした。
つまり一般の私たちが今日触れるのはFable 5のほうで、噂されていた高性能モデルに安全装置を付けた公開版にあたります。Fable 5とMythos 5の違いを使い分けまで押さえたい場合は、別記事で整理しました。
スペックと位置づけ(2026年6月時点)
公式ドキュメントで確認できる主な仕様は次のとおり。Opus 4.8の上に新しく置かれたティアで、Opus 4.8は廃止されず併存し、後述するフォールバックの受け皿にもなります。
| 項目 | Claude Fable 5 |
|---|---|
| モデルID | claude-fable-5 |
| コンテキスト | 100万トークン |
| 最大出力 | 12.8万トークン |
| API料金 | 入力$10 / 出力$50 |
| 公開日 | 2026年6月9日 |
コンテキスト100万トークンは、長い資料を何冊分もまとめて読み込ませても覚えていられる広さと考えると実感しやすいでしょう。料金の$10/$50はOpus 4.8(入力$5 / 出力$25)のちょうど2倍で、この単価差が後述の「いつ使うか」の判断に効いてきます。
要点3行でわかる全体像
Fable 5は最上位モデルを安全装置つきで一般公開したもの。
中身はMythos 5と同一で、価格はOpus 4.8の2倍。
性能は本物だが、誰にとっても常用すべき道具とは限らないのが評価の分かれ目です。
新モデルそのものができることを先に押さえたい方は、Claude Fable 5は何ができるのかを入口にすると、この記事の「評判」の話が立体的に読めます。
海外の評判は「3つの論点」で読み解くと整理できる
海外の反応は一見ばらばらに見えますが、論点を3つに分けると一気に整理できます。性能への評価、安全装置への不満、そして料金です。
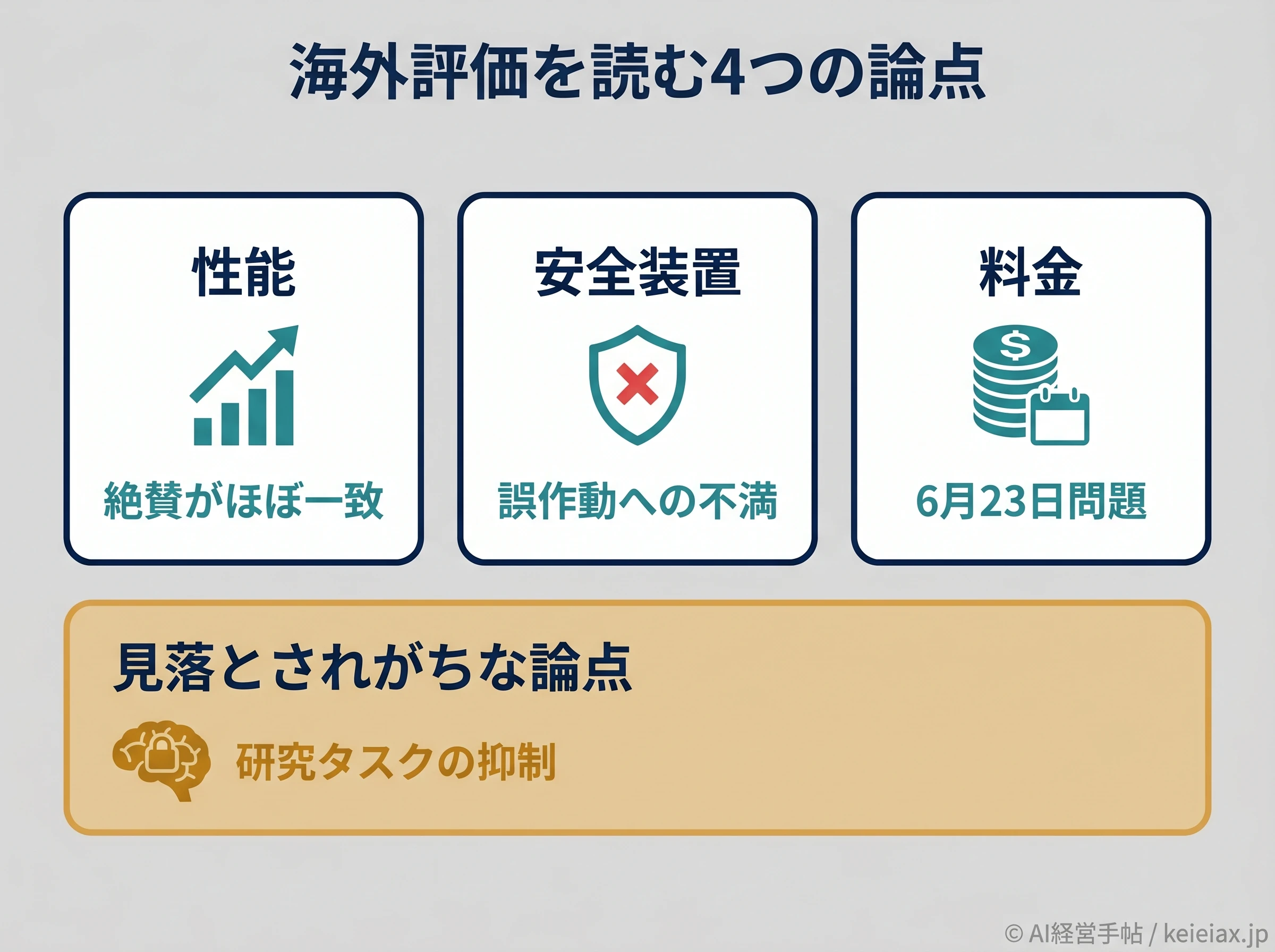
第1に性能。難しいコーディングや長時間の自律タスクでは別格という声が多く、ここはおおむね一致しています。
第2に安全装置で、安全のための分類器が無害な技術作業まで誤って止めてしまうという不満です。
第3に料金。単価の高さに加えて、6月23日から課金の仕組みが変わる点が「客寄せではないか」と疑われました。
