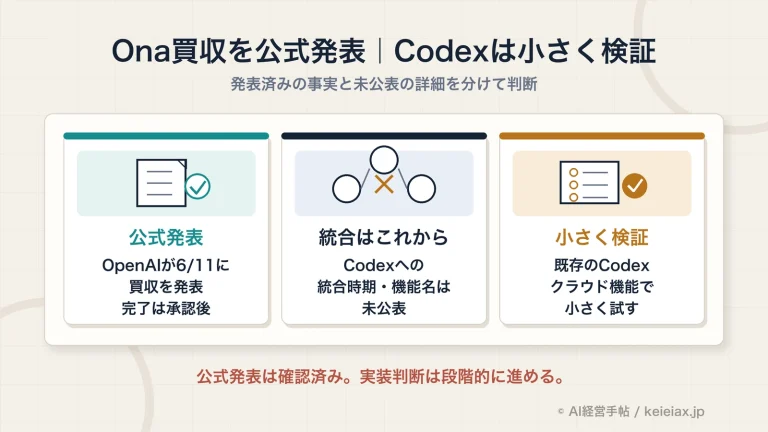
Humanity's Last Examとは
Humanity’s Last Examとは、人類の専門知識の最前線から集めた問題で、AI(大規模言語モデル)の学力を測るベンチマーク(AI向けの共通試験のようなもの)です。日本語では「人類最後の試験」と訳され、略称はHLE。AIの安全性を研究する非営利団体Center for AI Safety(CAIS)とAI企業のScale AIが、2025年1月に公開しました。
なぜ「最後の試験」という名前なのか
背景にあるのは、既存のAI向け試験が「満点近く」になり、差を測れなくなったことです。代表的な知識試験MMLUでは、2025年頃までに上位モデルの正答率が90%を超えました。テストで全員が満点を取るようになったら、もう実力差は分かりません。これがベンチマークの「飽和」と呼ばれる現象です。
そこでHLEは、人類の専門知識の限界線に近い問題だけを集めました。各問題は「答えが明確に定まっていて、しかもインターネット検索では即答できない」ことが条件。学術的な知識試験としては最終級を狙った設計であり、それがこの大胆な名前の由来になっています。
2,500問を、50カ国1,000人の専門家がつくった
中身は2,500問・100以上の科目で、数学から人文科学、自然科学まで広くカバーします。図や画像を読ませる問題も含むマルチモーダル形式(文章と画像の両方を扱う形式)です。作問には50カ国以上・500を超える大学や研究機関の約1,000人の専門家(教授・研究者・大学院生)が参加しました。
公開された2025年1月の時点では、最先端のAIモデルでも正答率は低く、専門家レベルの知識との間に大きな差があることが示されました。AIの進歩は速いため、この差がどう縮まるかが定点観測の対象になっています。スコアを引き合いに出すときは、いつ時点の数字かを確かめるのが肝心でしょう。
Topic良い問題には賞金、1問あたり約5,000ドル
HLEの問題は、世界中の専門家からの公募で集められました。面白いのはその集め方で、総額約50万ドルの賞金プールが用意され、評価の高かった上位50問には各約5,000ドル、続く500問にも各約500ドルが支払われています。「AIがまだ解けない問題」そのものに値段が付いた、というわけです。試験問題の懸賞コンペという発想自体が、AIの実力が人間の専門家に迫った時代を象徴しているかもしれません。
Humanity's Last Examに関するよくある質問
- 本当に「人類最後」の試験なのですか?
- 学術的な知識試験としては最終級を狙った命名で、AIの能力すべてを測るものではありません。創造性や、顧客対応のような実務を完遂する力は対象外です。エージェントの実務遂行力はτ-benchなど別のベンチマークで測ります。
- HLEのスコアが高いAIなら、調べ物を任せても安全ですか?
- そうとは限りません。HLEは検索で即答できない専門知識を測る試験で、日常の調べ物の正確さやハルシネーション(もっともらしい誤答)の少なさを直接保証するものではありません。用途に合わせた別の検証が必要です。
- 経営者がこのベンチマークを見る意味はありますか?
- AIモデルの学術知識の到達度を比べる参考にはなりますが、自社業務での精度を保証するものではありません。ベンダー選定では、自社の用途に近いベンチマークや実データでの検証と組み合わせて判断するのが安全です。