さらに見落とされがちなのが、第4の論点とも言える「フロンティアAI開発のタスクで、警告なく性能が抑えられている」という指摘。日本語の解説記事ではほとんど触れられていませんが、海外では研究者を中心に議論になっており、本記事でも後半で正面から扱います。
メモ「絶賛か不満か」の二択で読むと判断を誤ります。
同じ人が、性能は絶賛しつつ料金には怒っているのが実態です。
海外開発者の生の声【発言者・媒体を明示】
ここからは、誰がどこで何を言ったのかを明示しながら見ていきます。「海外で評価が高い」と曖昧にまとめず、発言の出どころまで確認できるようにするのが狙いです。
絶賛|「Opusでは無理だった作業が通った」
AI分野で著名な開発者のSimon Willison氏は、公開直後に約5.5時間かけて検証し、自身のブログでFable 5を「a beast(怪物級)」と評しました。遅くて高価ではあるものの、投げたタスクをほぼ何でも噛み砕いてしまい、「できないことを探すほうが難しい」という手応えだったといいます。
技術系掲示板のHacker Newsでも、コーディングでの具体的な成功報告が並びました。
ある開発者はメモリ割り当てを46倍削減したうえ、Opus 4.8やGPT-5.5が作り込んだ複数のバグまで見つけたと書いています。
別の開発者にいたっては、Opus 4.8では失敗していたデータベース移行が通ったと報告しました。
高評価
難問のコーディング
Opus 4.8が堂々巡りしていた問題を、回り道せず仕上げたという声が複数
長時間の自律作業
「実際のエンジニアのように振る舞う」と評され、自分でテストまで書いて検証する挙動が報告された
不満|拒否・コスト・「6月23日問題」
一方で、不満も具体的でした。最も多かったのは安全装置の誤作動による拒否です。
Hacker Newsでは、社内ツールのデータ収集処理がサイバー脅威と誤判定されて「ばかげている」という声や、健康データのパターン分析が拒否されて使い物にならないという声が上がりました。
MRIの脳画像のセグメンテーション作業が「バイオテロ」と見なされて止められたという報告まであります。
コストへの懸念も切実です。ある開発者は、定額のMaxプランからAPI課金へ切り替えたところ月約200ドルが月約1万ドルに膨らみ、Fableなら月約2万ドル規模になると試算しました。セッション開始から30分で利用上限に達し、実質使えないとこぼす利用者もいます。
そして「6月23日問題」。6月22日まではサブスクに含まれて追加課金なしで使えますが、6月23日からは使用クレジットを消費する仕組みに変わります。この「いったん無料で配り、すぐ有料に切り替える」流れを、Hacker Newsでは「客寄せではないか」と読む向きが少なくありませんでした。料金の詳細は後半で改めて整理します。
著名な評価|「普段使いの道具ではない」
ニュースレターを運営するEveryのダン・シッパー氏の評価は、示唆に富みます。同氏はFable 5を「数時間で銀河を渡れる乗り物」に例えつつ、「街中の移動には向かない。もっと速くて安くて小回りの利くものが要る」と述べました。
性能は本物でも、日常の細かい仕事に常用する道具ではない、という見立て。この「使いどころを選ぶ」という温度感は、絶賛側も不満側もおおむね共有しているように見えます。
公式ベンチと独立実測|数字はどこまで信用できるか
評判を裏づけるベンチマークも出そろいました。ただし数字の出どころを分けて読まないと判断を誤ります。公式が自ら測った値と、第三者が独立に測った値とでは、性格が違うからです。
Anthropic公式ベンチマークの比較
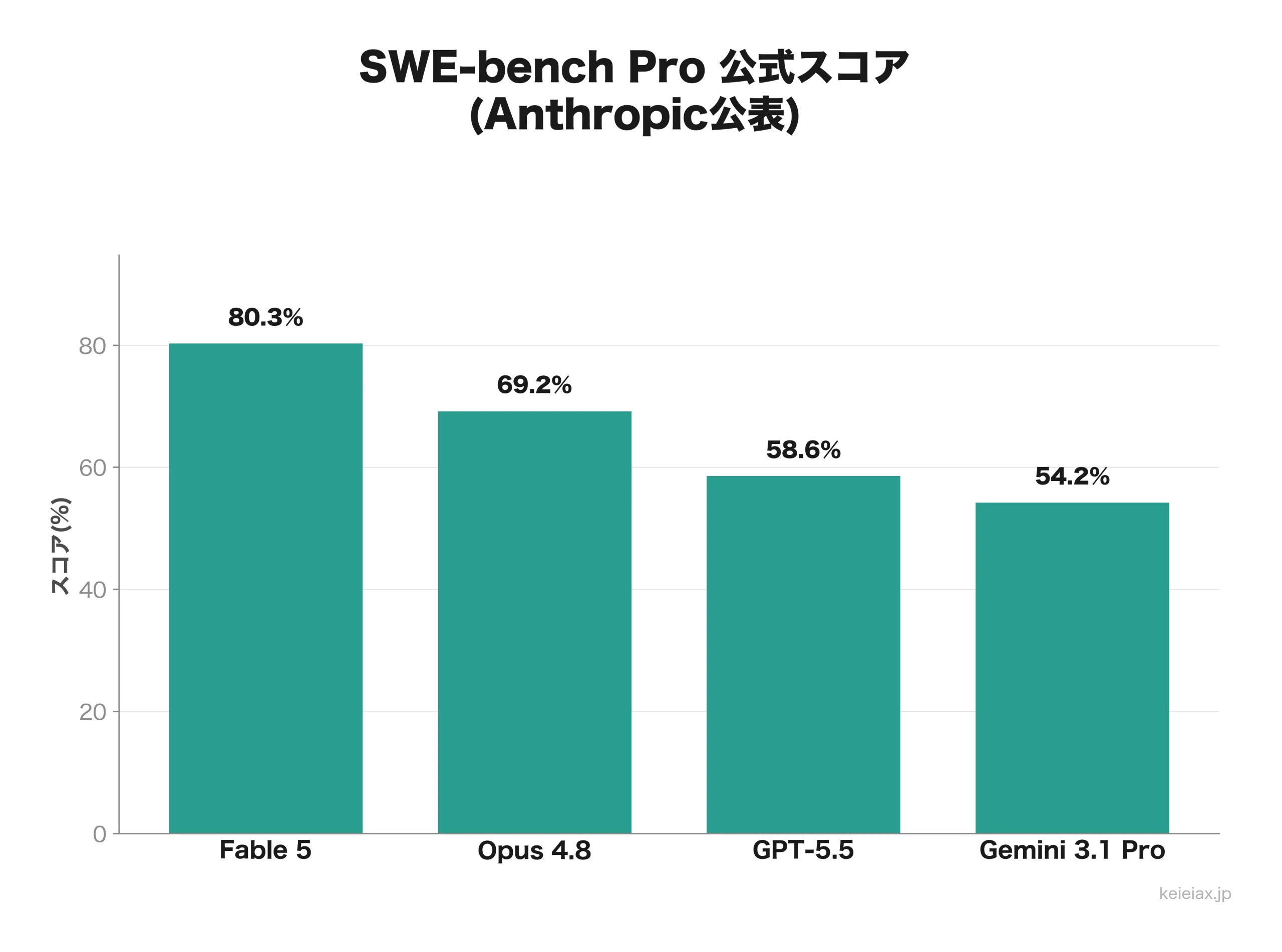
まずAnthropicが公表したベンチマーク。いずれも公式の自己計測で、第三者検証ではない点を踏まえて見てください。エージェント的なコーディング力を測るSWE-bench Proでは、Fable 5がOpus 4.8を11ポイント以上引き離しました。
| ベンチ | Fable 5 | Opus 4.8 |
|---|---|---|
| SWE-bench Pro | 80.3% | 69.2% |
| Terminal-Bench 2.1 | 88.0% | 82.7% |
| FrontierCode | 29.3% | 13.4% |
他社モデルを並べると、SWE-bench ProはGPT-5.5が58.6%、Gemini 3.1 Proが54.2%で、Fable 5の80.3%とは差が開いています。興味深いことに、Fable 5とOpus 4.8の差(11ポイント超)が、Opus 4.8とGemini 3.1 Proの差より大きいという構図でした。
独立実測|第三者が測ると
独立した計測でも、方向性は一致しています。Everyのチームが自社の最難関コーディング試験で測ったところ、Fable 5は100点満点で91点、Opus 4.8は63点、GPT-5.5は62点という結果。
分析企業のHexも、複雑で長時間の分析タスクのベンチでFable 5が初めて90%を突破したと報告しています。
数字を読むときの3つの注意
ベンチマークを鵜呑みにしないために、押さえておきたい点が3つあります。
- 公式値は第三者検証ではない。独立実測(Every・Hex)で裏が取れる範囲を重視する
- ベンチは大型・難問タスクに偏りがち。日常の軽作業の差は数字ほど開かない
- 指標によって順位が入れ替わる。Terminal-BenchではGPT-5.5(83.4%)がOpus 4.8(82.7%)を上回る
私たちの見立てとしては、ベンチの順位よりも「自分の典型タスクで実測する」ほうが、乗り換え判断には確実です。新旧モデルの位置づけを整理したい場合は、Fable 5とOpus・Sonnetの違いもあわせて読むと、どのモデルをどこに置くかが見えてきます。
セーフガードの誤作動とフォールバック|どこで起き、どう回避するか
海外で最大の不満になっている安全装置も、仕組みを知ると回避の余地が見えてきます。やみくもに恐れる必要はありません。
対象は3領域、起きるとOpus 4.8が肩代わりする
Fable 5には安全分類器が組み込まれており、サイバーセキュリティ、生物・化学、蒸留(モデルの能力を抜き取る行為)の3領域に関わる要求を拾います。該当すると、その応答は次に高性能なOpus 4.8が肩代わりして返す仕組み。これがフォールバック(別のモデルに処理を引き継がせる仕組み)と呼ばれるものです。
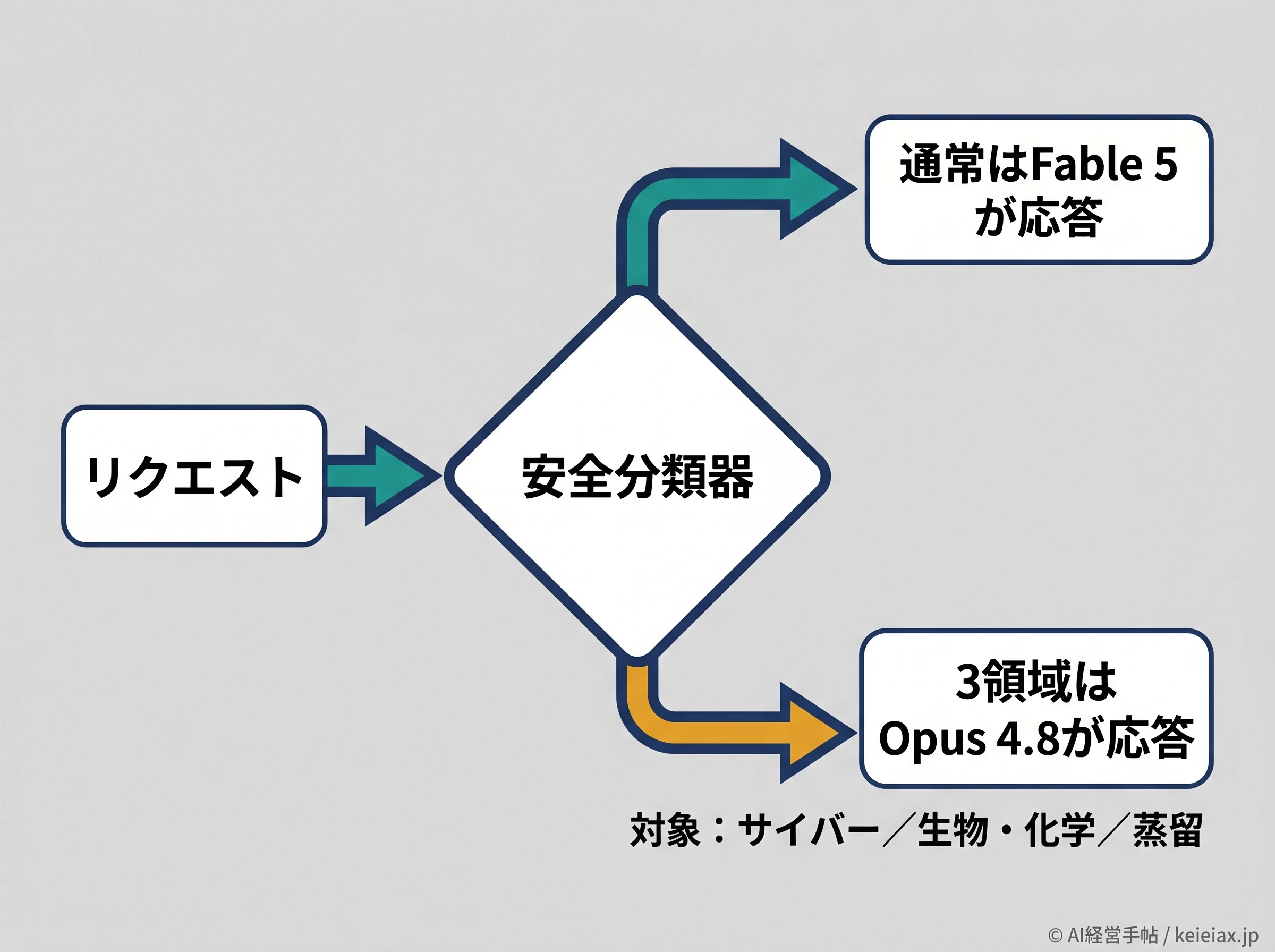
やっかいなのは、この分類器が安全側へ厳しく振られているため、無害な技術作業まで巻き込んで止めてしまうこと。前述の社内ツールや医療データ、MRI画像の事例は、まさにこの誤作動にあたります。
注意誤作動が起きやすい業務
セキュリティ診断・脆弱性調査、医療やバイオの研究データ処理、機械学習基盤の設計といった規制に隣接する技術業務は、無害な内容でも止まる可能性があります。本番運用の前に必ずテストしてください。
95%超は誤作動なし、ただしAPIは自動で肩代わりしない
不安をあおる前に事実を押さえておきましょう。AnthropicはFableセッションの95%超ではフォールバックが一切起きないと説明しています。その場合、Fable 5の性能は制限なし版のMythos 5と実質同じ。大半の業務では誤作動を気にしすぎなくてよい、というのが出発点になります。
ただし運用上の落とし穴があります。APIを直接使う場合、拒否されても自動ではOpus 4.8に切り替わりません。Claude Codeやアプリ上では自動で肩代わりされるのに対し、API経由では拒否がそのまま返ってくるのです。
自社のプロダクトにAPIで組み込むなら、フォールバックを明示的に設定しておくのが安全。
拒否時に別モデルへ自動で再試行させる設定を入れておけば、エンドユーザーに拒否文がそのまま出る事故を防げます。
「研究タスクで静かに性能が落ちる」公式が認める見えない介入
もう一つ、見過ごせない論点があります。Anthropic自身のSystem Card(技術資料)に、フロンティアAI開発に関わる要求(事前学習の仕組みづくりや機械学習基盤の設計など)では、利用者に見えない形で介入し、別モデルへのフォールバックもしないと明記されています。手法としては、プロンプトの書き換えやモデル内部の調整(steering vectors・PEFT)が挙げられました。
前述の3領域の安全装置が目に見える拒否として現れるのに対し、こちらは利用者に気づかせない形で効くとされる点が問題視されています。一部の研究者は、この不透明さを理由にFableの利用をやめると公言しました。
警告公式が認める、見えない介入
この介入はAnthropic公式のSystem Cardで確認できる事実です。Anthropicは安全上の措置として位置づけていますが、AI研究や機械学習基盤に関わる業務であれば、成果物を人手で検証し、単一モデルに依存しない構えが安全です。
料金と「6月22日問題」|いま試すべきか
料金は乗り換え判断の中心です。ここでは事実だけを正確に押さえます。
API料金は入力が100万トークンあたり$10、出力が$50で、Opus 4.8の2倍。円に換算すると入力で約1,550円、出力で約7,750円が目安になります(為替で変動)。トークンとはAIが読み書きする文字のかたまりの単位で、長文や長い対話ほど消費が増える点も押さえておきたいところです。
サブスクでの利用条件(2026年6月時点)
| 期間 | サブスクでの扱い |
|---|---|
| 6月9日〜22日 | 追加課金なしで利用可 |
| 6月23日〜 | 使用クレジットを消費 |
Pro・Max・Team・Enterpriseの各プランで、6月22日までは追加課金なしでFable 5を使えます。6月23日からは使用クレジットを消費する形に変わり、API料金($10/$50)の水準で課金されていく流れ。Anthropicは容量が許せばこの無料の窓を延ばし、将来はサブスク標準に戻したいとしているものの、その時期は公式に発表されていません。
メモ円換算は約1ドル155円(2026年6月時点)で計算した目安です。サブスク利用者にとって、いまが最も安く本気で試せる窓といえます。
背景として、Anthropicの収益化の動きを重ねて読む見方もあります。料金や契約の変化に備える観点はAnthropicのIPO申請から見直すべき判断軸で、Opus 4.8側の最新動向はClaude Opus 4.8アップデートまとめで、それぞれ整理しています。
結論|あなたは乗り換えるべきか、Opus 4.8で十分か
ここまでの事実を、経営判断に落とし込みます。乗り換えるかどうかは、自社の中心業務がどちらに寄っているかで決まります。
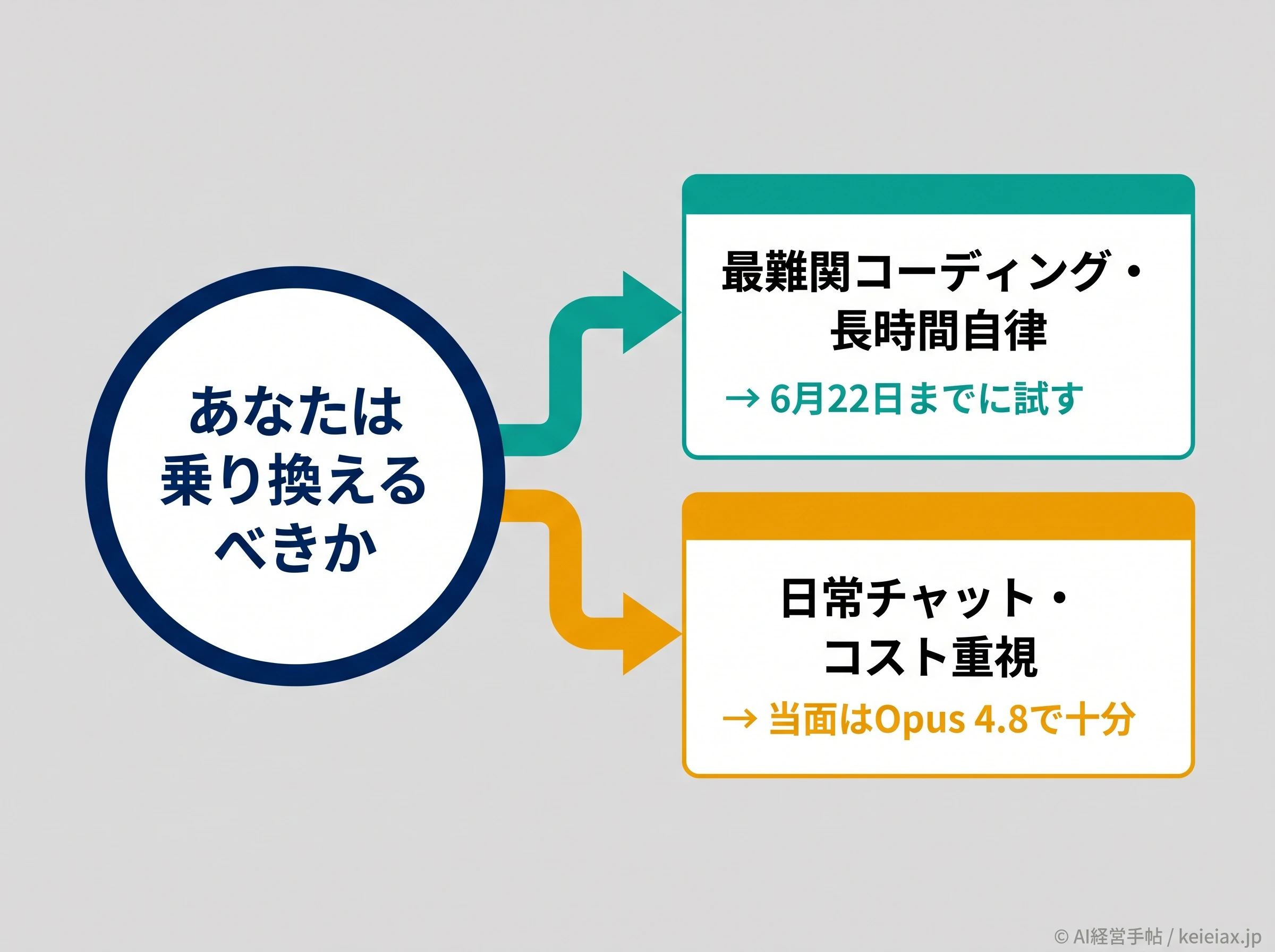
最難関のコーディングや、長時間にわたる自律的なエージェント運用が業務の核なら、6月22日までに自社の本気タスクで試す価値が高いでしょう。ベンチでも生の声でも、ここでの優位は一貫していました。
反対に、日常のチャットや軽いコード補助が中心でコスト感度が高いなら、当面はOpus 4.8で十分というのが海外と国内の実務者に共通する見立て。単価は2倍で、6月23日以降はクレジットを消費する点も忘れずに。
GPT-5.5やGemini 3.1 Proで待つ判断も、十分あり得ます。Terminal-BenchのようにGPTがOpusを上回る指標もあるため、自社の用途次第では他社待ちが合理的なケースもあるでしょう。
6月22日までに確かめておきたいこと
無料の窓を「なんとなく触る」で終わらせないために、次の観点で実測しておくと、6月23日以降の方針を落ち着いて決められます。
- 自社で最も難しい実タスクを流し、Opus 4.8と仕上がりを並べて比べる
- 規制に隣接する業務で、安全装置の誤作動が起きないかを確認する
- 同じ作業のトークン消費を記録し、6月23日以降の概算コストを見積もる
- APIで使うなら、拒否時のフォールバック設定を入れて挙動を確かめる
最後に、日本語圏の状況にも触れておきます。公開直後の今は日本語の情報がまだ速報の段階にあり、独自の実測はこれからという空気。海外ではすでに実測レビューが積み上がっているため、この時間差は、先回りで検証に着手する好機でもあります。自社の主要業務をどのモデルに任せるかを整理したい場合は、生成AIは会社でどれを選ぶべきかが使い分けの土台になるはずです。
料金やデータ保持(Fable 5は30日間の保持が必須で、ゼロ保持は選べません)を含めて社内で詰める段になり、判断軸の整理でお困りであれば、遠慮なくご相談ください。
出典: Anthropic公式「Claude Fable 5 and Claude Mythos 5」(英語)
出典: Anthropic公式ドキュメント「Introducing Claude Fable 5 and Claude Mythos 5」(英語)
出典: AnthropicのClaude Fable 5 System Card(公式PDF・英語)
よくある質問
QClaude Fable 5の海外の評判は良いのか悪いのか?
A性能面は海外の開発者から高く評価され、著名な開発者のSimon Willison氏は「beast(怪物級)で、できないことを探すほうが難しい」と評しています。一方で2倍の単価、安全装置の誤作動、6月23日からの課金移行への不満も強く、評価は二極化しています。
QClaude Fable 5は本当にOpus 4.8より優れているのか?
AAnthropic公式ベンチではSWE-bench Proが80.3%でOpus 4.8の69.2%を上回り、独立実測のEveryでも91点対63点と、大型・長時間タスクでは明確に優位です。ただし日常の軽作業では差は小さく、Everyのダン・シッパー氏は「普段使いの道具ではない」と評しています。
QClaude Fable 5の料金はいくらで、無料で使えるのか?
AAPI料金は入力が100万トークンあたり$10、出力が$50で、Opus 4.8の2倍です。Pro・Max・Team・Enterpriseのサブスクなら2026年6月9日から22日までは追加課金なしで使え、6月23日以降は使用クレジットを消費します。
Qセーフガードの誤作動はどんなときに起き、回避できるのか?
Aサイバーセキュリティ・生物/化学・蒸留に関わる要求を安全分類器が拾い、Opus 4.8が代わりに応答します。社内ツールや医療データ処理が誤って止まった報告がありますが、Anthropicによれば誤作動が起きるのは全セッションの5%未満です。APIでは自動で切り替わらないため、フォールバックの明示設定が回避策になります。
QClaude Fable 5とMythos 5は何が違うのか?
A中身は同一のモデルで、重みも能力も価格も同じです。Fable 5は安全分類器つきの一般公開版、Mythos 5は分類器を外した限定版で、政府系のサイバー防衛事業者など審査を通った相手にのみ提供されます。
QいまClaude Fable 5に乗り換えるべきか、待つべきか?
A最難関のコーディングや長時間の自律タスクが中心なら、6月22日までに自社の本気タスクで試す価値があります。日常用途やコスト重視なら、当面はOpus 4.8で十分というのが海外と国内の実務者に共通する見立てです。
QClaude Fable 5はどこで使えるのか?
AClaude API、AWS、Amazon Bedrock、Google Vertex AI、Microsoft Foundryで一般提供され、GitHub Copilotでも利用できます。いずれも2026年6月9日に提供が始まりました。
Q「AI研究でわざと性能を落としている」という噂は本当か?
AAnthropicの公式System Card(技術資料)に、フロンティアAI開発のタスク向けには利用者に見えない介入があり、別モデルにもフォールバックしないと明記されています(手法はプロンプト改変・steering vectors・PEFT)。噂レベルの話ではなく公式資料で確認できますが、Anthropicは安全上の措置として位置づけています。研究用途では成果物の人手検証と複数モデルの併用が安全です。